hadoop配置分区
1.运行MR,得出HDFS路径下数据
2.创建 Hive 表 映射 HDFS下的数据
3.为数据创建分区,在hive下执行 source 分区表;
TIPS:结果集的时间,必须在分区范围内;
可以理解一下:hive sql 是在创建表以及结果的时候分区;
MR运行结果,必须额外分区;额外分区的话,就是mr,MR每天跑数据,自行插入到分区;
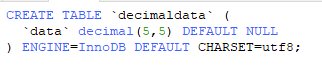
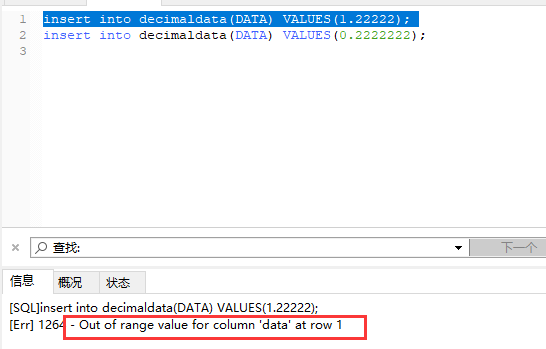
此外,Hive 对数据的定义类型 有很大关系,如果数据格式超出范围,则数据显示为null;例如:
yield_rate decimal(10, 10) ; 此时,如果计算出来的数据为2.22,则该数据无法传入,因为数据”不规范“,原因是结果字段要去传入 10位小数的数据 ,但是该数据不符合"规则",故无法传入。
本文版权归作者所有,转载请注明出处http://www.cnblogs.com/iloverain/.未经作者同意必须保留此段声明,否则保留追究法律责任的权利.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号