学习笔记——关于学习率、权值保存加载
首先感谢网上的诸位大佬写的博客,让我能够较快的获取到所需要的知识!
深度学习相关————学习笔记(1)
关于学习率(lr)调整的问题
#首先进行模型的定义
model = XXNet()
#学习率(learing rate)
lr = 1e-4
#优化器(optimizer)
optimizer = torch.optim.Aadm(model.parameters(),lr)
#torch.optim.lr_scheduler 提供了使得学习率(lr)能够随着训练的代数变化而变化的几种方法
#1.StepLR : 每经过step_size个epoch,做一次更新
lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.95)
#2.LambdaLR : new_lr=λ×initial_lr;
# initial_lr 是初始的学习率,λ是通过参数lr_lambda(function or list)和epoch得到的。
lr_scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
#3.MultiStepLR :
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
#4.CosineAnnealingLR
lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
参数:last_epoch=-1
last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。
默认为-1表示从头开始训练,即从epoch=1开始。
note:
在将optimizer传给scheduler后,在shcduler类的__init__方法中会给optimizer.param_groups列表中的那个元素(字典)增加一个key = "initial_lr"的元素表示初始学习率,等于optimizer.defaults['lr']。
param_groups:Optimizer类在实例化时会在构造函数中创建一个param_groups列表,列表中有num_groups个长度为6的param_group字典(num_groups取决于你定义optimizer时传入了几组参数),每个param_group包含了 ['params', 'lr', 'momentum', 'dampening', 'weight_decay', 'nesterov'] 这6组键值对。
于是就可以通过
optimizer.param_groups[0]['lr']
得到当前的学习率。
对于StepLR :
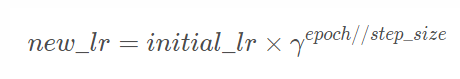
其中new_lr是得到的新的学习率,initial_lr是初始的学习率,step_size是参数step_size,γ 是参数gamma。
eg:
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.95, last_epoch=-1)
对于MultiStepLR:
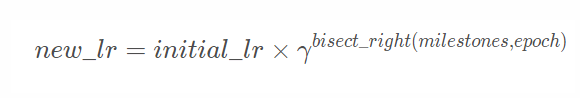
其中new_lr是得到的新的学习率,initial_lr是初始的学习率,γ 是参数gamma,bisect_right(milestones,epoch)就是bisect模块中的bisect_right函数,返回值是把epoch插入排序好的列表milestones式的位置。
eg:
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[round(config['training']['epochs'] * x) for x in [0.8, 0.9]])
对于CosineAnnealingLR

其中new_lr是得到的新的学习率,initial_lr是初始的学习率,eta_min是参数eta_min表示最小学习率,T_max是参数T_max表示cos的周期的1/4。
效果如下图所示:

#训练模板:
for epoch in range(0,epochs):
train()
val()
lr_scheduler.step() #调整
def train():
net.train()
for i, (image, label) in enumerate(train_dataloader):
if cuda:
image = image.cuda()
label = label.cuda()
optimizer.zero_grad()#梯度归零
output = net(image)
loss = Loss(outputs, label)
loss.backward()#反向传播计算得到的每个参数的梯度值
optimizer.step()#通过梯度下降执行一步参数更新
......
def val():
net.eval()
for i, (image, label) in enumerate(val_dataloader):
if cuda:
image = image.cuda()
label = label.cuda()
loss = Loss()
output = net(image)
loss = Loss(outputs, label)
......
with torch.no_grad()
torch.no_grad() 是一个上下文管理器,被该语句 wrap (包)起来的部分将不会track 梯度。但是计算依旧正常计算。
权值文件保存问题
[pytorch官方教程](([Saving and Loading Models — PyTorch Tutorials 1.9.0+cu102 documentation)(https://pytorch.org/tutorials/beginner/saving_loading_models.html))
torch.save()
保存:
torch.save(state, filename)
#state 是一个字典 {}
#filename 是存储地址,可以是绝对路径也可以是相对路径 'xxx.pth'
eg:
torch.save({
'epoch':epoch,
'model_state_dict':model.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'best_pred':new_pred,
},filename)
#保存最新模型与最佳模型
def save_checkpoint(self, state, is_best, filename='checkpoint.pth.tar'):
filename = os.path.join(path, filename)
torch.save(state, filename) #保存最新模型
with open(os.path.join(path, 'best_pred.txt'), 'w') as f:
f.write(str(best_pred)) #记录最佳指标
if is_best:
best_pred = state['best_pred'] #在分割里 这个可以是mIoU
copy_filename = os.path.join(path, "copy/", str(state['epoch']) + 'checkpoint_best.pth.tar')
torch.save(state, copy_filename)
#或者
if is_best:
shutil.copyfile(filename, 'model_best.pth.tar')
torch.load()
加载:
#恢复训练前置条件:
#1. model = net()
#2. optimizer = torch.optim.Adam(model.parameters(),lr)
#3. lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.95)
#接下来:
checkpoint = torch.load(filename)
continue_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
BEST_miou = checkpoint['best_pred']
end_epoch = continue_epoch + 30 #eg
for epoch in range(continue_epoch, end_epoch):
train()
val()
lr_scheduler.step()
需要注意的是:
PyTorch报错:XXX is a zip archive(did you mean to use torch.jit.load()?)
从torch版本1.6.0之后,训练模型的保存都是默认使用zip文件来保存权重文件,这导致这些权重文件无法直接被1.5及以下的pytorch加载。
解决办法:
在PyTorch1.6或更高版本的PyTorch下,运行一下代码,来转换模型
state_dict = torch.load("xxx.pth")
torch.save(state_dict, "xxx.pth", _use_new_zipfile_serialization=False)
对于'xxx.pth.tar' , 加载的时候报这个错误是一样的处理办法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号