【验证码逆向专栏】某多多验证码逆向分析
声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
前言
某多多的验证码,类型有很多,滑块、点选、手势等等,其中点选的题目繁多,每刷一次都能给你整个新的出来。本文主要对验证码的相关加密算法(不同类型的都大差不差)进行逆向分析,识别模型的训练后续也会推出相关文章,上述内容都仅供学习交流:

逆向目标
-
目标:某多多点选验证码逆向分析
-
网站:感兴趣的小伙伴私聊
抓包分析
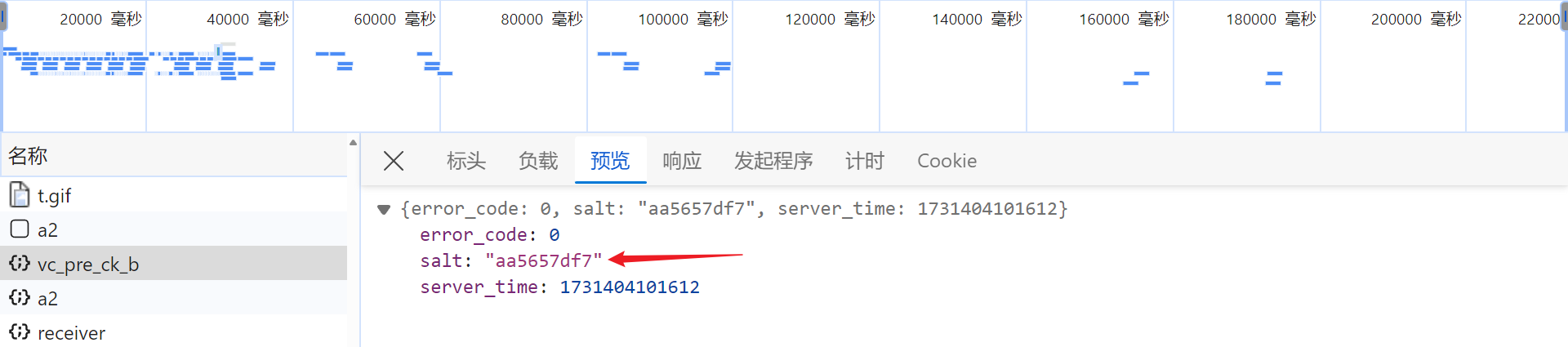
触发验证码,抓包,/api/phantom/vc_pre_ck_b 接口返回的 salt 值,会参与到加密参数的生成:
/api/phantom/obtain_captcha 接口获取验证码图片以及题目内容,都经过了加密处理:
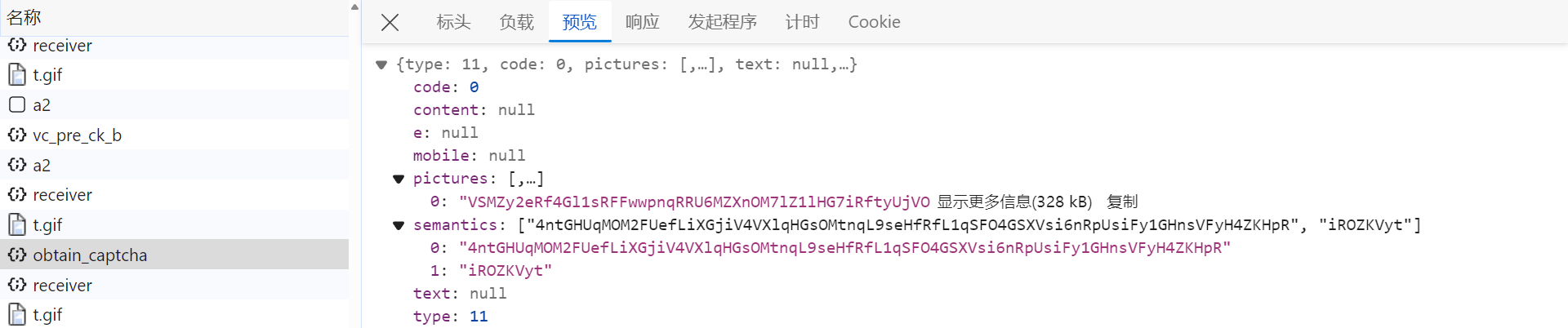
- pictures:验证码背景图片链接;
- semantics:验证码需点击的题目内容。
该接口的请求参数中 anti_content、captcha_collect 都经过了加密,verify_auth_token 是触发验证码之后,返回的识别标志:

/api/phantom/user_verify 验证接口:

- 验证成功:{'code': 0, 'leftover': 9, 'result': True};
- 验证失败:{'code': 3002, 'leftover': 9, 'result': False};
- 验证时间过长:{'code': 1001, 'leftover': null, 'result': False}。
请求参数与 /api/phantom/obtain_captcha 接口基本相同,多了一个 verify_code,也就是点击的坐标:

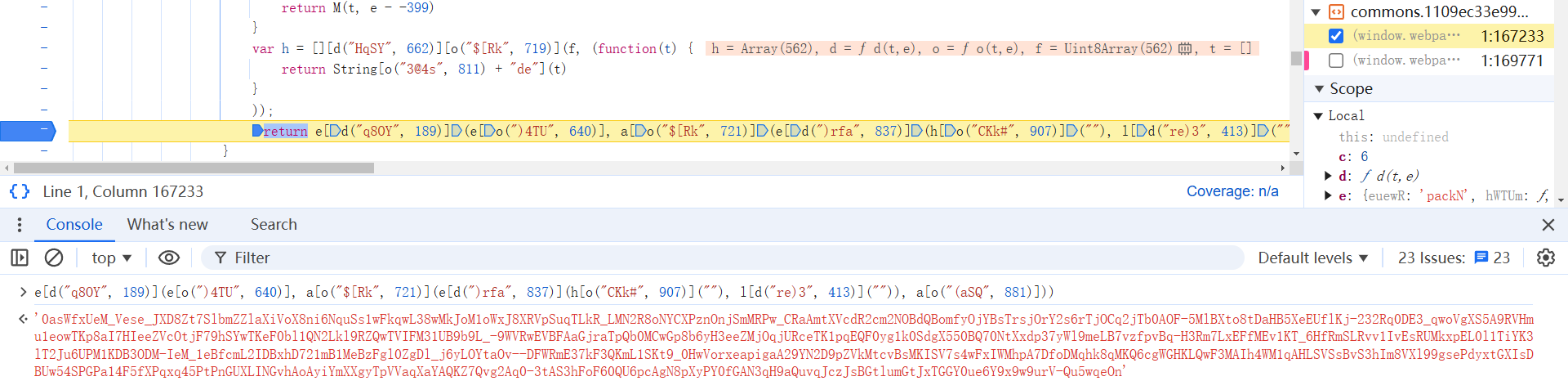
anti_content 参数的解决思路,网上有很多详解文章,跟栈就行了,本文就不对此多加分析了:
逆向分析
验证码图片
一般的验证码,其获取图片的接口,基本都是直接返回的下载链接,或者经过 Base64 编码后的值。本案例中,验证码的背景图片链接、标题都经过了加密处理,需要进行逆向分析。
这些图片内容,在后端进行加密,那必然会在前端解密出真实的链接,然后渲染到页面上,据此,基本就有两种方案。
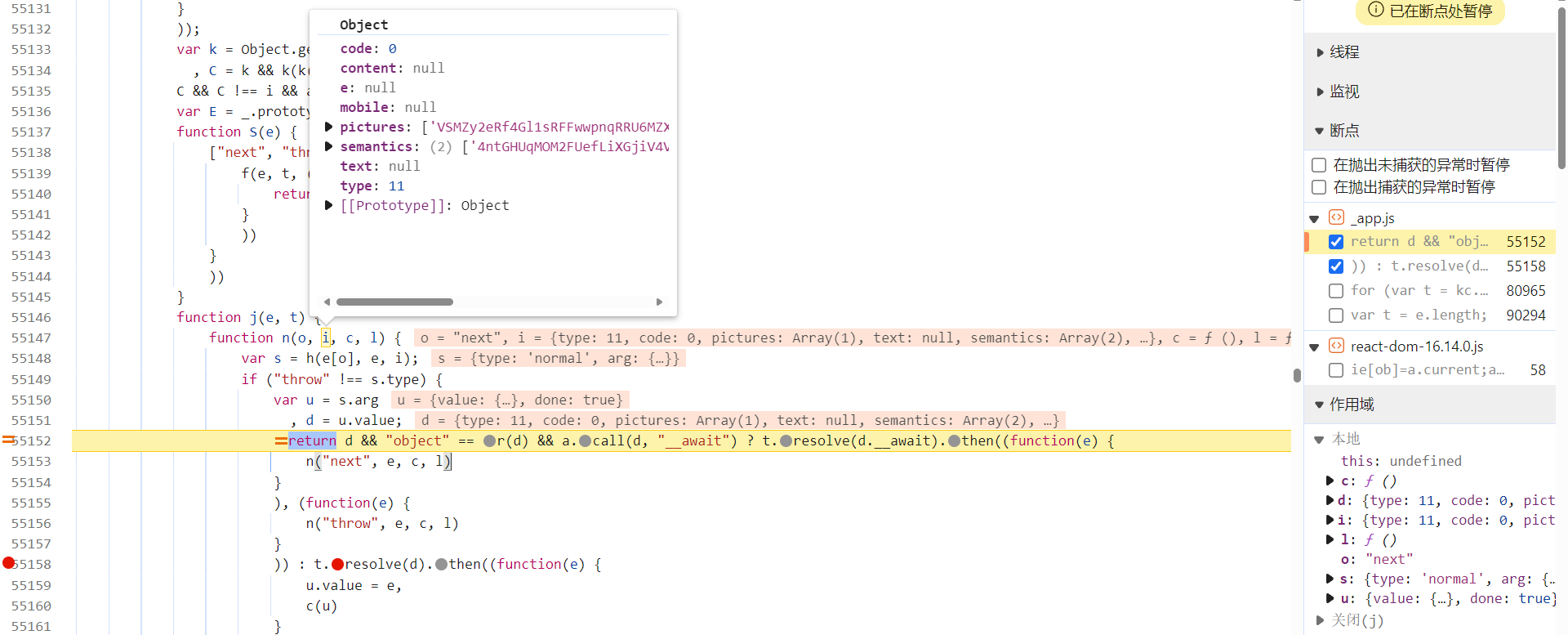
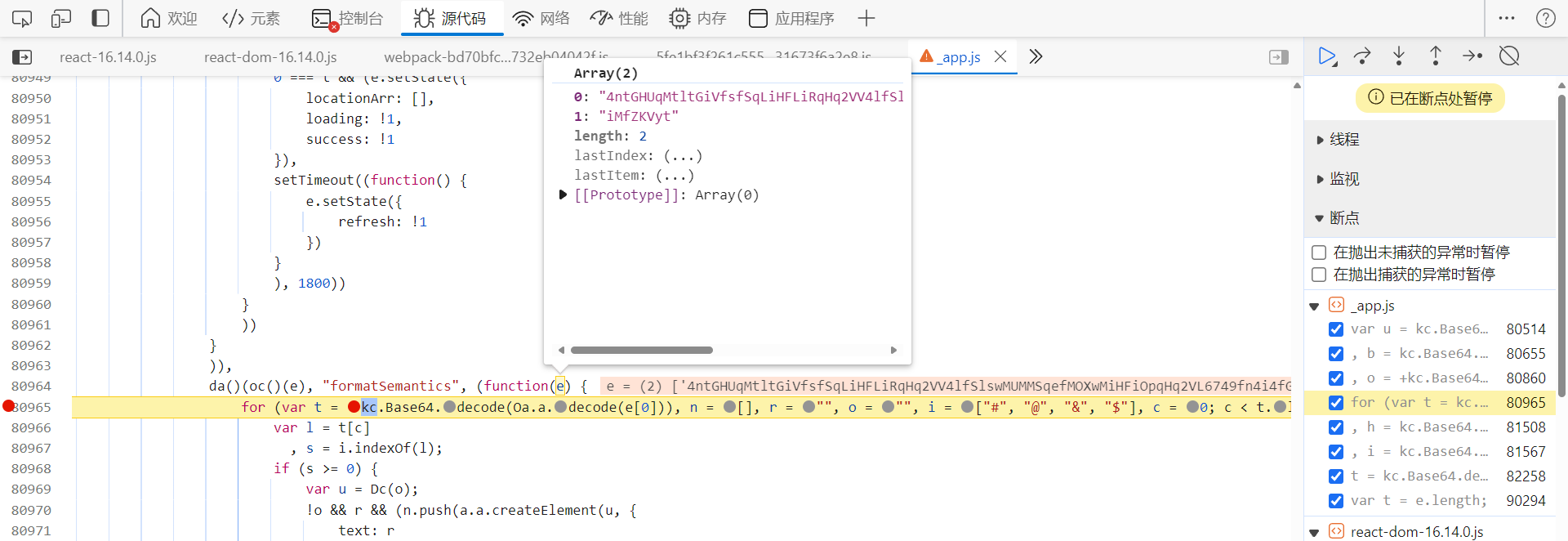
第一种,跟栈分析,/api/phantom/obtain_captcha 接口调用的堆栈基本都在 _app.js 文件中,是异步的,关于异步跟栈的分析流程,之前的文章写过很多,就不再赘述了。跟栈进去,在下图 return 处下个条件断点 i.pictures,返回验证图片相关信息时即会断住:
单步调试,分析,寻找解密点。向上跟栈到此处,可以看到,c 就是经过加密后的标题,经过 this.formatSemantics 方法处理后,还原出了明文标题:
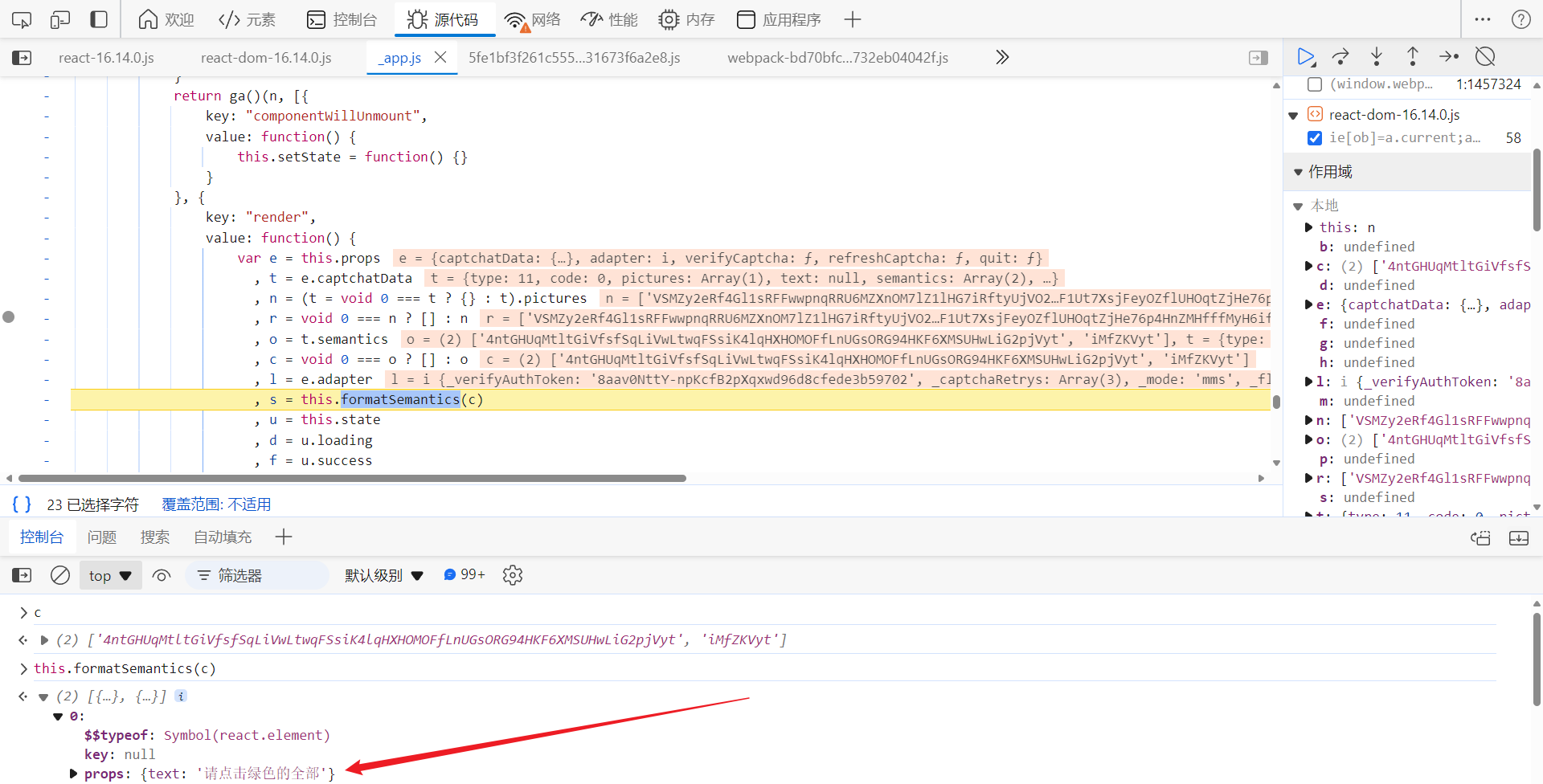
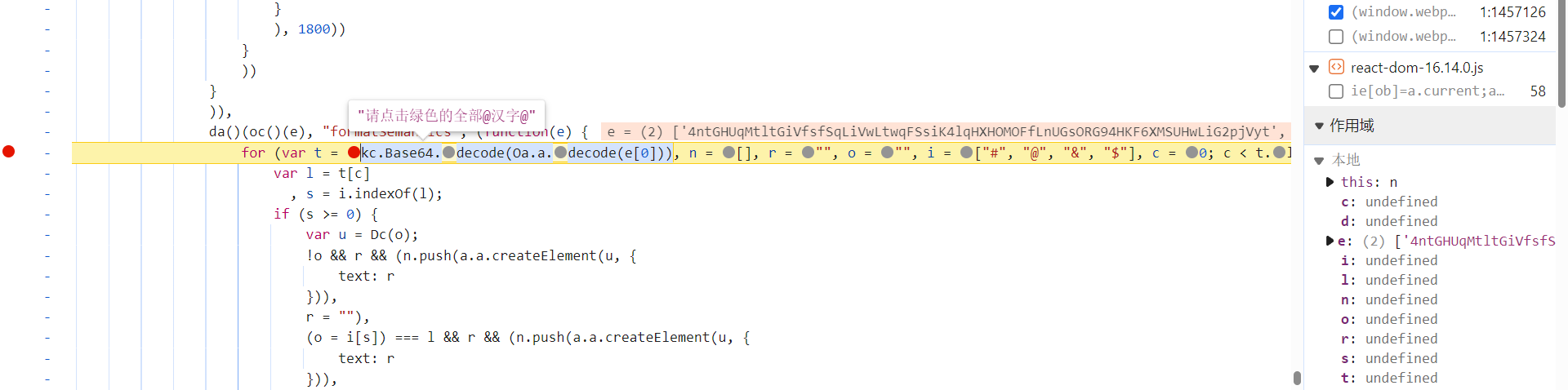
跟到 this.formatSemantics 中去,kc.Base64.decode(Oa.a.decode(e[0])) 方法解密出了明文值,最终的结果替换掉特殊字符 @ 即可:
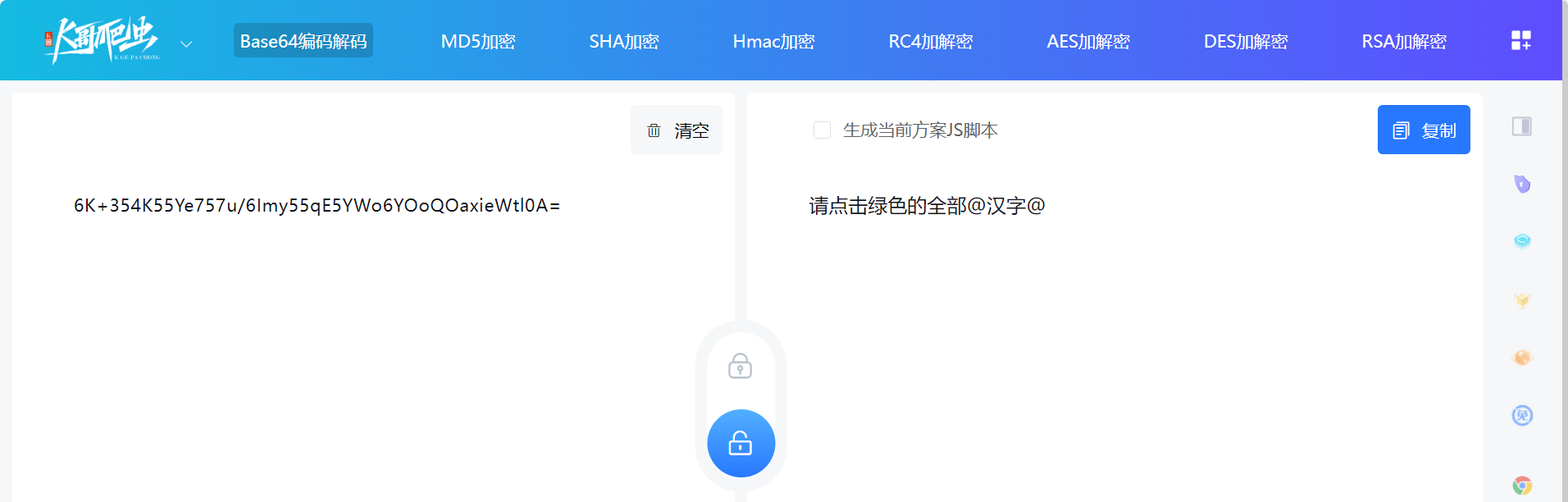
kc.Base64.decode 就是 base64 解码( https://www.kgtools.cn/secret/base64 ):
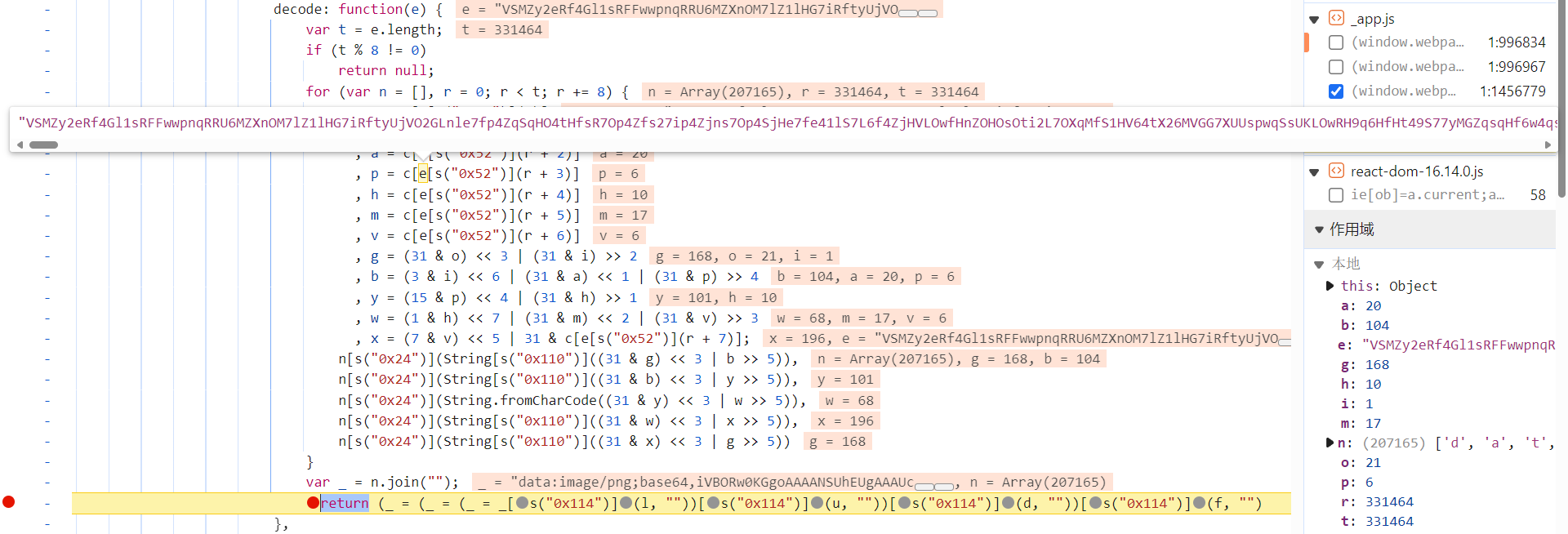
跟进到 Oa.a.decode 中,将相关算法扣下来即可:

Python 复现:
# ======================
# -*-coding: Utf-8 -*-
# ======================
import re
import base64
from loguru import logger
c = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 24, 3, -1, 20, -1, 17, 8, -1, 30,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 12, 22, 10, -1, -1, 15, 14, 6, -1, 5, -1, -1, 7, 18, -1, 25, 9, -1,
28, -1, 2, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 21, -1, 31, 13, 16, -1, 26, -1, 27, -1, 0, 19, -1, 11, 4, -1,
-1, 23, -1, 29, -1, -1, -1, -1, -1, -1]
# 正则表达式, 用于匹配多字节的 UTF-8 字符
b = re.compile(r'[\xC0-\xDF][\x80-\xBF]|[\xE0-\xEF][\x80-\xBF]{2}|[\xF0-\xF7][\x80-\xBF]{3}')
# UTF-8 解码
def y(e):
length = len(e)
if length == 4:
t = ((7 & ord(e[0])) << 18 | (63 & ord(e[1])) << 12 | (63 & ord(e[2])) << 6 | 63 & ord(e[3])) - 65536
return chr(55296 + (t >> 10)) + chr(56320 + (t & 1023))
elif length == 3:
return chr((15 & ord(e[0])) << 12 | (63 & ord(e[1])) << 6 | 63 & ord(e[2]))
else:
return chr((31 & ord(e[0])) << 6 | 63 & ord(e[1]))
def decode_captcha_img(e):
t = len(e)
if t % 8 != 0:
return None
n = []
for r in range(0, t, 8):
o = c[ord(e[r])]
i = c[ord(e[r + 1])]
a = c[ord(e[r + 2])]
p = c[ord(e[r + 3])]
h = c[ord(e[r + 4])]
m = c[ord(e[r + 5])]
v = c[ord(e[r + 6])]
g = (31 & o) << 3 | (31 & i) >> 2
b = (3 & i) << 6 | (31 & a) << 1 | (31 & p) >> 4
y = (15 & p) << 4 | (31 & h) >> 1
w = (1 & h) << 7 | (31 & m) << 2 | (31 & v) >> 3
x = (7 & v) << 5 | 31 & c[ord(e[r + 7])]
n.append(chr((31 & g) << 3 | b >> 5))
n.append(chr((31 & b) << 3 | y >> 5))
n.append(chr((31 & y) << 3 | w >> 5))
n.append(chr((31 & w) << 3 | x >> 5))
n.append(chr((31 & x) << 3 | g >> 5))
_ = ''.join(n)
_ = _.replace('#', '').replace('@?', '').replace('*&%', '').replace('<$|>', '')
return _
# 解码标题
def decode_captcha_title(pic_encode, decode_type=""):
decoded_img = decode_captcha_img(pic_encode)
if decoded_img is None:
return None
if decode_type == "title":
decoded_title_str = base64.b64decode(decoded_img).decode('utf-8')
# 使用正则表达式和 y 函数替换多字节字符
decoded_title_str = b.sub(lambda match: y(match.group(0)), decoded_title_str)
return decoded_title_str
else:
return decoded_img
if __name__ == '__main__':
# 标题测试样例
title_pic = "4ntGHUqMtltGiVfsfSqLiVwLtwqFSsiK4lqHXHOMOFfLnUGsORG94HKF6XMSUHwLiG2pjVyt"
decode_title_result = decode_captcha_title(title_pic, "title")
logger.info(decode_title_result.replace("@", ""))
# 背景图片测试样例
bg_pic = "pictures[0]" # 太长了, 自行替换测试
decode_bg_result = decode_captcha_title(bg_pic)
logger.info(decode_bg_result)
背景图片链接还原比标题少一步解码:
第二种,直接搜索 decode,尝试定位解密算法的位置。跟栈进去后发现,_app.js 文件内容未经过混淆,ctrl + f 搜索一下,把感觉像的地方都打上断点,刷新验证码,断住后,也能找到相关算法的位置:
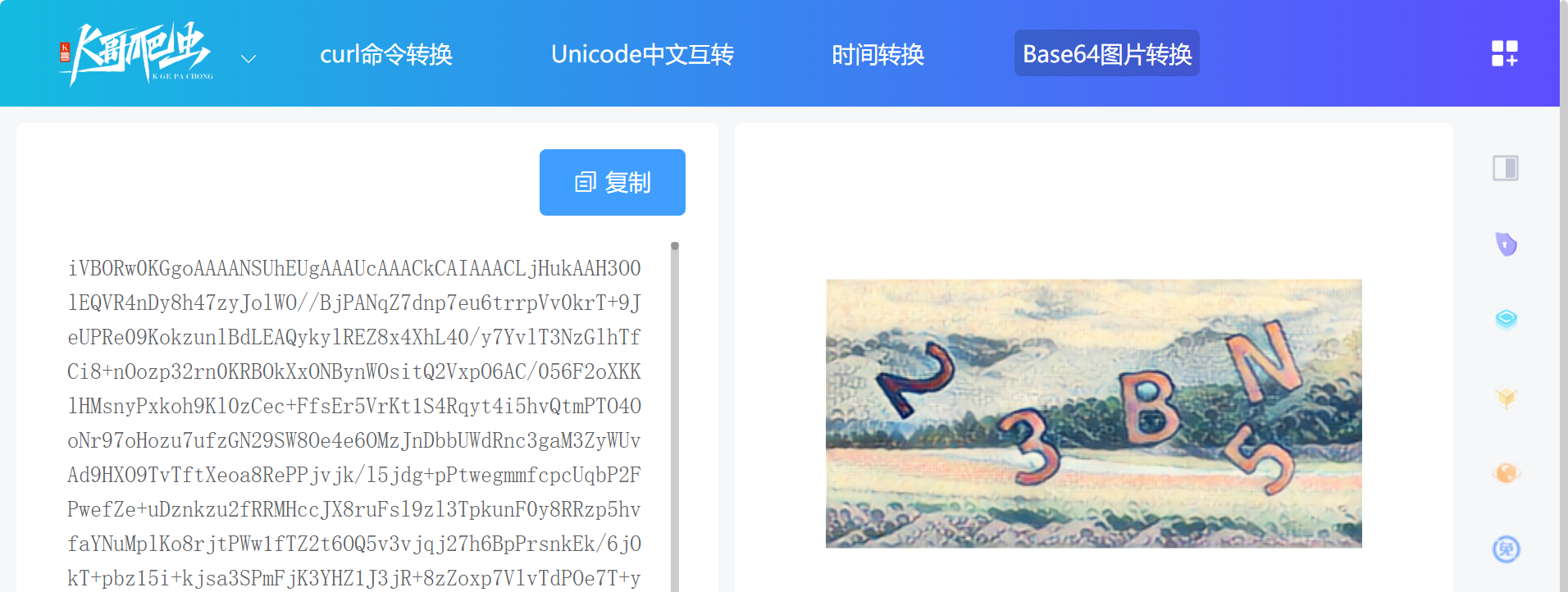
将还原的结果去掉前面的 data:image/png;base64,(标识信息),复制到 K哥工具站( https://www.kgtools.cn/convert/base64img )验证一下,无误:
captcha_collect 参数
总共有两个接口需要 captcha_collect 参数,分别是获取图片的接口 /api/phantom/obtain_captcha 和验证接口 /api/phantom/user_verify,本文将逐一分析。
两个接口,和前文一样,各用一种方案分析。/obtain_captcha 接口的 captcha_collect 参数,跟栈调试,和前文一样,下个条件断点 i.includes('0as'),在 anti_content 参数生成之后,图片结果响应返回之前,单步往下调试:
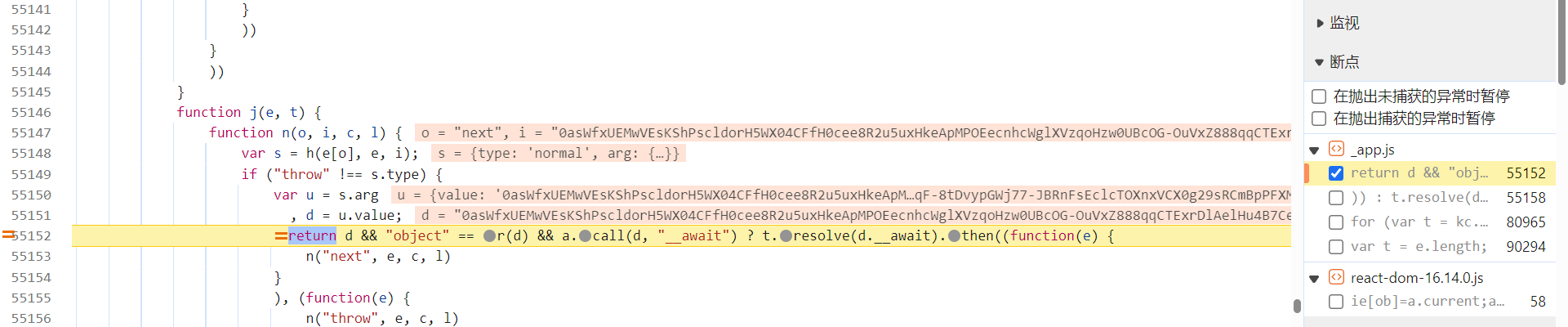
跟到下图处会发现,此时的 captcha_collect 参数是由 Oa.a.getPrepareToken() 参数生成的:
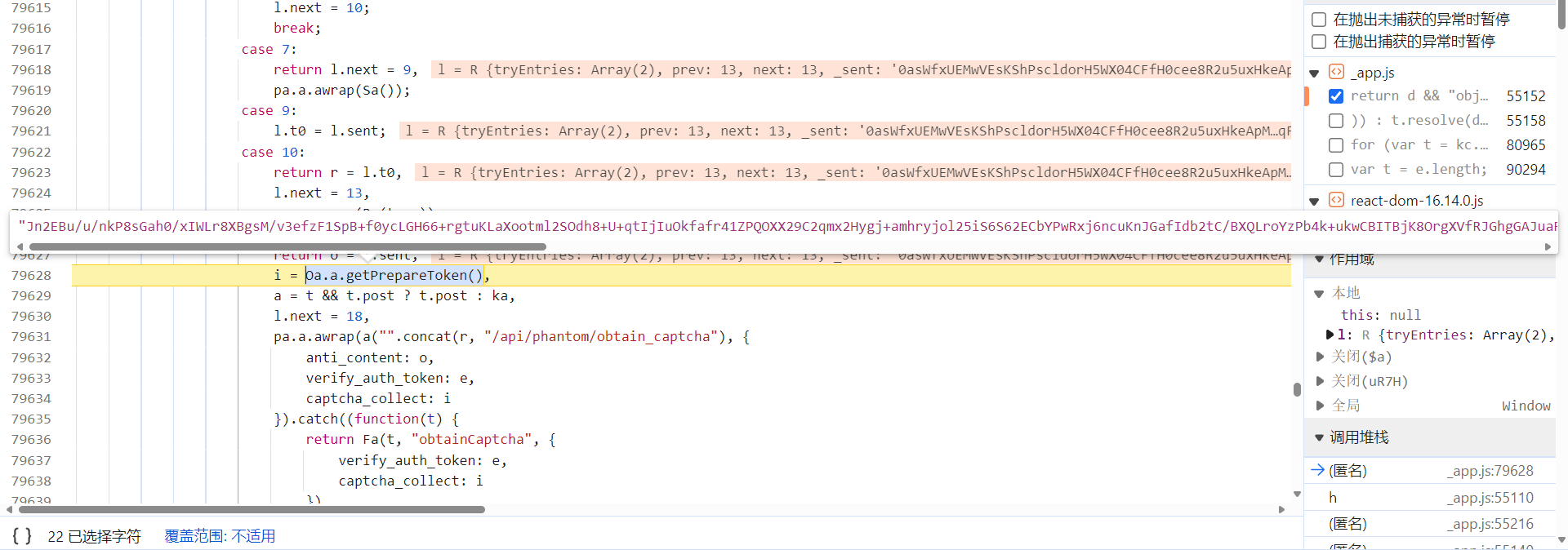
h(m(JSON.stringify(e)), k, C) 方法生成了 captcha_collect 参数的值,e 包含了一些环境相关的信息,k、C 明显也经过了加密处理:
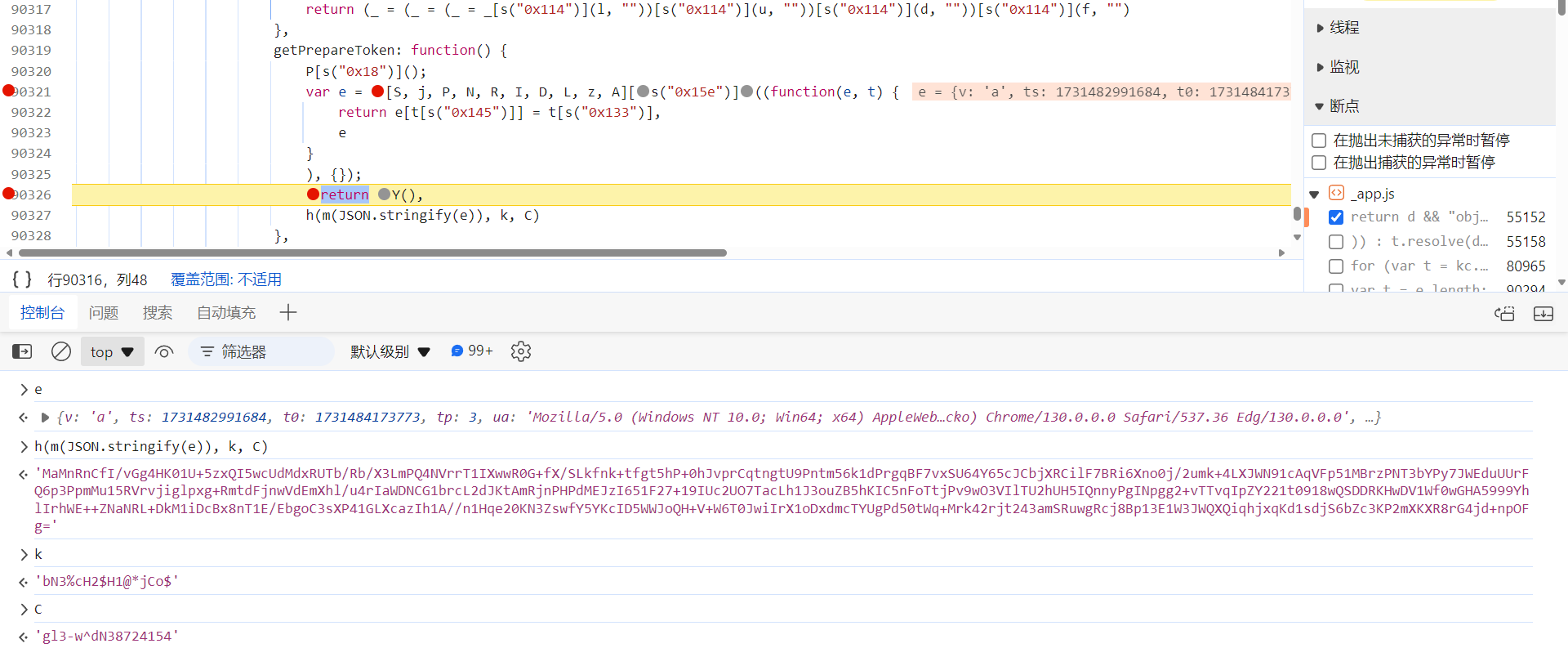
先跟到 m 方法中去看看,这里是将各环境参数组成的字符串,使用 Gzip 压缩算法处理后得到的结果:

在 JavaScript 中,一般使用两种方式实现 Gzip 压缩,分别是 pako 库和 zlib 模块:
- pako:JavaScript 库,支持浏览器端和 Node.js 环境。pako 被设计为轻量级且跨平台,因此可以在浏览器中直接使用,无需依赖额外的本地模块或工具。适用于:浏览器端应用、前端开发、客户端 JavaScript 压缩;
- zlib:是 Node.js 自带的原生模块,专门用于在 Node.js 环境中处理压缩和解压操作。zlib 基于 C++ 库,性能上通常更好,适用于处理大规模的数据压缩任务。适用于:服务器端应用、Node.js 后端开发、处理大文件压缩。
直接使用 pako 库即可:
npm install pako
const pako = require('pako');
// Gzip 压缩明文
const compressedText = pako.gzip(text);
// 将压缩后的字节数组转换为字符串
String.fromCharCode.apply(null, new Uint8Array(compressedText));
接下来,分析 h 函数,其就在 m 函数上面,跟过去下断点,key 和 iv 对应前文提到的 k 和 C:
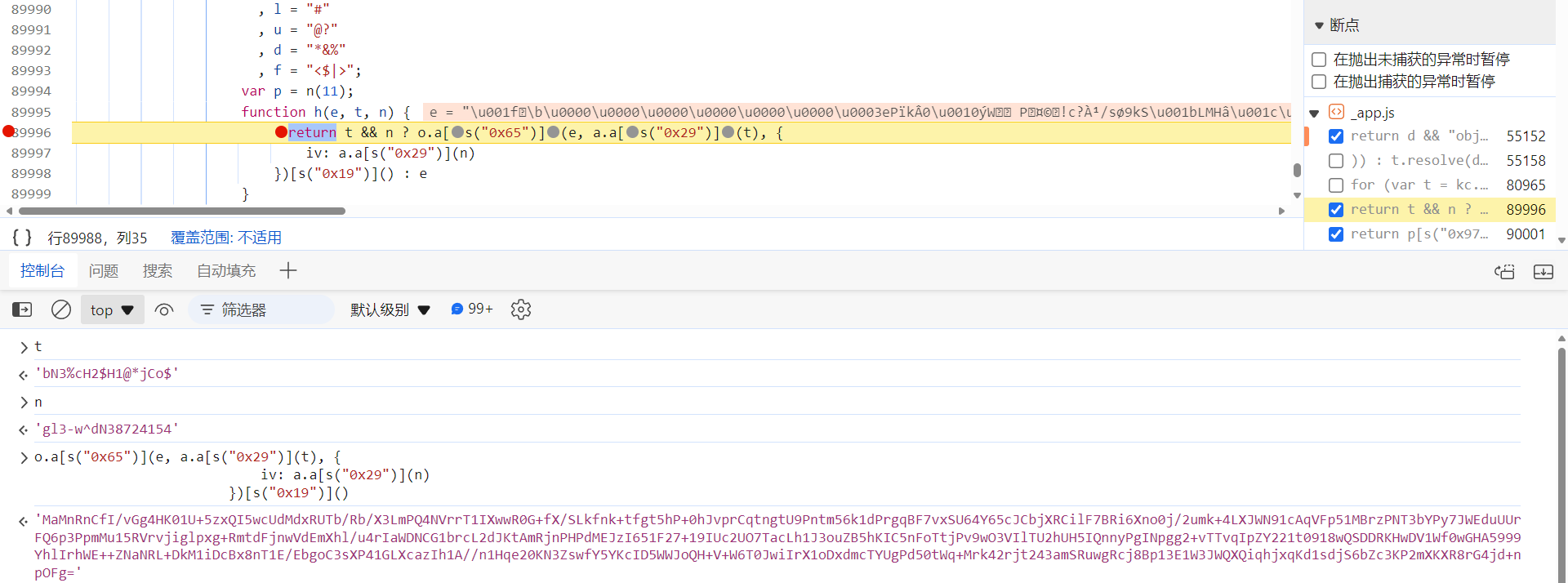
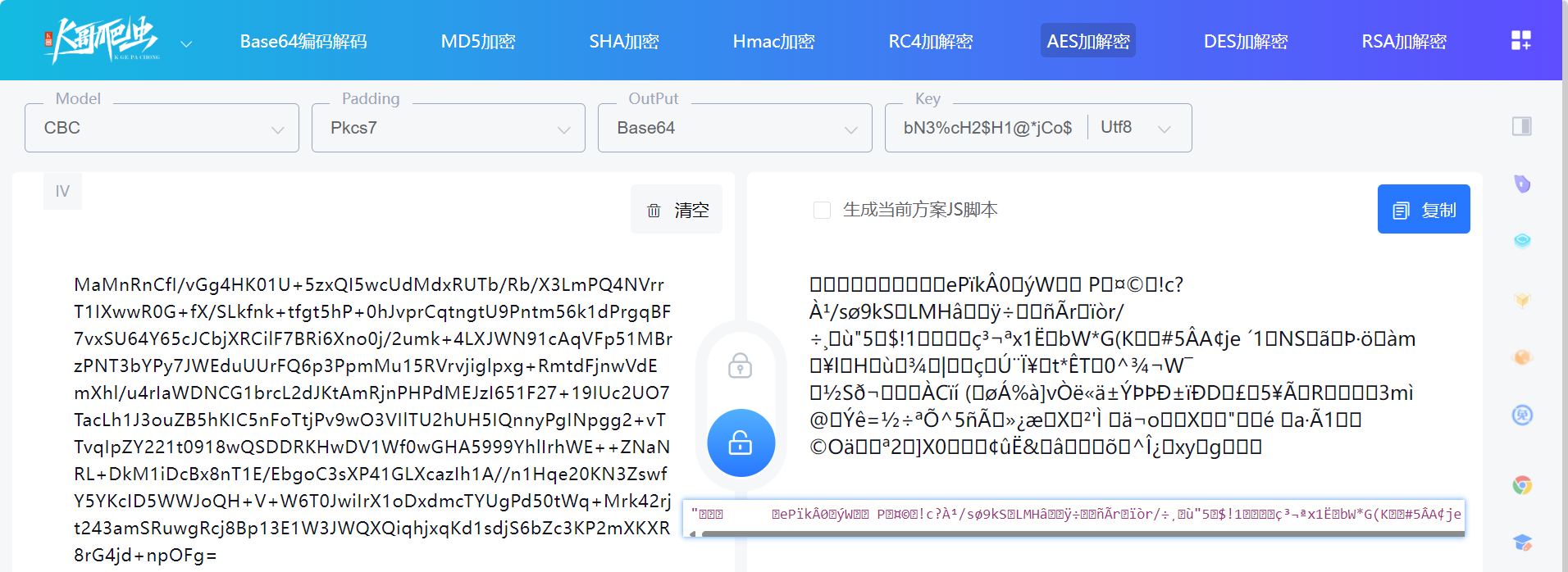
AES 加密算法( https://www.kgtools.cn/secret/aes ):
k、C 定义在 getPrepareToken 函数上的 init 函数中,写的很明显了 aes_key、aes_iv:
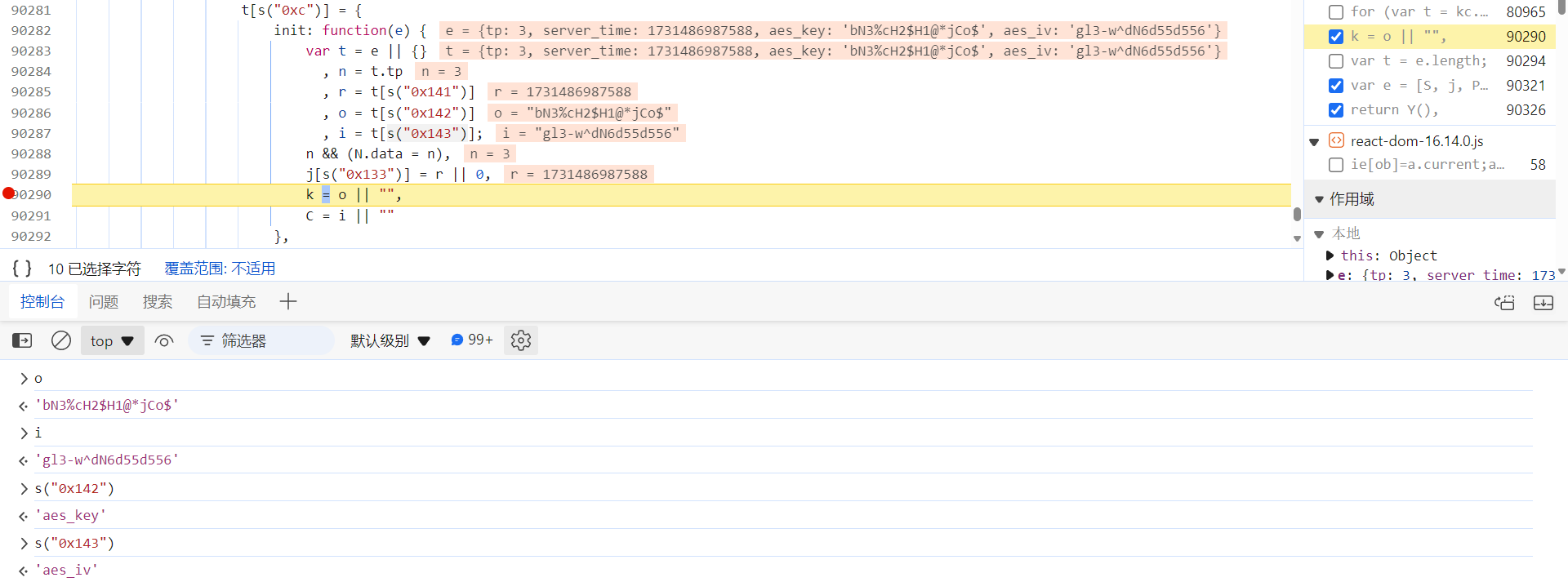
是哪加密的呢?往上跟栈,发现 Za(c) 方法生成的 aes_key 和 aes_iv,c 就是前文提到的 /api/phantom/vc_pre_ck_b 接口响应返回的 salt 值:
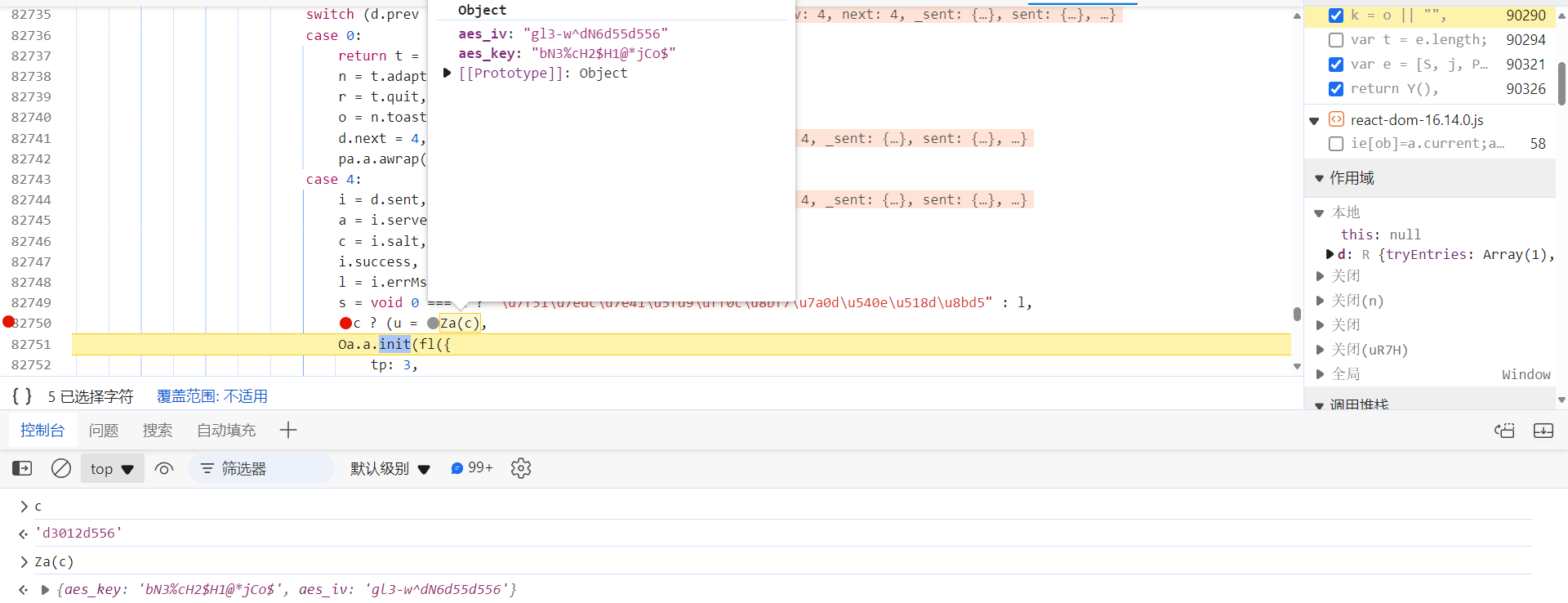
跟进去,将代码扣下来即可,也可以用 Python 复现加密算法:

第二个,captcha_collect 参数,直接在 _app.js 文件中局部搜索定位,逐个下断分析。定位到下图处,c 就是点击的坐标,Oa.a.getImageClickToken() 函数生成的就是验证接口的 captcha_collect 参数的值:
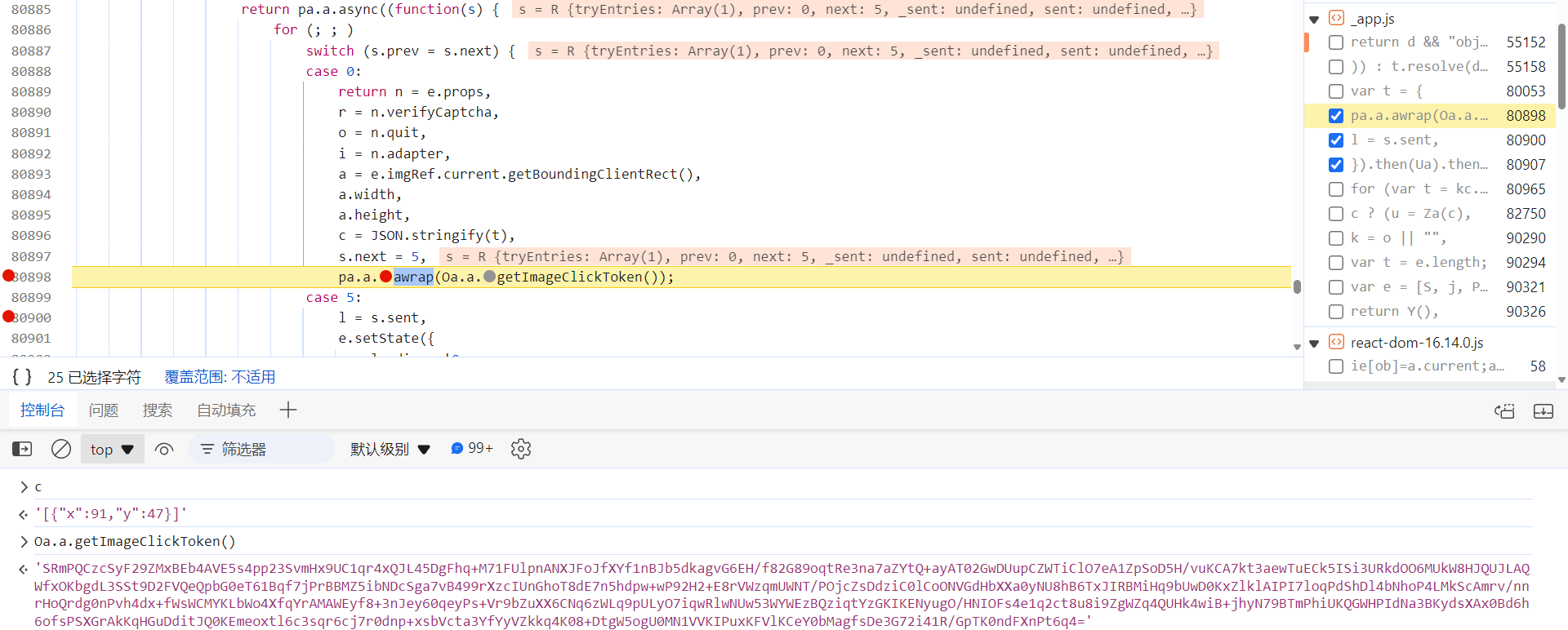
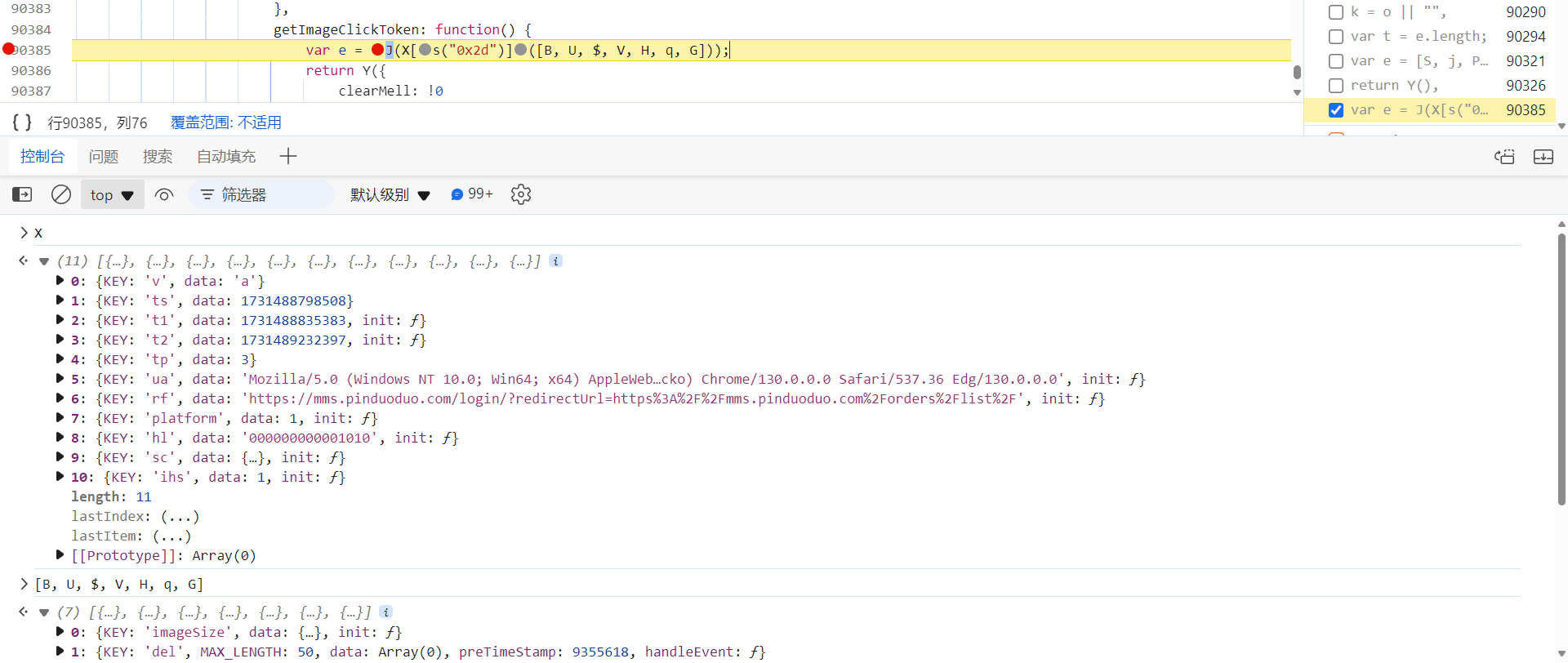
跟进去,这里的 J(X["concat"]([B, U, $, V, H, q, G])) 就是将数组 X 和 [B, U, $, V, H, q, G] 拼接之后加密,得到 captcha_collect 的值,包含了环境、轨迹等参数,校验不严:
J 函数跟进去和第一个 captcha_collect 参数的加密方式一致,k、C 相同:
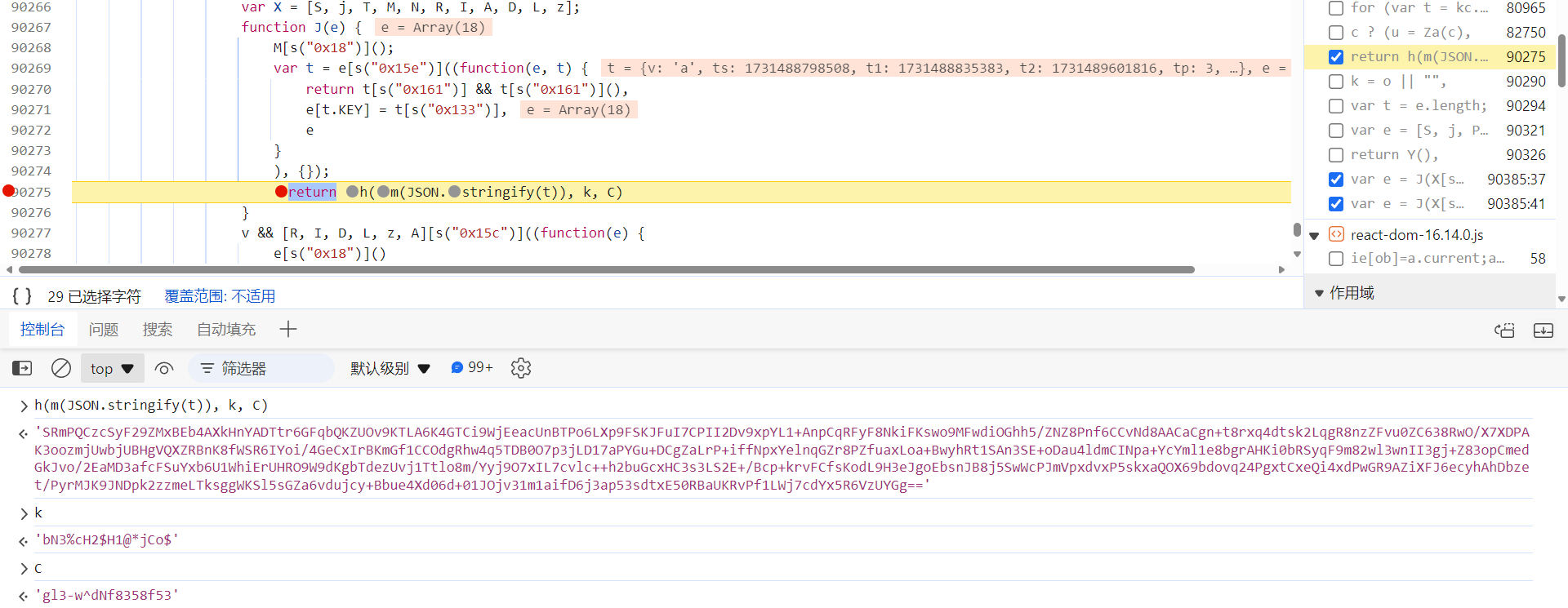
至此,整个验证码的加密分析流程就结束了。
相关算法源码,会分享到知识星球当中,需要的小伙伴自取,仅供学习交流。
结果验证


 浙公网安备 33010602011771号
浙公网安备 33010602011771号