



第一次个人编程作业
https://github.com/Ihatelenz/031902444
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(3')
(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。(3')
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 600 | 600 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 20 | 60 |
| · Coding | · 具体编码 | 600 | 750 |
| · Code Review | · 代码复审 | 60 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 60 | 120 |
| · Test Repor | · 测试报告 | 20 | 10 |
| · Size Measurement | · 计算工作量 | 30 | 45 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| · 合计 | 1935 | 2500 |
二、计算模块接口
计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
有word、text、ans三个类,
有shuru(),charu(),print(),find()四个函数。
三个类分别保存测试词、待测试文档和输出的答案。
shuru()处理words.txt和org.txt中的数据,并存入word和text类中,find()查找文档中的敏感词并通过charu()存入ans类中,最后通过print()函数输出到ans.txt文档中。
关键函数find()的原理比较简单,是暴力解法,考虑到自己的能力问题,只处理了带有插入字符的敏感词。流程图应该不需要画吧。
每次一行待测文字,一个敏感词进入find()函数。一个中文编码三字节,一个英文字母编码一字节,所以分中文敏感词和英文敏感词检测。中文每三个字节检测一次,直到查找出所有的字或者记录到20个无关插入字符,或者待测文字检测完了。英文只有检测的数量不一致,是每一个字节检测一次。查找到了就运用charu()记录下来,然后接着查找,直到待测文字都扫描完。
暴力解法,算法的独到之处大概没有。
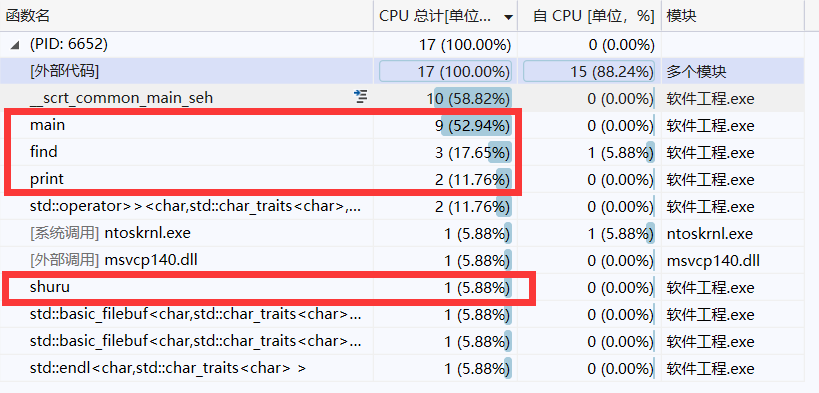
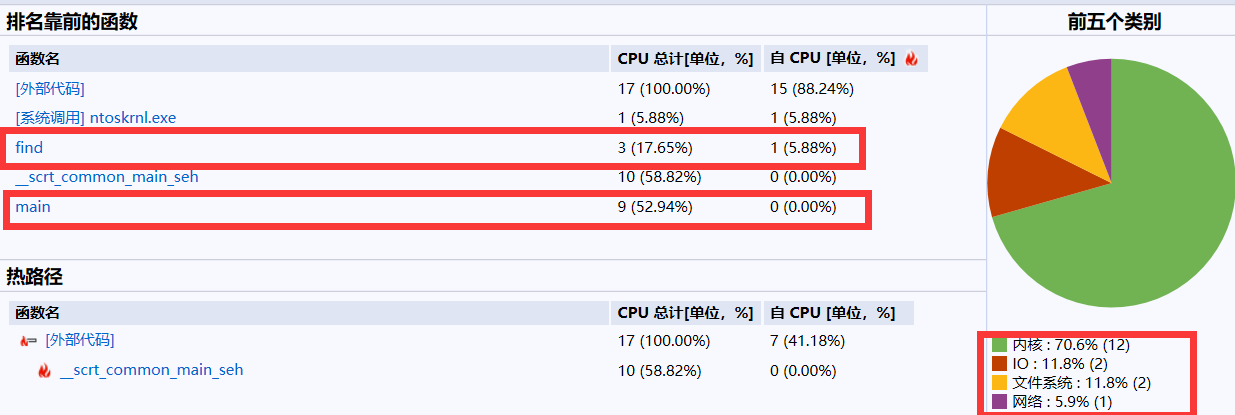
计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
性能分析图:
消耗最大的函数find():
void find(word& W, text& T) //查找对应敏感词段
{
int i = 0, j = 0;
int front = 0, back = 0;
int sum = 0, l = 0;
int fei = 0;
string a;
string b;
if (W.flag == 1) //中文匹配
{
front = 0;
back = 0;
for (; j < T.str.length(); j++)
{
a = W.name.substr(i, 3); //一个中文编码三字节,每三字节取出配对
b = T.str.substr(j, 3);
if (a==b)
{
if (i == 0)
{
front = j;
}
i += 3;
j += 2;
if (i == W.name.length()) //一个完整敏感词匹配结束,录入答案
{
charu(front, j, W.no, T.no);
i = 0;
}
}
}
}
else //英文匹配
{
front = 0;
back = 0;
transform(T.str.begin(), T.str.end(), T.str.begin(), ::tolower); //待测行和待测敏感词不区分大小写,全部转换成小写
transform(W.name.begin(), W.name.end(), W.name.begin(), ::tolower);
for (; j < T.str.length(); j++)
{
if (W.name[i] == T.str[j])
{
if (i == 0)
{
front = j;
}
i++;
if (i == W.name.length()) //一个完整敏感词匹配结束,录入答案
{
charu(front, j, W.no, T.no);
i = 0;
fei = 0;
}
}
else
fei++;
if (fei > 20) //插入无关字符超过20个,结束匹配
break;
}
}
}
最大占比的函数是查找find()函数,可以写一个tire树,改进查找的过程,加上拼音和汉字的匹配,就可以比较完整地写出敏感词查找的功能,并且减少损耗。
计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
在网上找了一些c++单元测试的帖子,遗憾的是并没有能透彻地学会,没有能实现单元测试来测试自己的函数。
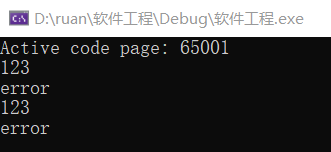
计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
输入错误路径:
三、心得
第一次体会自己做出这么复杂功能的程序,但是还是没能完整地做完。看着自己写的bug都改完了,还是很开心的。但是希望在这次的经验后,下次作业能有更精彩的表现。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号