pg总览
./configure --prefix=/release --with-openssl --without-ldap --with-libxml - -enable-thread-safety make -j4 make install initdb -D /home/postgres/postgres_5432/data -U postgres -W --wal-segsize=16 -E UTF8 # 注意事项: # 1、-D 类似于mysql的datadir,data目录必须是空目录(否则初始化失败),且权限必须是0700(否则无法重启) # 2、--wal-segsize=16 选项:默认的就是16M大小的wal日志,PostgreSQL11版本的一个重要调整是支持initdb和 pg_resetwal修改WAL文件大小,而11版本之前只能在编译安装PostgreSQL时设置WAL文件大小。这一特性能够方便WAL文件的管理。WAL日志文件大小默认为16MB,该值必须是1到1024之间的2的次方,增大WAL文件大小能够减少WAL日志文件的产生。类似于mysql的redolog pg_resetwal --wal-segsize=64 -D /home/postgres/postgres_5432/data PostgreSQL的默认用户名和数据库也是“postgres”,不过没有默认密码。在安装PostgreSQL之后可以默认用户登录 # 先切换帐号 su - postgres # 启动 pg_ctl start -D ../data # 测试服务是否开启 ps -ef|grep postgres # 停止服务 pg_ctl -D datadir stop -m smart # 鸡肋。等待活动的事务提交结束,并等待客户端主动断开链接后关闭数据库,如果客户端不断开链接,则停止服务会失败,可以简写成: -ms pg_ctl -D datadir stop -m fast #提倡。回滚所有活动中的事务,并强制断开客户端的链接,简写:-mf pg_ctl -D datadir stop -m immediate # 不推荐。立即终止所有服务器进程,下次启动时,会先进入恢复状态,简写:-mi ./psql -h localhost -p 5434 -U postgres -W psql -h localhost -p 5432 -U postgres -d postgres -f a.sql 执行sql文件 psql -h localhost -p 5432 -U postgres -d postgres -c "select * from table_name limit 5;" # 相当于mysql中的 -e参数
# pg_ctl reload,支持热加载,不用重启。 # 1、pg中pg_hba.conf,与mysql中的mysql.user表功能类似 格式 type database user address method # 允许主机address上的用户user通过type方式以method的认证方式来连接database数据库,比如: host all all 10.10.10.10/32 trust # type有local、host、hostssl、hostnossl #local用unix域套接字,相当于mysql中使用—S参数来指定套接字,host为tcp/ip, # database的值:具体的数据库名称、all表示匹配所有数据库但不具有匹配物理复制的连接请求,replication匹配物理复制的连接请求。多个数据库名称用逗号分割。 # user有all,多个用户名称用逗号分割。 # address,0.0.0.0/0表示所有主机,10.10.10.10/32某个ip,10.10.10.0/24表示一个网段,逗号分隔 # method有trust、md5、ident(,只适合本地连接,用户映射文件pg_ident.conf(mapUser root root)) # 2、postgresql.conf,类似于mysql中的my.cnf文件 shared_buffers #类似于mysql中innodb_buffer_pool_size wal_level = hot_standby hot_standby = on # 在备份的同时允许查询 hot_standby_feedback = on # 查询冲突时向主反馈 checkpoint_segments = 16 checkpoint_timeout = 5min archive_mode = on archive_command = '/bin/date' wal_receiver_status_interval = 1s wal_receiver_timeout = 60s wal_keep_segments = 16 max_wal_senders = 3 max_standby_archive_delay = 300s # 从向主报告状态的最大间隔时间 max_standby_streaming_delay = 30s # 流复制最大延迟 todo:如何得到的?如何处理? # 3、reconvery.conf,主从复制的从库必要文件。 standby_mode = 'on' trigger_file = '/database/pgdata/postgresql.trigger.1949' primary_conninfo = 'host=10.1.11.73 port=5432 user=replica password=replica keepalives_idle=60'
# 单库一致性逻辑备份:每次只导出一个数据库,而且它不会导出角色或表空间(属于集群范围)相关的信息。不能ddl操作 pg_dump -h hostname -p port -U username -f filename.sql -F p -C -E UTF8 --no-tablespaces --lock-wait-timeout=5s --exclude-table-data=TABLE --exclude-schema=SCHEMA db_name # --if-exists --clean # 那么在恢复的时候,如果您仍然拥有旧数据,并且希望恢复整个数据库,则可能需要删除现有数据库,然后重新创建它。需要对应的角色和表空间。 psql -h host -p port -U postgres -d databasename < filename.sql # 整个集群一致性逻辑备份 pg_dumpall -g -h hostname -p port -U postgres -f ./global.dmp # 仅导出role pg_dumpall -r -h hostname -p port -U postgres -f ./global.dmp # 仅导出tablespace pg_dumpall -t -h hostname -p port -U postgres -f ./global.dmp # 恢复 psql -h host -p port -U postgres < filename.sql ######################################################################## # 1、完全停掉数据库,然后使用系统命令例如cp,scp等复制一份数据。 # 2、pg_basebackup 要进行手动、一致的物理备份,需要以下步骤: 在备份开始创建一个检查点pg_start_backup(‘some label’) 拷贝目录中的数据 使用命令pg_stop_backup()停止备份 所有这些可以通过运行pg_basebackup实现 pg_basebackup -U postgres -h hostname -x -D datadir #
# 实例---表空间(pg_default,目录)----数据库(template1)---模式(public)---模式对象 ###################################################################################### # 表空间,对应一个目录,是数据存放的物理位置,创建表空间,表空间是一个目录,表空间与数据库是一对多的关系,建议一一对应。 create tablespace tablespace_name with owner user_name location '/home/postgres/postgresql11_5432/tablespace_name'; # 创建数据库,一个数据库至少有一个模式,一个数据库在实例中全局唯一。 create database databases_name owner user_name # 数据库所有者默认是当前创建数据库的角色 template template_name # 默认克隆template1数据库,而他的的默认表空间是pg_default tablespace tablespace_name;# 默认的表空间是pg_default。在数据库初始化时创建的 encoding utf8 # 一个数据库下面有多个不同模式 # 不同数据库下的模式互不相关 # 建议 数据库的用户分别创建一个与用户名相同的模式, # 创建用户--表空间---数据库---模式(与用户名相同名称),然后将search_path设置为"$user", # mysql的区别
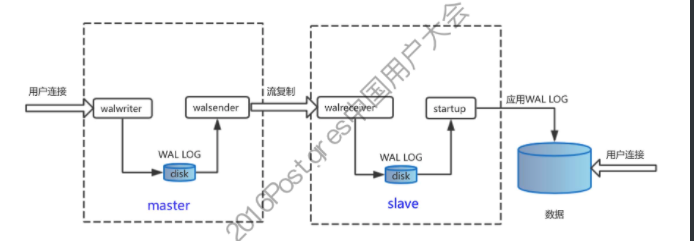
# 流复制:1、同步流复制和异步流复制原理。(多进程) # 选择:如果主库和从库不是很忙的话,异步流复制的主从延迟能控制在毫秒级别。 # 流复制:是物理复制,其核心原理是主库将预写日志WAL日志流发送给备库,备库接收到WAL志流后进行重做,而逻辑复制虽然也是基于wal日志,但是他是先解析wal日志后再进行重放,而且ddl语句不会被复制。 # 0、流复制只能进行实例级别的复制,而逻辑复制能够进行数据库级别的复制。mysql则也是实例级别。 # 1、dml和ddl操作,流复制都会进行复制。但是逻辑复制中,ddl操作从库不会进行复制。。这一点mysql也是具备的。 # 2、流复制主库可读写,而从库只允许读,不能写。逻辑复制的从库则可读写。mysql需要设置全局变量read_only, # 3、流复制要求pg大版本必须一致,而逻辑复制则可跨越大版本。mysql中主库和从库版本可以不一致。 # 异步流复制原理 # WAL日志类似于mysql的binlog日志,默认16M大小,
# 主库WAL日志发送进程, 备WAL日志接受进程,
# 异步流复制指主库上提交事务时不需要等待备库接接受写入WAL日志时便返回成功,如果主库异常看机,主库上已提交事务可能还没来得及发送给备库,
就会造成备库数据丢失,备库丢失数据量和WAL复制延迟有关,WAL制延迟越大,备库上丢失的数据量越大。这一点就和mysql基于binlog的复制原理类似。

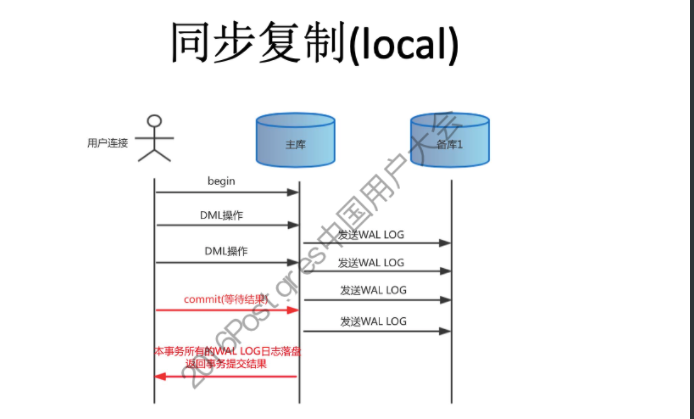
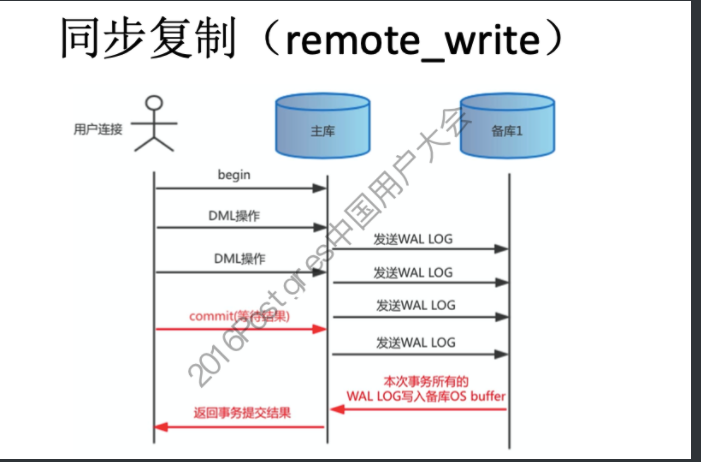
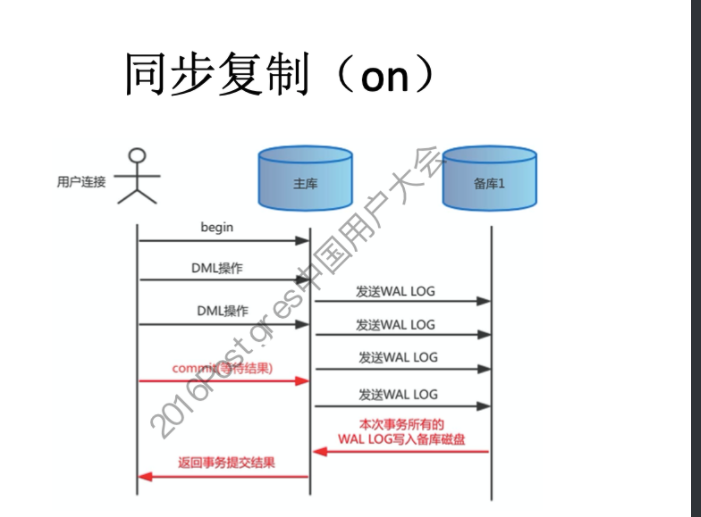
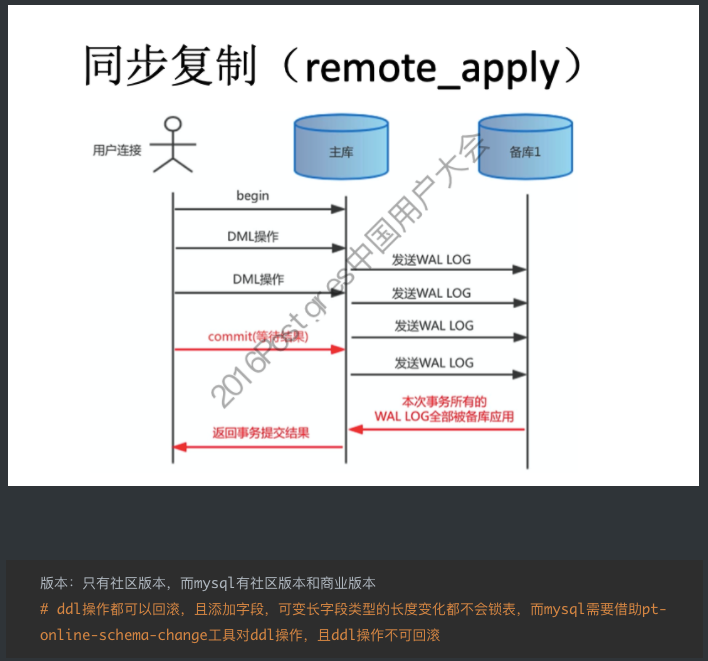
#主库配置postgresql.conf synchronous_commit = on /remote_apply hot standby = on synchronous_standby_narnes = node # 备库配置recovery.conf recovery_target_timeli = 'latest' # 从备份的时间线恢复到最近的时间线 standby_mode = on # 启用该数据库为备库 primary_conninfo= 'host=Hostnamer port=5432 user=repuser application_narne=node' # pg_ctl reload 生效 # 同步流复制:要求主库把WAL日志写入磁盘,同时等待WAL日志记录复制到备库、并且WAL日志记录在任何一个备库写入磁盘后,才能向应用返回Commit结果。 # 一旦所有备库故障,在主库的应用操作则会被挂起,所以此方式建议起码是1主2备。 # 默认从库只读,而mysql需要设置read_only变量 # PostgreSQL使用另一组全局变量,记录同步流复制节点已经接收到的XLOG LSN,以及已经持久化的XLOG LSN。用户在发起提交请求后,backend process除了要判断本地wal有没有持久化,
同时还需要判断同步流复制节点的XLOG有没有接收到或持久化(通过synchronous_commit参数控制)。如果同步流复制节点的XLOG还没有接收或持久化,backend process会进入等待状态。 # 用户发起dml操作的提交后,主库的backend进程,先判断本地wal有没有持久化,同时还要判断任意一个同步流复制节点的XLOG有没有接收到或持久化(使用一组记录同步流复制节点已经接收到的XLOG LSN,以及已经持久化的XLOG LSN全局变量), # 主库提交事务时,需等待至少一个备库接收WAL并返回确认信息后主库才客户端返回成功。如果是一主一备时,如果从库宕机,则主库无法提交事务,读操作没有任何影响,写操作将处于阻塞状态。因此一主一备的情况下一般都不会采用同步复制方式。 # 一主多从架构的时候,可以设置一个备库为同步备库,其余为异步备库,当同步备库异常宕机后可将其升级为同步备库,这样主库写操作不受影响。 local remote_write on remote_apply
igoodful@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号