【学习笔记】Scrapy
刚刚接触Scrapy
根据书上的内容做练习
爬取书上的链接里的书本信息
1 import scrapy 2 class FuzxSpider(scrapy.Spider): 3 name = "Fuzx" 4 start_urls=['http://books.toscrape.com/'] 5 def parse(self, response): 6 for book in response.css('article.product_pod'): 7 name=book.xpath('./h3/a/@title').extract_first() 8 price=book.css('p.price_color::text').extract_first() 9 yield { 10 'name':name, 11 'price':price, 12 } 13 next_url=response.css('ul.pager li.next a::attr(href)').extract_first() 14 if next_url: 15 next_url=response.urljoin(next_url) 16 yield scrapy.Request(next_url,callback=self.parse)
命令:scrapy crawl Fuzx -o fuzx.csv
将内容保存在fuzx.csv里

看样子爬成功了
延伸一下 网上说练爬虫豆瓣比较容易
我打开的是豆瓣阅读的小说界面 https://read.douban.com/kind/100
爬取图书名和作者
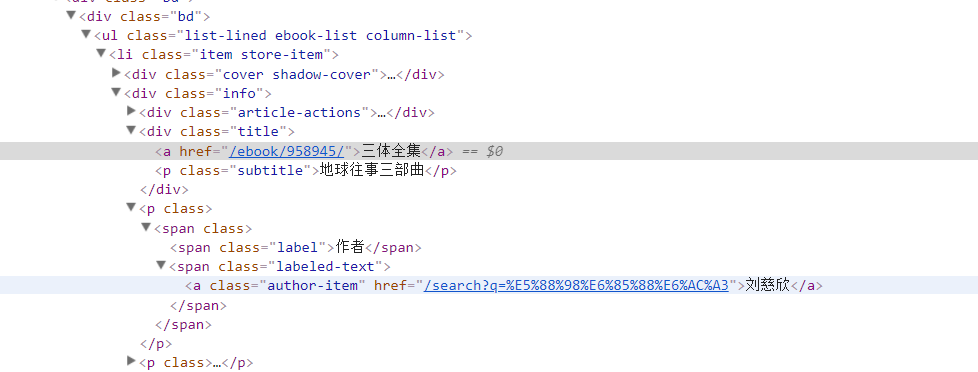
然后改了css选择器的内容
报错403
然后我加了个User-Agent
第二次出现问题的地方是在 这里有空格
这里有空格
for book in response.css('li.item.store-item'):
参考别人的文章,可以用上面这种写法
完整代码:
1 import scrapy 2 class DoubSpider(scrapy.Spider): 3 name = "doub" 4 headers = { 5 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0', 6 } 7 def start_requests(self): 8 url = 'https://read.douban.com/kind/100' 9 yield scrapy.Request(url, headers=self.headers) 10 11 def parse(self, response): 12 for book in response.css('li.item.store-item'): 13 name=book.css('div.title a::text').extract_first() 14 author=book.css('p span.labeled-text a.author-item::text').extract_first() 15 yield { 16 'name':name, 17 'author':author, 18 } 19 next_url=response.css('div.pagination li.next a::attr(href)').extract_first() 20 if next_url: 21 next_url=response.urljoin(next_url) 22 yield scrapy.Request(next_url,headers=self.headers,callback=self.parse)
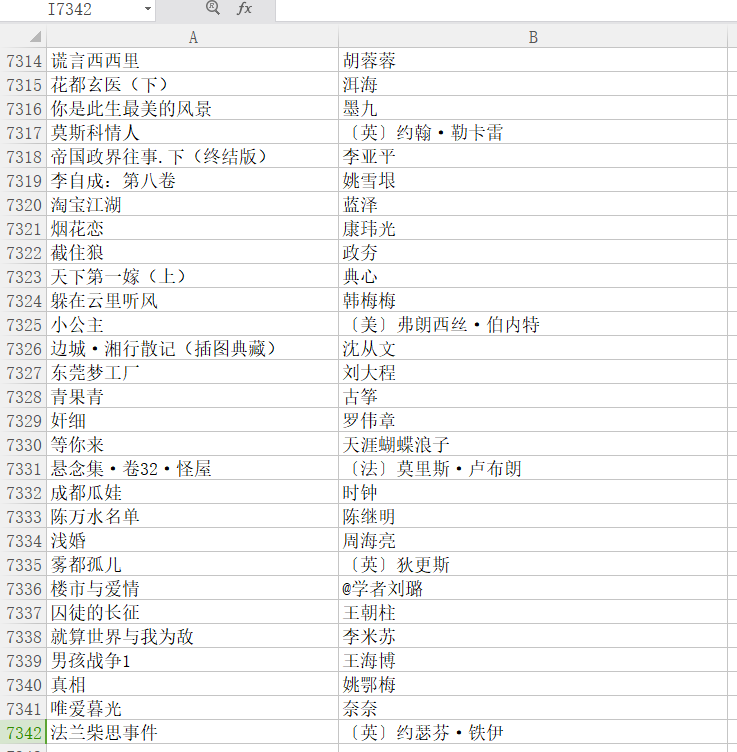
然后scrapy crawl doub -o db.csv
爬完查看db.csv
所爱隔山海,山海不可平

 浙公网安备 33010602011771号
浙公网安备 33010602011771号