tensorflow 2.x 多机单卡 分布式训练配置笔记.18010232
tensorflow 2.x 多机单卡 分布式训练配置笔记
tensorflow 2.x 多机单卡 demo代码演示。配置笔记
多机多卡属于 tensorflow的 tf.distribute.MultiWorkerMirroredStrategy 策略,下面为详细的环境配置和demo代码
环境、版本
操作系统:Ubuntu 22.04
Python环境:anaconda 23.11.0、Python 3.8
Tensorflow:2.12.0
硬件环境:通过vmwere安装两个Ubuntu虚拟机,网络配置为NAT方式
配置步骤
- 创建虚拟环境
conda create -n tensorflow2 python=3.8
- 安装tensorflow
conda install tensorflow=2.12
-
分别查看两台虚拟机的ip地址,
ip addr例如我的输出如下图
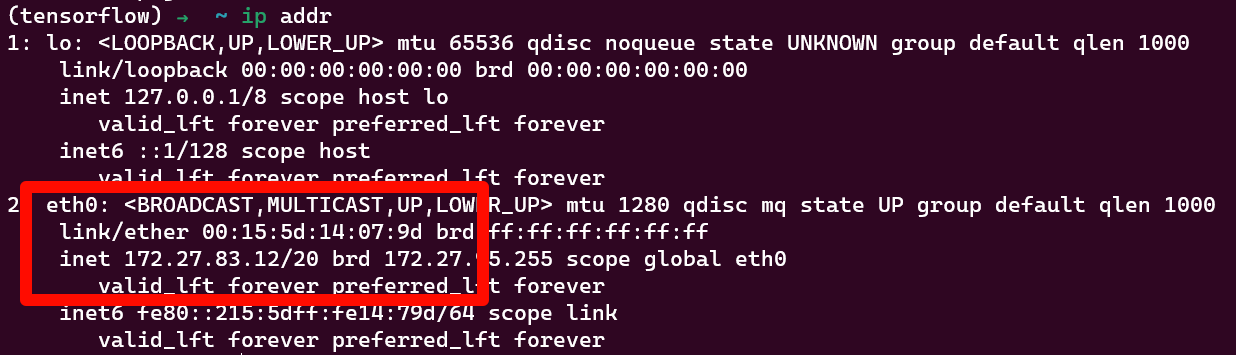
我的ip地址为172.27.83.12,另一台虚拟机同理 -
编写代码
代码来源tensorflow 文档中的[Google Colab连接]原始代码为ipython形式,这里进行了少量修改以python文件的形式运行(https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/zh-cn/guide/distributed_training.ipynb?hl=zh-cn) 此示例程序实现手写数字识别
主程序代码 保存为 main.py
import os
import json
import tensorflow as tf
import mnist_setup
tf_config = {
'cluster': {
'worker': ['192.168.91.128:12345', '172.27.83.12:23456'] # 工作节点的ip和端口列表,根据实际情况修改
},
'task': {'type': 'worker', 'index': 0}
}
os.environ['TF_CONFIG'] = json.dumps(tf_config) # 将配置转为json字符串并配置环境变量,此配置非常重要,不可跳过
per_worker_batch_size = 64
# tf_config = json.loads(os.environ['TF_CONFIG']) # 从环境变量中获取配置,此处可删除,因为tf_config变量已经赋值了
num_workers = len(tf_config['cluster']['worker'])
strategy = tf.distribute.MultiWorkerMirroredStrategy() # 配置多机单卡策略
global_batch_size = per_worker_batch_size * num_workers
multi_worker_dataset = mnist_setup.mnist_dataset(global_batch_size)
with strategy.scope():
# Model building/compiling need to be within `strategy.scope()`.
multi_worker_model = mnist_setup.build_and_compile_cnn_model()
multi_worker_model.fit(multi_worker_dataset, epochs=3, steps_per_epoch=70)
非核心代码 保存为mnist_setup
import os
import tensorflow as tf
import numpy as np
def mnist_dataset(batch_size):
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
# The `x` arrays are in uint8 and have values in the [0, 255] range.
# You need to convert them to float32 with values in the [0, 1] range.
x_train = x_train / np.float32(255)
y_train = y_train.astype(np.int64)
train_dataset = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(60000).repeat().batch(batch_size)
return train_dataset
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(28, 28)),
tf.keras.layers.Reshape(target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
return model
-
前面创建了两个虚拟机,需要根据虚拟机ip修改代码中
tf_config中的worker数组,并且修改index值,如下图所示
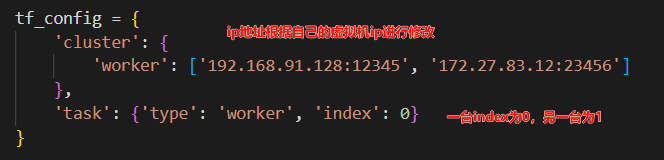
-
运行程序,两台虚拟机分别执行
python main.py运行程序
常见问题
- 两台虚拟机相互ping,确保网络相互可达再运行程序
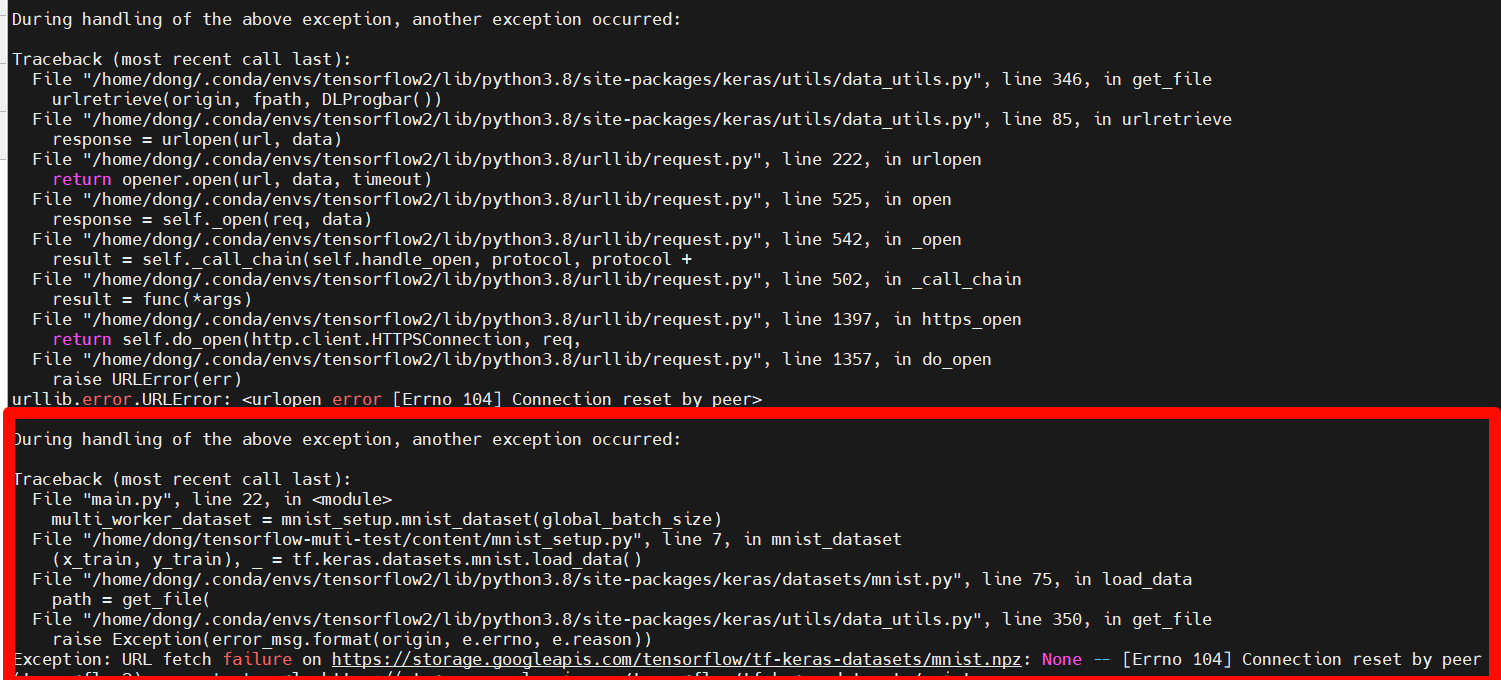
- 如下图所示错误,原因是下载数据集失败,修改
mnist_setup示例程序使用其他数据集或者自行解决网络问题
- 两端运行不同步,各自执行。检查是否配置了环境变量即
os.environ['TF_CONFIG'] = json.dumps(tf_config)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号