5.查询操作
本章目标
- SQL查询语法
- 聚合函数
- 连接查询
- 子查询
- 分页
本章内容
一、SQL查询语法
查询产生一个虚拟表,看到的是表形式显示的结果,但结果并不真正存储,每次执行查询只是现从数据表中提取数据,并按照表的形式显示出来。
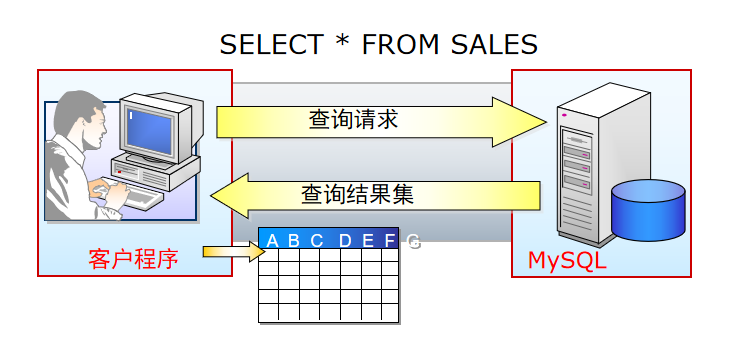
1、基本语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
select_expr [, select_expr] ...
[into_option]
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
from子句:指定查询数据的表 where子句:查询数据的过滤条件 group by子句:对匹配where子句的查询结果进行分组 having子句:对分组后的结果进行条件限制 order by子句:对查询结果结果进行排序,后面跟desc降序或asc升序(默认)。 limit子句:对查询的显示结果限制数目
2、 SELECT子句
使用以下几种方式指定字段列表:
| 字段列表 | 说明 |
|---|---|
| * | 字段列表为数据源的全部字段 |
| 表名.* | 多表查询时,指定某个表的全部字段 |
| 字段列表 | 指定所需要显示的列 |
可以为字段列表中的字段名或表达式指定别名,中间使用as关键字分隔即可(as关键字可以省略)。 多表查询时,同名字段前必须添加表名前缀,中间使用“.”分隔。
3、 where子句
数据库中存储着海量数据,数据库用户往往需要的是满足特定条件的记录,where子句可以实现结果集的过滤筛选。 where子句的语法格式:
where 条件表达式
条件表达式:
| 关键字 | 解释 |
|---|---|
| 比较运算符 | 单一条件过滤 |
| 逻辑运算符 | 组合多个条件查询 |
| BETWEEN AND | 在两数之间 |
| NOT BETWEEN AND | 不在两数之间 |
| IN <值表> | 是否在特定的集合里(枚举) |
| NOT IN <值表> | 与上面相反 |
| LIKE | 是否匹配于一个模式 |
| IS NULL | 为空的 |
| IS NOT NULL | 不为空的 |
| Binary | 区分大小写 |
3.1、比较运算符
常用的比较运算符有=(等于)、>(大于)、>=(大于等于)、<(小于)、<=(小于等于)、<>(不等于)、!=(不等于)
表达式1 比较运算符 表达式2
说明:“表达式1”和“表达式2”可以是一个字段名、常量、变量、函数甚至是子查询。比较运算符用于比较两个表达式的值,比较的结果是一个布尔值(true或者false)。
如果表达式的结果是数值,则按照数值的大小进行比较;如果表达式的结果是字符串,则需要参考字符序collation的设置进行比较
注意:如果某行比较列值为null时,在做不等于运算符时,该行不会满足的运算条件,不加入的结果集中
3.2、逻辑运算符
where子句中可以包含多个查询条件,使用逻辑运算符可以将多个查询条件组合起来,完成更为复杂的过滤筛选。
常用的逻辑运算符包括逻辑与(and)、逻辑或(or)以及逻辑非(not),其中逻辑非(not)为单目运算符。
- 逻辑非(not或!) 逻辑非(not)为单目运算符
- and逻辑运算符 使用and逻辑运算符连接两个布尔表达式时,只有两个布尔表达式的值都为true时,整个逻辑表达式的结果才为true。语法格式如下:
布尔表达式1 and 布尔表达式2 - or逻辑运算符 or逻辑运算符连接两个布尔表达式时,只有两个表达式的值都为false时,整个逻辑表达式的结果才为false。语法格式如下:
布尔表达式1 or 布尔表达式2
3.3、IS NULL运算符
is NULL用于判断表达式的值是否为空值NULL(is not 恰恰相反),is NULL的语法格式如下。
表达式 is [ not ] NULL
说明:不能将“score is NULL”写成“score = NULL;”,原因是NULL是一个不确定的数,不能使用“=”、“!=”等比较运算符与NULL进行比较。
使用ISNULL(column)也可以判断列是否为空,ISNULL(column)的执行效率更高;
SELECT emp_name As 姓名, address AS 地址
FROM EMPLOYEE WHERE address IS NULL
3.4、BETWEEN AND
把某一字段中内容在特定范围内的记录查询出来
SELECT emp_name,age FROM EMPLOYEE
WHERE age BETWEEN 20 AND 30
3.5、IN
把某一字段中内容与所列出的查询内容列表匹配的记录查询出来
SELECT emp_name AS 员工姓名,contry As 地址 FROM EMPLOYEE
WHERE contry IN ('北京','广州','上海')
注意:如果某行比较列值为null时,在做not in运算符时,该行不会满足的运算条件,不加入的结果集中
尽量避免in,实在避免不了,也建议将集合元素个数控制在1000个以内;
3.6、模糊查询
like运算符用于判断一个字符串是否与给定的模式相匹配。 模式是一种特殊的字符串,特殊之处在于不仅包含普通字符,还包含有通配符。在实际应用中,如果不能对字符串进行精确查询,此时可以使用like运算符与通配符实现模糊查询,like运算符的语法格式如下。 字符串表达式 [ not ] like 模式
SELECT emp_name AS 姓名 FROM EMPLOYEE
WHERE emp_name LIKE '张%'
| 通配符 | 含义 |
|---|---|
| % | 指定位置有零个或多个字符 |
| _ | 指定位置有1个 |
查询第个字为牛的名称
SELECT * FROM EMPLOYEE WHERE emp_name LIKE '_牛%';
3.7、BINARY运算符
默认情况下,比较是不区分大小写的方式执行的。然而,以前我们注意到,可以添加BINARY关键字让MySQL执行区分大小写的比较。
SELECT * FROM emp WHERE emp_name LIKE BINARY '%tom%';
二、 聚合函数
工资表中存储了所有员工的工资,我想知道:公司支出的总薪水、员工的平均工资、工资水平在2000块钱以上的总共有多少人?怎么办?
| 函数 | 介绍 |
|---|---|
| SUM() | 求总和,只适用于数值类型字段,如果是字符串类型不会报错会返回0,会自动过滤空值 |
| AVG() | 求平均值,只适用于数值类型字段,字符串类型不会报错会返回0,会自动过滤空值 |
| MAX() | 求最大值,适用于数值类型、字符串类型和日期时间类型字段 |
| MIN() | 求最小值,适用于数值类型、字符串类型和日期时间类型字段 |
| COUNT() | 用于计算查询结果集中的数据共有多少条 |
1、SUM
SELECT SUM(sal_disburse) AS '2019年5月公司总薪水支出'
FROM SALARY WHERE sal_ym='201905'
2、AVG
SELECT AVG(sal_disburse) AS '2019年6月平均工资'
FROM SALARY
WHERE sal_ym='201906'
3、MAX、MIN
SELECT AVG(sal_disburse) AS '平均工资',
MAX (sal_disburse) AS '最高工资',
MIN (sal_disburse) AS '最低工资'
FROM SALARY WHERE sal_ym ='201911'
4、COUNT
SELECT COUNT (*) AS '2000元工资以上的员工数量'
FROM SALARY
WHERE sal_disburse>=2000
AND sal_ym='201907'
count(*)是SQL92标准定义的统计行的语法,与数据库无关,与值无关;
count(*)会统计值为NULL的行,count(column)不会;
5、 ORDER BY
想查看2009年7月份公司工资的排名情况。怎么办?
SELECT emp_id,sal_disburse FROM SALARY
WHERE sal_ym='200907'
ORDER BY sal_disburse ASC
ASC:升序排列
DESC:降序排列
6、 GROUP BY
6.1、单列分组
如果不是统计公司的总的人数,而是想统计每个部门的总人数或者每个部门的平均年龄。怎么办?
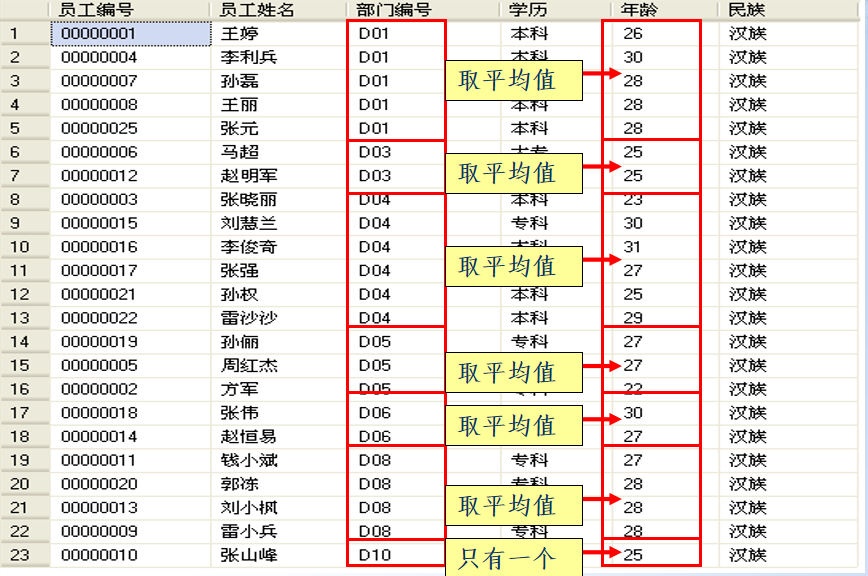
image-20230814175811269
SELECT dep_id AS 部门编号,count(emp_id)AS 部门人数,
AVG(emp_age)AS 平均年龄
FROM EMPLOYEE
GROUP BY dep_id
6.2、多列分组
如果想统计每个部门不同学历的员工有多少人,该怎么办?

image-20230814180136098
SELECT dep_id AS 部门编号,degree AS 学历,
count(*) AS 人数
FROM EMPLOYEE
GROUP BY dep_id,degree
ORDER BY dep_id
7、 HAVING
在以上查询的基础上,如果只想看非本科学历的并且人数大于1人的部门,怎么办?
SELECT dep_id AS 部门编号,degree AS 学历,
count(id) AS 人数
FROM EMPLOYEE
WHERE degree!=‘本科’
GROUP BY dep_id,degree
HAVING count(id)>1
ORDER BY dep_id
WHERE和HAVING的区别?
- WHERE子句从数据源中去掉不符合其搜索条件的数据
- GROUP BY子句搜集数据行到各个组中,统计函数为各个组计算统计值
- HAVING子句去掉不符合其组搜索条件的各组数据行
8、 完整的sql语句
select dept_id, count(*) from employee
where dept_id is not null -- 对所有数据进行筛选,不能使用聚合函数
GROUP BY dept_id -- 对where筛选后的数据进行分组
having count(*)>2 -- 对分组后的数据进行筛选
order by dept_id desc; -- 对数据进行排序
三、 连接查询
学员内部测试成绩查询的每次显示的都是学员的编号信息,因为该表中只存储了学员的编号;实际上最好显示学员的姓名,而姓名存储在学员信息表;如何同时从这两个表中取得数据?
语法:
from 表名1 [ 连接类型 ] join 表名2 on 表1和表2之间的连接条件
1、 SQL连接分类:
mysql暂不支持full join
- inner连接(内连接)
- outer连接(外连接)
- left(左外连接,简称为左连接)
- right(右外连接,简称为右连接)
- cross连接(交叉连接)
2、 内连接 Inner join
关键字 :inner join on
SELECT t1.emp_name, t2.salary
FROM employee AS t1 INNER JOIN info AS t2 ON t1.emp_name = t2.emp_name;
组合两个表中的记录,返回关联字段相符的记录,即返回两个表的交集部分
表的别名前加as,并以t1, t2, t3, …依次命名;
3、 左连接查询 left join
关键字 :left join on / left outer join on
SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id;
#多张表连接
SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id
LEFT JOIN table3 ON table2.id = table3.id;
left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。 左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL
4、 右连接 right join
部门表中不是所有部门都有人,想取出每个部门的信息,没有人的为null
关键字:right join on / right outer join on
SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id;
说明:right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
5、 交叉连接 CROSS JOIN
在 MySQL 中JOIN,CROSS JOIN、 和INNER JOIN是句法是等价(它们可以相互替换)。在标准 SQL 中,它们不是等价的。
select * from employee e CROSS JOIN dept d on e.dept_id=d.id;
等价于
select * from employee e INNER JOIN dept d on e.dept_id=d.id;
等价于
select * from employee e,dept d where e.dept_id=d.id;
四、 子查询
官网:https://dev.mysql.com/doc/refman/8.0/en/subqueries.html
1、什么是子查询
子查询:一个查询语句嵌套在另一个查询语句内部
在 MySQL 中,除了在 ORDER BY 列表中以外,在 SELECT、UPDATE、INSERT 和 DELETE 语句中任何可以使用表达式的地方都可以使用子查询来替代。
子查询特征
- 子查询的 SELECT 查询总是使用圆括号括起来。
- 子查询可以嵌套在外部 SELECT、INSERT、UPDATE 或 DELETE 语句的 WHERE 或 HAVING 子句内,或者其它子查询中。
- 根据可用内存和查询中其它表达式的复杂程度不同,嵌套限制也有所不同,嵌套到 32 层。
2、 子查询可出现的位置
| 位置 | 类型 | 说明 |
|---|---|---|
| select后面: | 仅仅支持标量子查询 | 作为一个字段值 |
| from后面: | 支持表子查询 | 作为一个临时表 |
| where或having后面: | 支持标量子查询(单行)、列子查询(多行)、行子查询 | 作为过滤条件 |
| exists后面(也被称为’相关子查询’) | 支持表子查询 |
标量子查询:就是指子查询的结果是“单个值”(一行一列)的查询
3、子查询的分类
从内查询返回结果的条目数
| 单行子查询 | 多行子查询 |
|---|---|
| 子查询结果只有一个数据 | 子查询数据返回多个 |
4、单行子查询
| 操作符 | 含义 |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
示例:取出所有大于平均工资的所有员工信息
普通方式:
select min(salary) from employee ;
select * from employee WHERE salary>6000
子查询方式
select * from employee WHERE salary>(select avg(salary) from employee);
-- 其它需求类同
select * from employee WHERE salary>(select min(salary) from employee);
select * from employee WHERE salary>(select salary from employee where emp_name='张三');
5、多行比较操作符
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
5.1、IN
取得等于每个部门最低工资的员工信息
select * from employee where salary in (select min(salary) from employee GROUP BY dept_id)
5.2、ANY
取得大于任意一个部门最低工资的员工信息
select * from employee where salary > ANY (select min(salary) from employee GROUP BY dept_id)
5.3、ALL
取得大于所有部门最低工资的员工信息
select * from employee where salary > ALL (select min(salary) from employee GROUP BY dept_id)
6、 相关子查询
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 .相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
7、EXISTS子查询
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
使用 EXISTS 关键字引入一个子查询时,就相当于进行一次存在测试。外部查询的 WHERE 子句测试子查询返回的行是否存在。子查询实际上不产生任何数据;它只返回 TRUE 或 FALSE 值。
使用 EXISTS 引入的子查询在以下几方面与其它子查询略有不同,EXISTS 关键字前面没有列名、常量或其它表达式。
示例: 取得部门中有员工的部门信息
select * from dept d where EXISTS (select * from employee e where d.id=e.dept_id );
-- 没有员工的部门信息
select * from dept d where NOT EXISTS (select * from employee e where d.id=e.dept_id );
-- 连接子查询, – 首先取得部门表中第一条数据的id, – 然后执行子查询中内容,如果子查询能够有满足条件的记录则返回true – 返回true,则把该部门信息放到结果集中 – 依次读取后面的数据,每条数据都要重新走一遍子查询
8、每个部门最低工资的员工信息
使用in时存在一个问题,当两个部门中有多个相同的工资值时会产生错误的结果,这时我们可以使用关联子查询来实现
select * from employee e ,(select dept_id,min(salary) as minsalry from employee where dept_id is not null group by dept_id) ee
where e.dept_id=ee.dept_id and e.salary=ee.minsalry
五、 MySQL分页
MySQL数据库实现分页比较简单,提供了LIMIT函数。一般只需要直接写到sql语句后面就行了。
1、 分页实现
select字段列表
from数据源
limit [start,]length;
start表示从第几行记录开始检索,length表示检索多少行记录。
表中第一行记录的start值为0。
示例:
select * from table WHERE … LIMIT 10; #返回前10行
该SQL语句等效于
select * from table WHERE … LIMIT 0,10; #返回前10行
select * from table WHERE … LIMIT 10,10; #返回第10-20行数据
2、分页优化(扩展)
问题:
对于limit 10000,20的意思扫描满足条件的10020行,扔掉前面的10000行,返回最后的20行。如果是limit 100000,100,需要扫描100100行,在一个高并发的应用里,每次查询需要扫描超过10W行,性能肯定大打折扣。limit n性能是没问题的,因为只扫描n行。
优化解决办法:
SELECT * FROM message WHERE id>=1000 ORDER BY id ASC LIMIT 20;//当前页
SELECT * FROM message WHERE id>1020 ORDER BY id ASC LIMIT 20;//下一页
SELECT * FROM message WHERE id<1000 ORDER BY id DESC LIMIT 20;//上一页
通过id来减少扫描
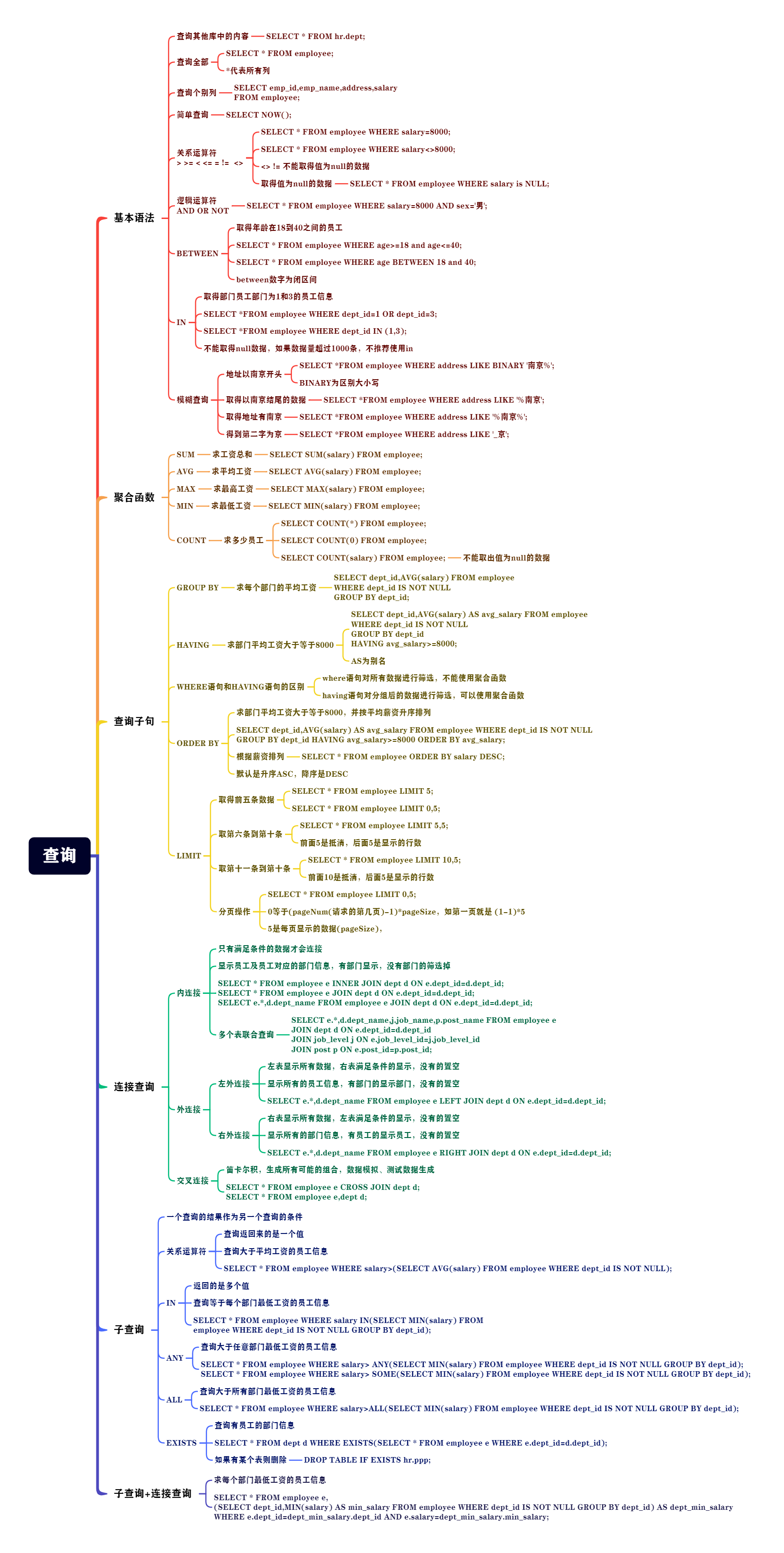
思维导图
本文来自博客园,作者:icui4cu,转载请注明原文链接:https://www.cnblogs.com/icui4cu/p/18818211

 浙公网安备 33010602011771号
浙公网安备 33010602011771号