python爬虫获取tap帖子
1.tap帖子数据获取
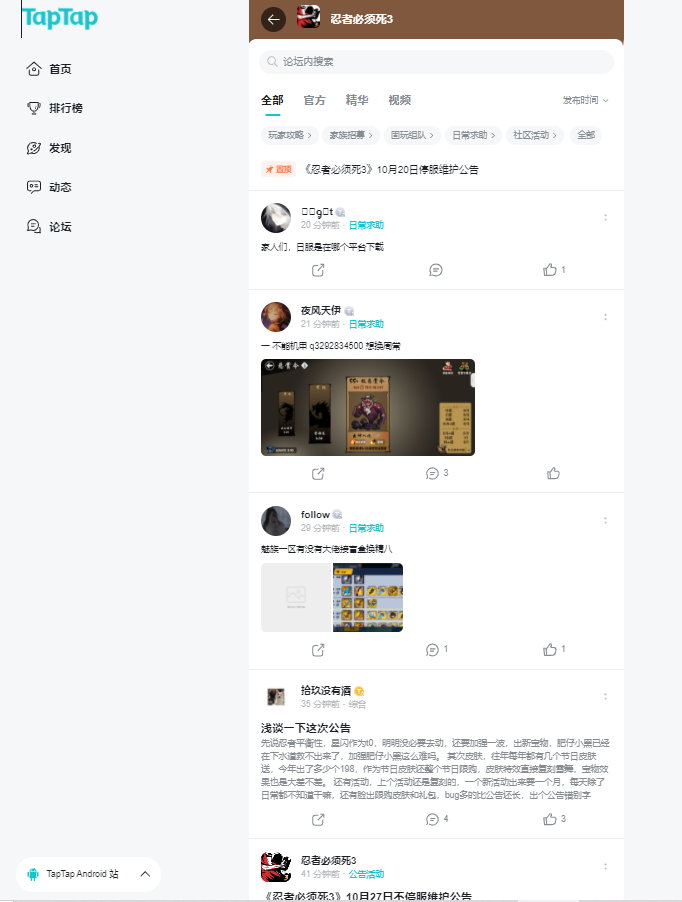
代码中cookie 为登陆后页面抓包的cookie,其中详情页需要3种拼接url,第一种是链接中含有topic,第二种中含有moment,第三种是视频,其中含有video
import requests
import json
import time
for data in range(0,20,10): #翻页,每加10翻一页
url = 'https://www.taptap.cn/webapiv2/feed/v6/by-group?from={}&group_id=61080&limit=10&sort=created&type=feed&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D93%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3D8c933580-fddc-48ac-ad5f-86caf48af0d8%26VID%3D119295298%26DT%3DPC'.format(data)
# url = 'https://www.taptap.com/webapiv2/feed/v6/by-group?from={}&group_id=61080&limit=10&sort=created&type=feed&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D92%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3Db60535e1-e107-4196-a819-8a37bdfdc90b%26VID%3D119295298%26DT%3DPC%26OS%3DWindows%26OSV%3D10'.format(data)
headers = {"accept": "application/json, text/plain, */*",
"cookie":"",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3928.4 Safari/537.36"
}
data = {
"group_id": "61080",
"type": "feed",
"sort": "created",
# "X-UA": "V=1&PN=WebApp&LANG=zh_CN&VN_CODE=92&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=b60535e1-e107-4196-a819-8a37bdfdc90b&VID=119295298&DT=PC&OS=Windows&OSV=10",
"X-UA": "V=1&PN=WebApp&LANG=zh_CN&VN_CODE=93&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=e71df365-69b0-4860-b76b-719ebd46ecd8&VID=119295298&DT=PC&OS=Windows&OSV=10"
}
json_ids = requests.get(url=url, headers=headers, data=data).json()
for dic in json_ids['data']['list']:
content_list = []
content = {}
timeStamp = dic['moment']['created_time']
# for timeStamp in timeStamp_list:
# timeStamp = 1665801067 # 10位时间戳
# timeStamp_13 = 1381419600234# 13位时间戳
timeArray = time.localtime(timeStamp) # 转化成对应的时间
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) # 字符串
content['date'] = otherStyleTime
content['athourr'] = dic['moment']['author']['user']['name']
# content['contentatr'] = dic['moment']['contents']['raw_text']
adresss = dic['moment']['author']['user']['id']
content['adress'] = str(adresss)
idstrs = dic['moment']['id_str']
personurl = 'https://www.taptap.com/moment/' + idstrs
content['url'] = personurl
idstress = dic['moment']['complaint']['web_url']
if "topic" in idstress:
# url1 = 'https://www.taptap.com/webapiv2/moment/v2/detail?id='+idstrs+'&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D92%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3Db60535e1-e107-4196-a819-8a37bdfdc90b%26VID%3D119295298%26DT%3DPC%26OS%3DWindows%26OSV%3D10'
idstresss = idstress.replace('/complaint?id=','').replace('&type=topic','')
idstressss = str(idstresss)
print(idstressss)
url1 = 'https://www.taptap.cn/webapiv2/topic/v1/detail?id='+idstressss+'&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D93%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3De71df365-69b0-4860-b76b-719ebd46ecd8%26VID%3D119295298%26DT%3DPC%26OS%3DWindows%26OSV%3D10'
elif "video" in idstress:
idstrel = idstress.replace('/complaint?id=', '').replace('&type=video', '')
idstresl = str(idstrel)
print(idstresl)
url1 ='https://www.taptap.cn/webapiv2/video/v2/detail?id='+idstresl+'&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D93%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3D8c933580-fddc-48ac-ad5f-86caf48af0d8%26VID%3D119295298%26DT%3DPC'
else:
# url1 = 'https://www.taptap.cn/webapiv2/topic/v1/detail?id='+idstress+'&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D93%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3De71df365-69b0-4860-b76b-719ebd46ecd8%26VID%3D119295298%26DT%3DPC%26OS%3DWindows%26OSV%3D10'
url1 = 'https://www.taptap.cn/webapiv2/moment/v2/detail?id=' + idstrs + '&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D93%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3De71df365-69b0-4860-b76b-719ebd46ecd8%26VID%3D119295298%26DT%3DPC%26OS%3DWindows%26OSV%3D10'
# print(url1)
headers = {"accept": "application/json, text/plain, */*",
"cookie": "",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3928.4 Safari/537.36"
}
datas = {
"id": idstrs,
"X-UA": "V=1&PN=WebApp&LANG=zh_CN&VN_CODE=92&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=b60535e1-e107-4196-a819-8a37bdfdc90b&VID=119295298&DT=PC&OS=Windows&OSV=10",
}
result1 = requests.get(url=url1, headers=headers, data=datas).json()
print(url1)
content['atricalll'] = result1['data']['moment']['sharing']['title'].replace('\n','').replace(' ','')
content['atricallll'] = result1['data']['moment']['sharing']['description'].replace('\n','').replace(' ','')
# print(atricalll,atricallll)
content_list.append(content)
print(content_list)
with open('taptap.csv','a', encoding='utf-8') as f:
for content in content_list:
f.write(content['date'] + ',' + content['athourr']+ ','+content['adress'] + ',' + content['url'] + ','+content['atricalll'] + ',' + content['atricallll']+ '\n')
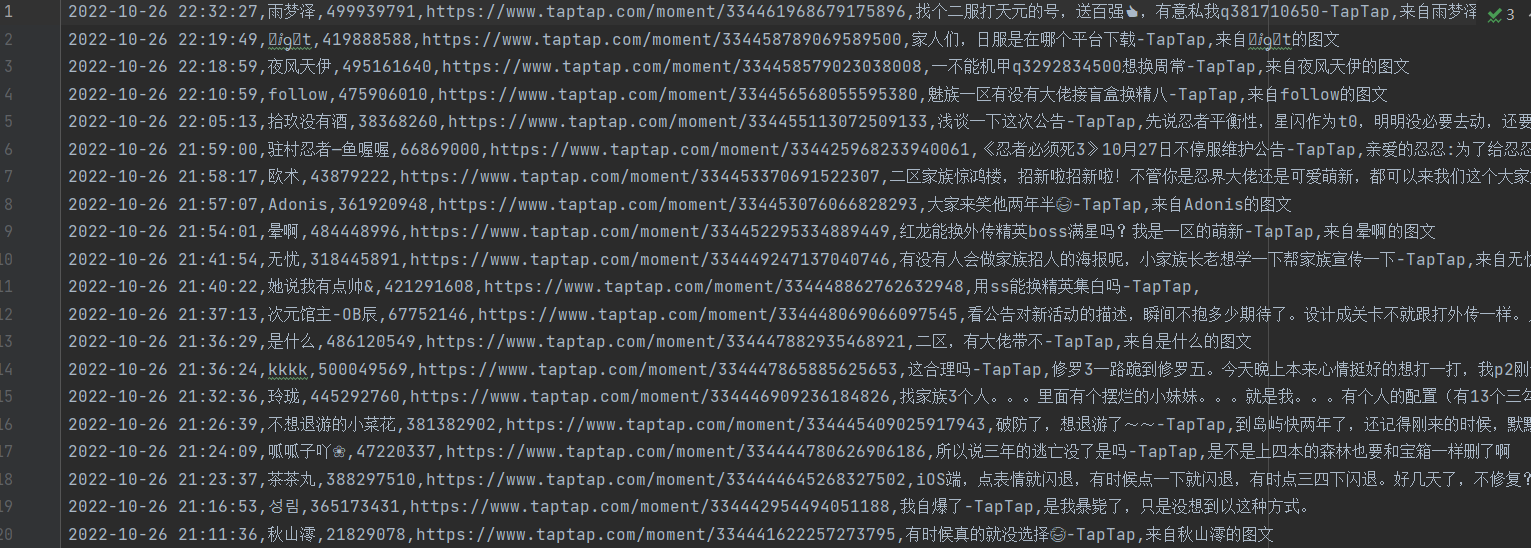
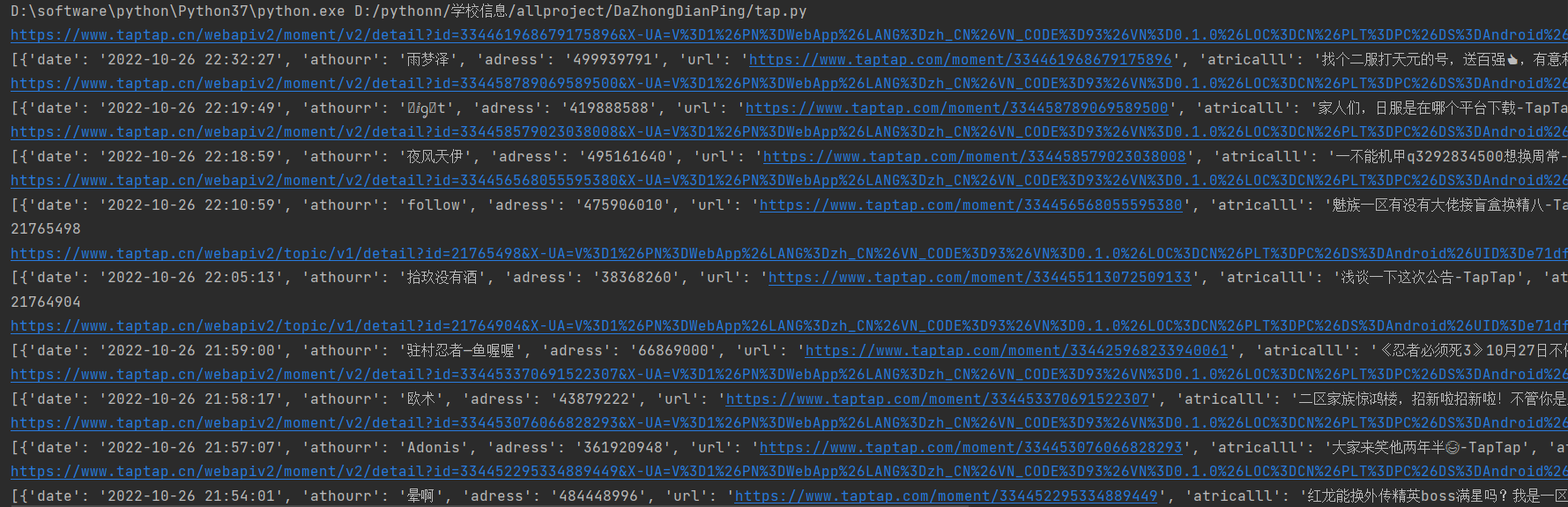
2.运行后数据展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号