python爬虫破解css加密之大众点评
文章目录
本文参考了多篇文章,如有侵权请联系qq3294575459,文章及代码会及时删除
声明:代码仅供学习参考,请勿用于非法数据爬取
‘’’
项目难点:css字体加密反爬、且不定时切换两套不同的反爬机制
项目开发过程:
反爬种类一: svg字体反爬
解决过程:抓取css文件中的svg文件,解析svg文件,根据x,y偏移量可计算出文字在SVG源文件的索引值,再生成映射关系字典,替换被修改的字体。
反爬种类二: woff字体反爬
解决过程:抓取css文件中的woff文件,用FFfont库以及第三方图片识别接口解析woff文件,生成文字映射关系字典,再做替换。
‘’’
本篇文章使用的第二种woff字体反爬
url:https://www.dianping.com/
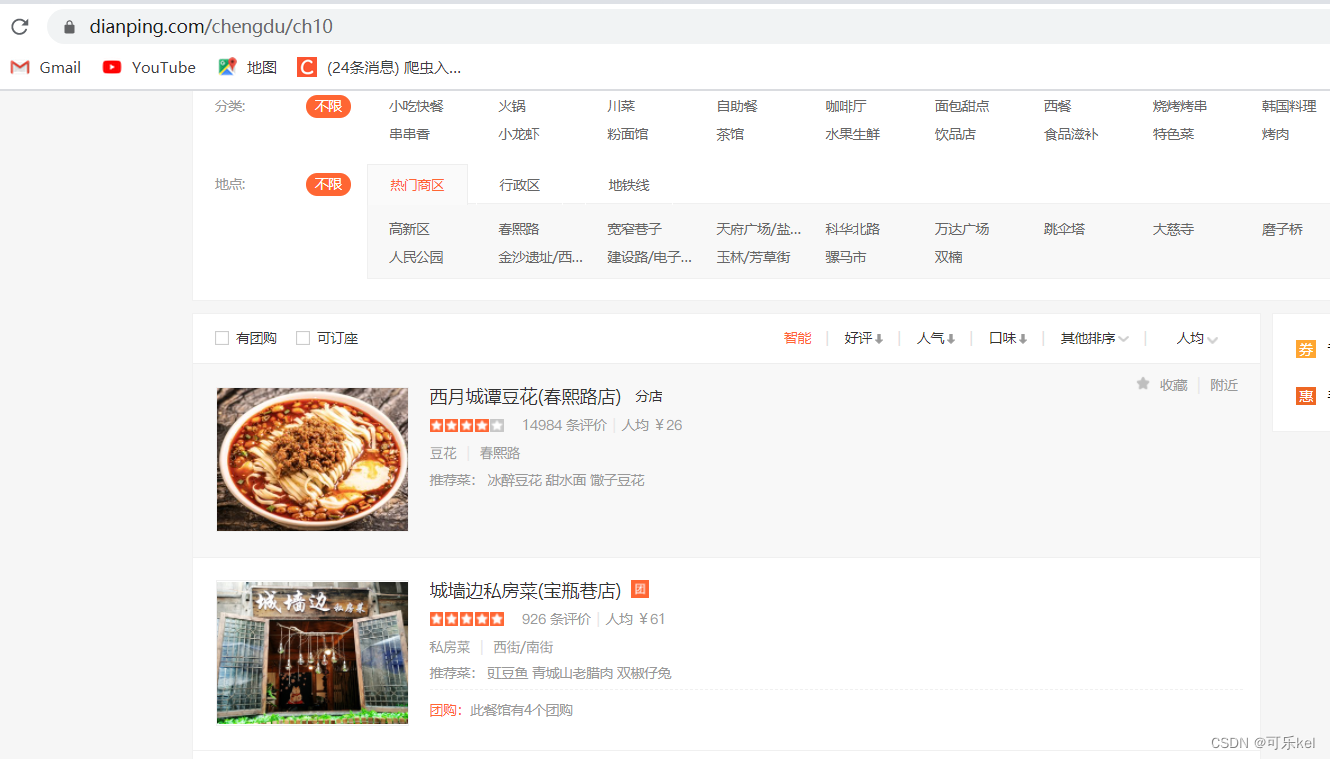
F12,打开开发者模式
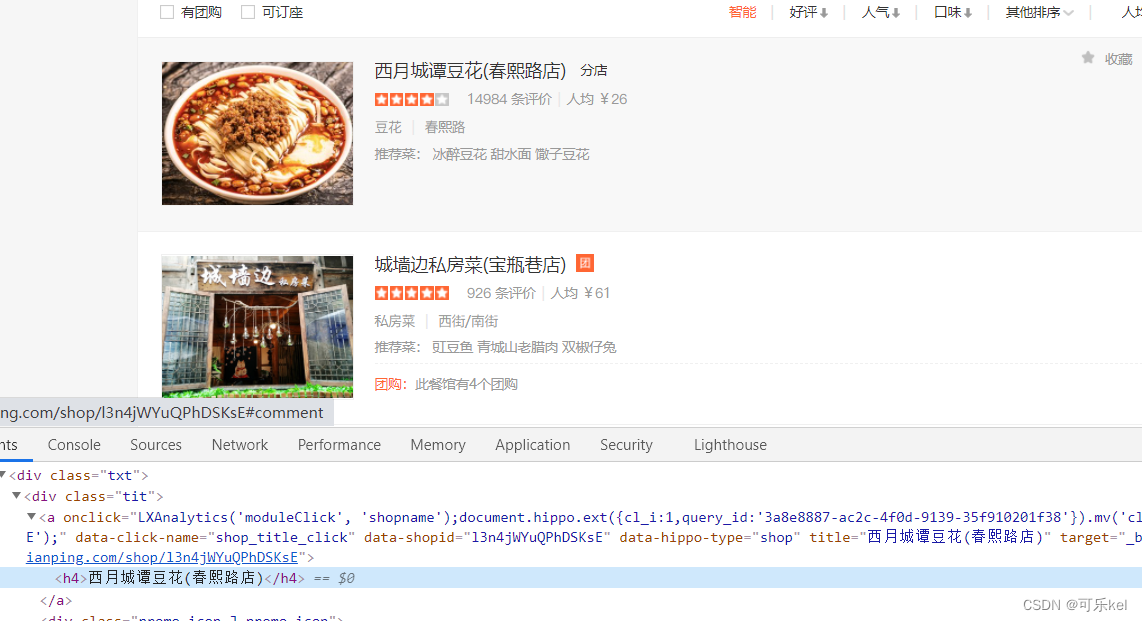
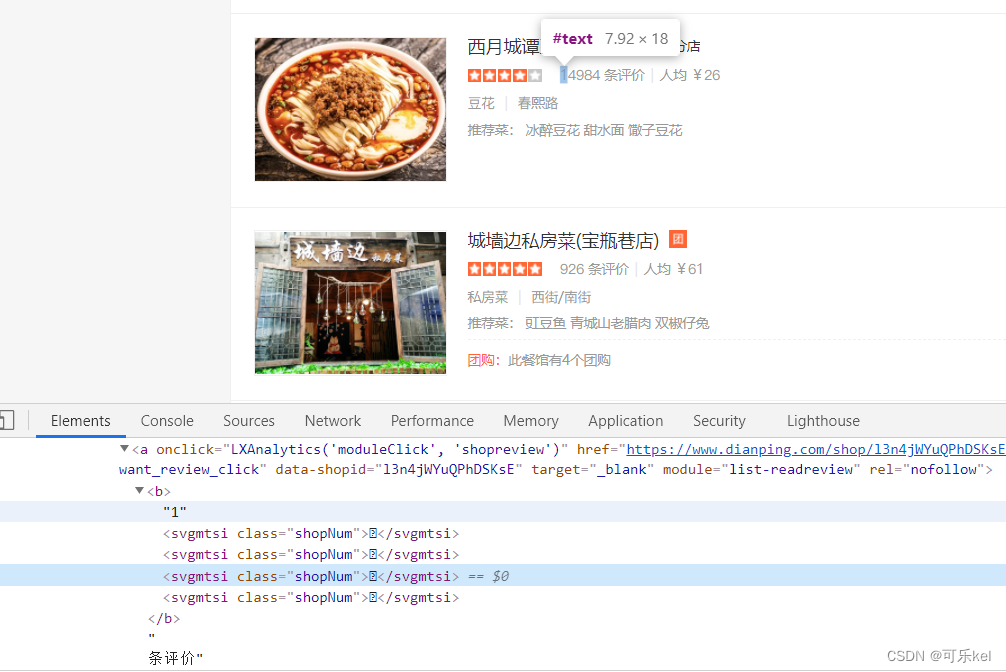
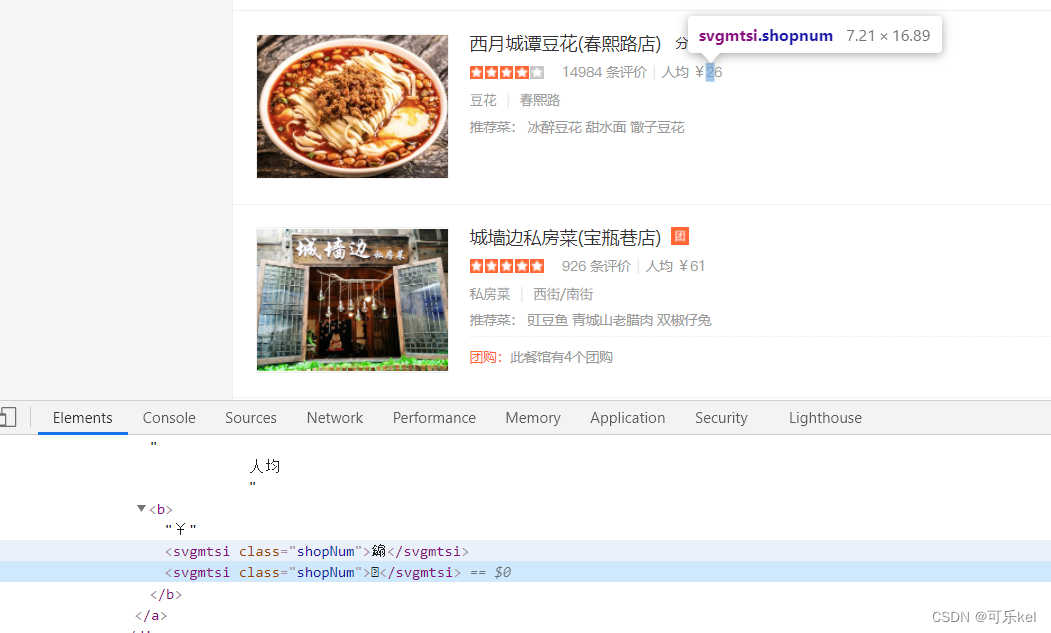
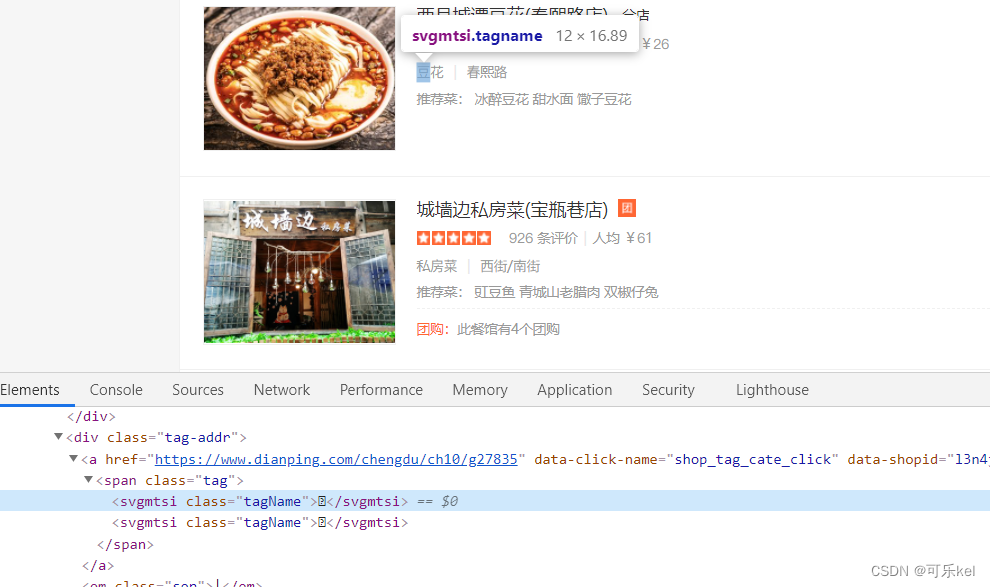
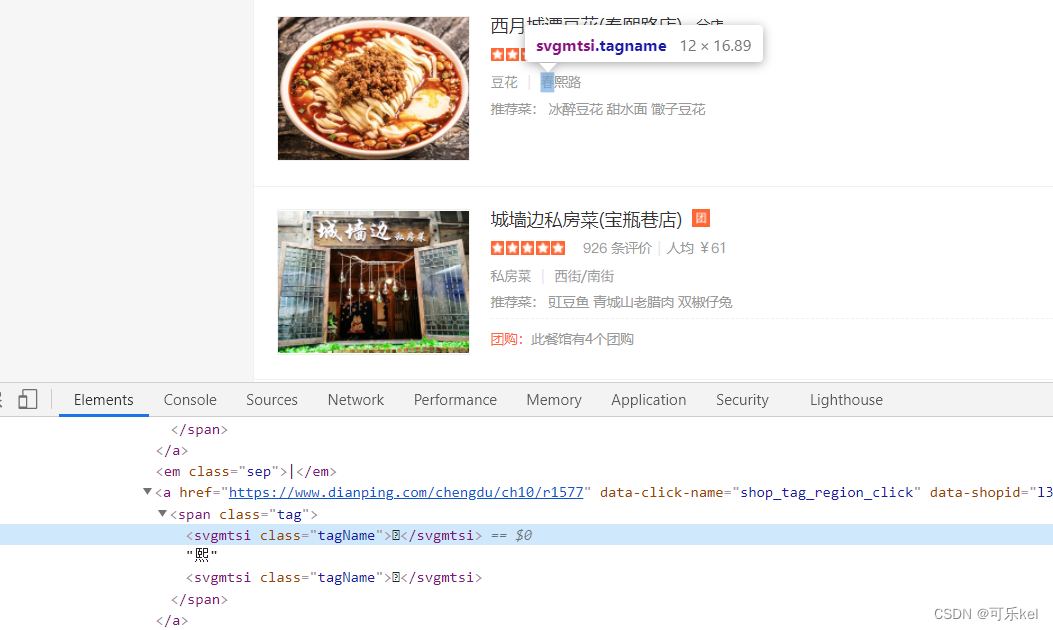
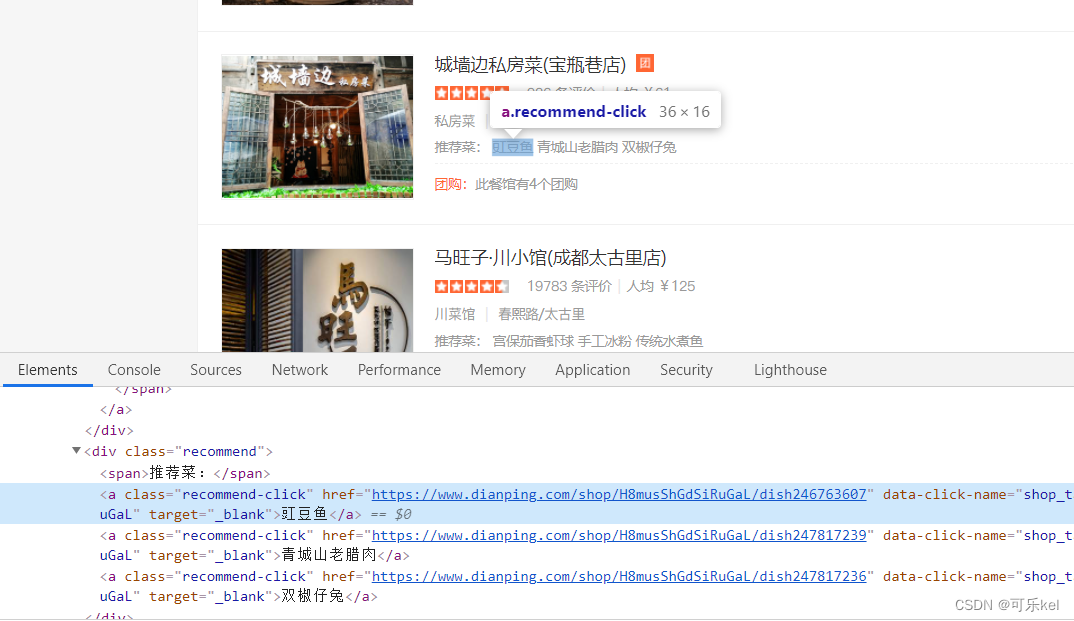
我们通过开发者选项看到的特殊符号其实是一种字体,是大众点评专门加密的一种CSS字体。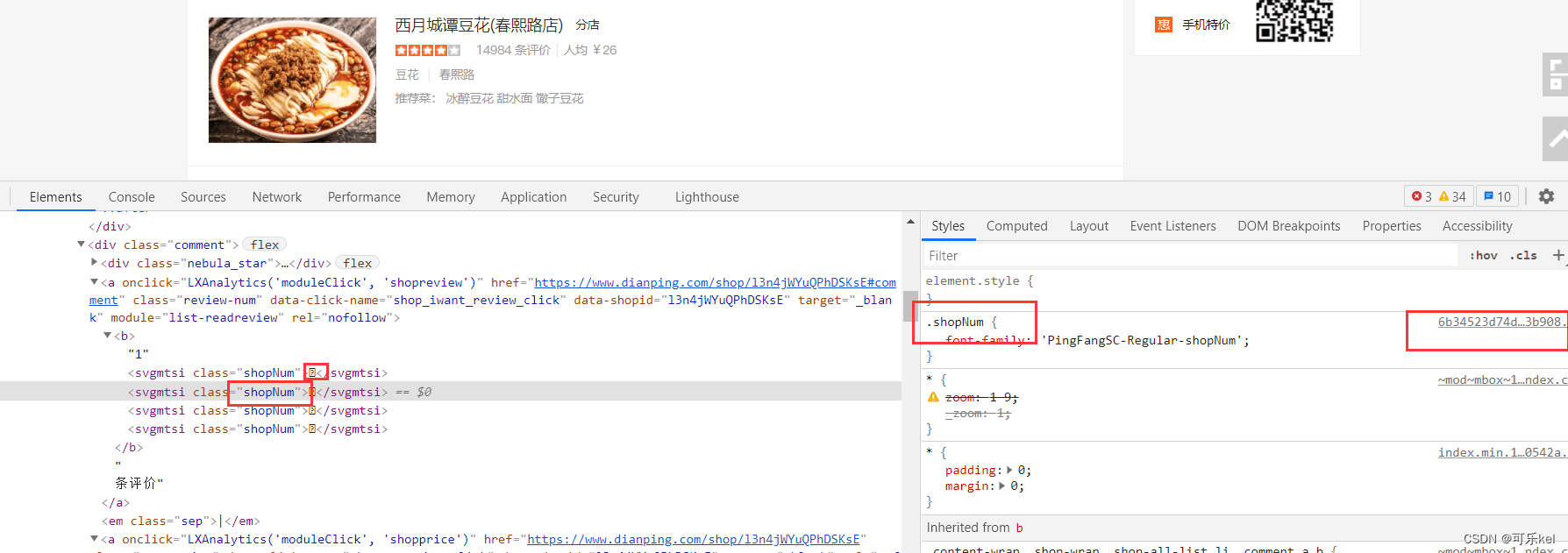
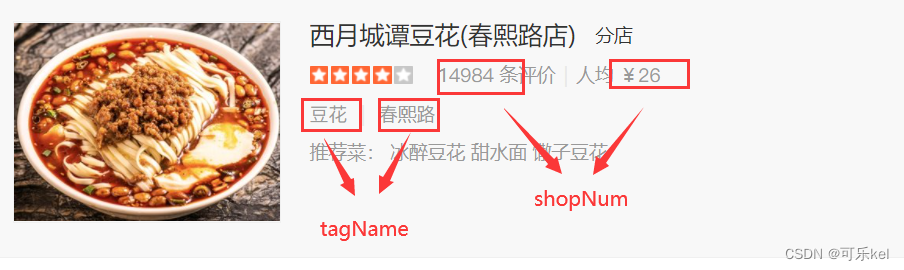
通过上述源码与图片对比,我们可以看出,大众点评的自定义字体初步判断为两个。
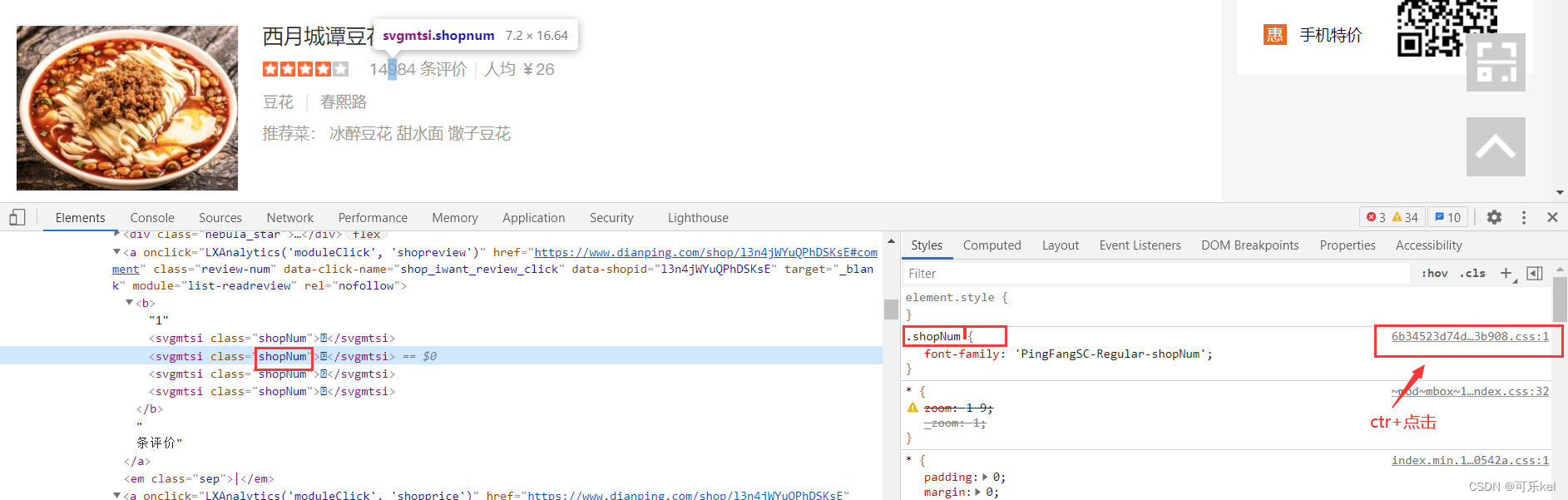
ctr+鼠标点击 进入到css文件中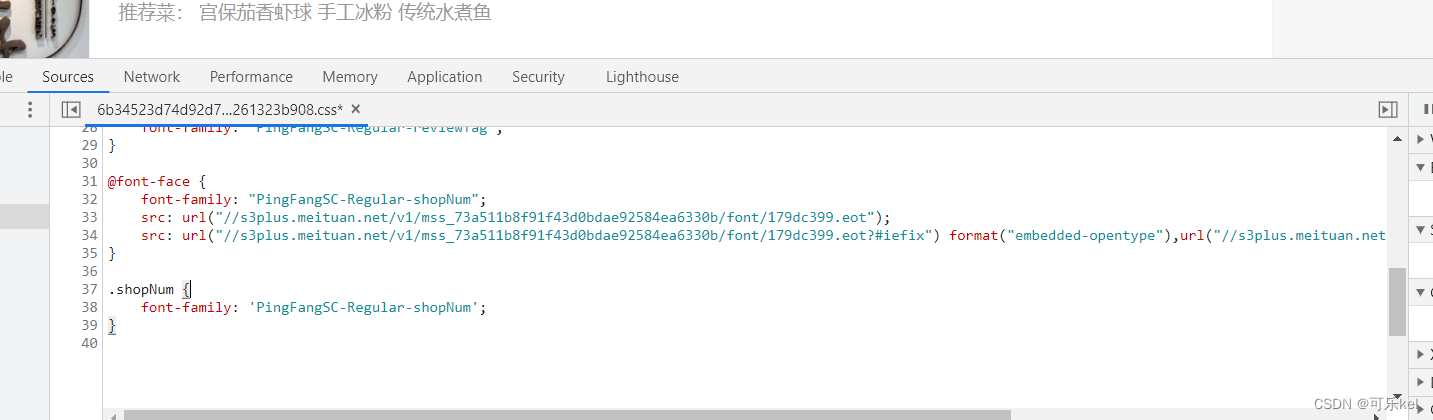
我们可以得知css文件的网址,接下来就是在源代码中找出,并提取出来。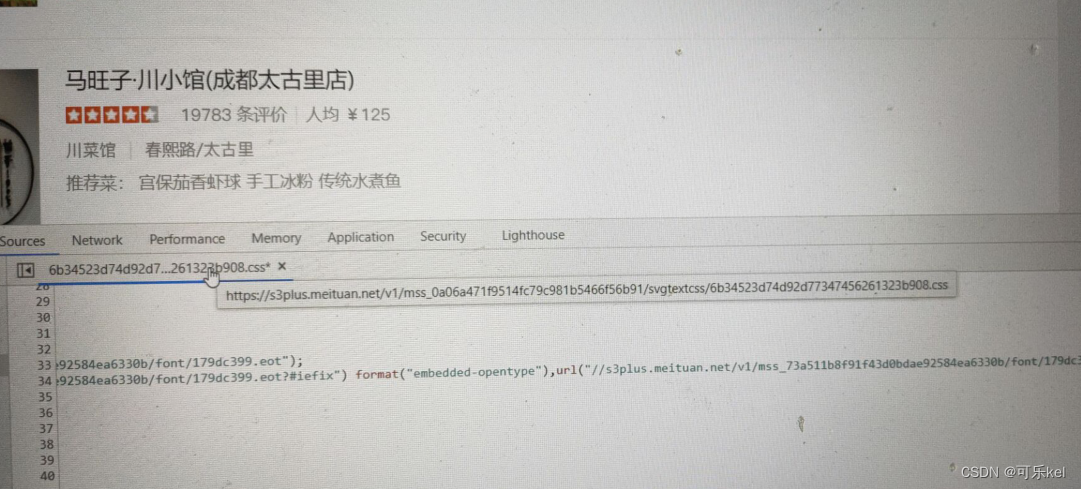
首先进行抓包,可以在工具栏进行搜索,找出所在的包。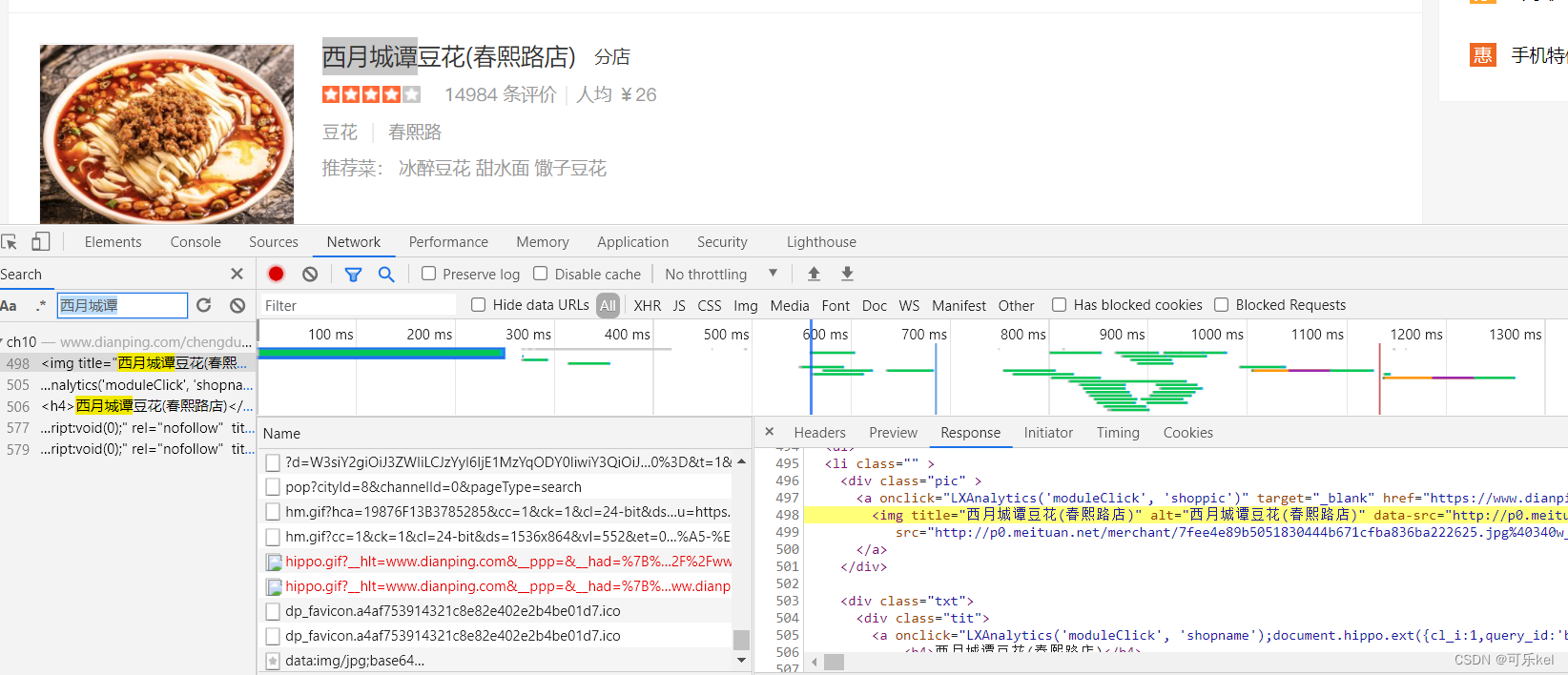
在源码栏里搜索.css,找出所对应的源码,可以看出,这就是我们想要的css文件的url。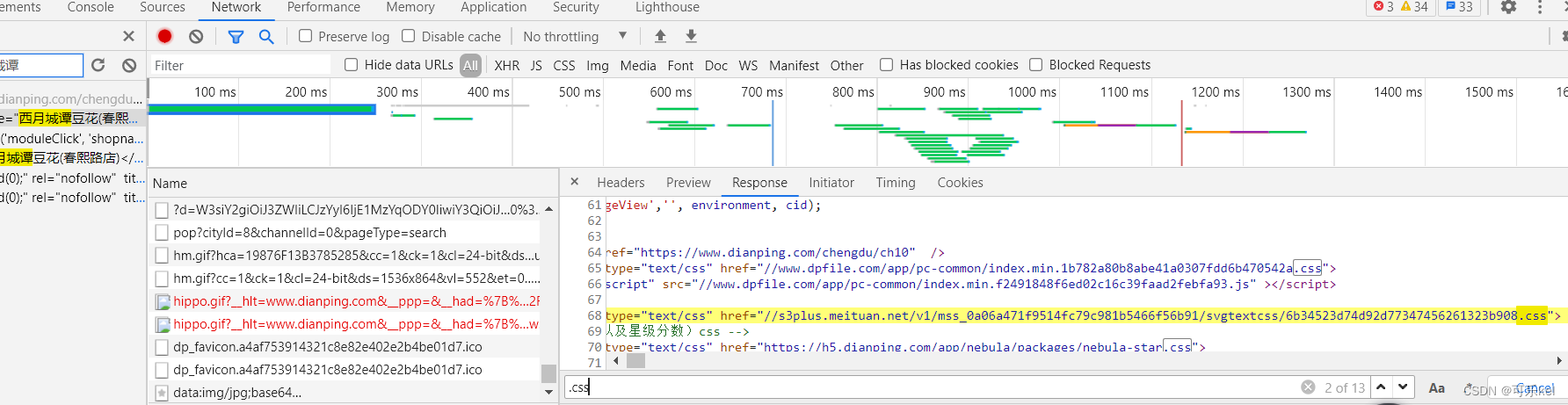
我们用正则表达式进行提取,然后进行拼接
page = requests.get(url=url, headers=headers).content.decode('utf-8') # 请求页面
ex = '<link rel="stylesheet" type="text/css" href="//s3plus.meituan.net/v1/(.*?).css">'
pattern = re.compile(ex)
css = pattern.findall(page)[0] # 提取css地址
cssUrl = f'http://s3plus.meituan.net/v1/{css}.css'
我们可以看出,下面的url就是我们想要的woff字体文件的下载地址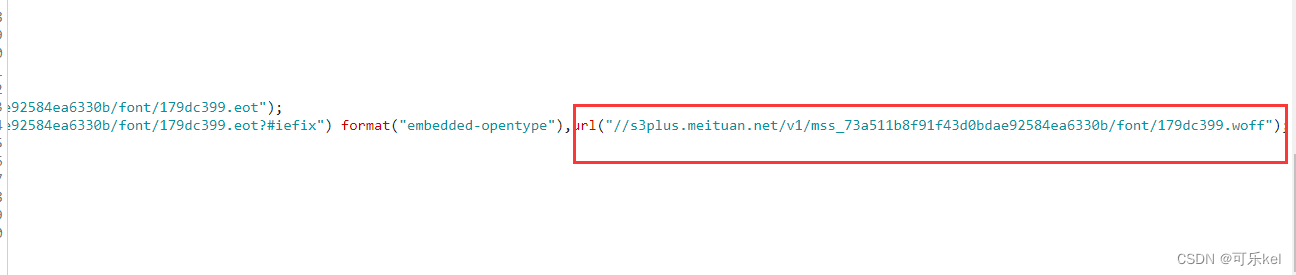
接下来用正则提取shopNum和tagName的网址
ex = ',url\("\/\/s3plus\.meituan\.net\/(.*?)\.woff'
pattern = re.compile(ex)
woffLs = pattern.findall(cssTxt.split('.tagName')[0]) # 提取woff地址
tagName = 'http://s3plus.meituan.net/' + woffLs[-1] + '.woff'
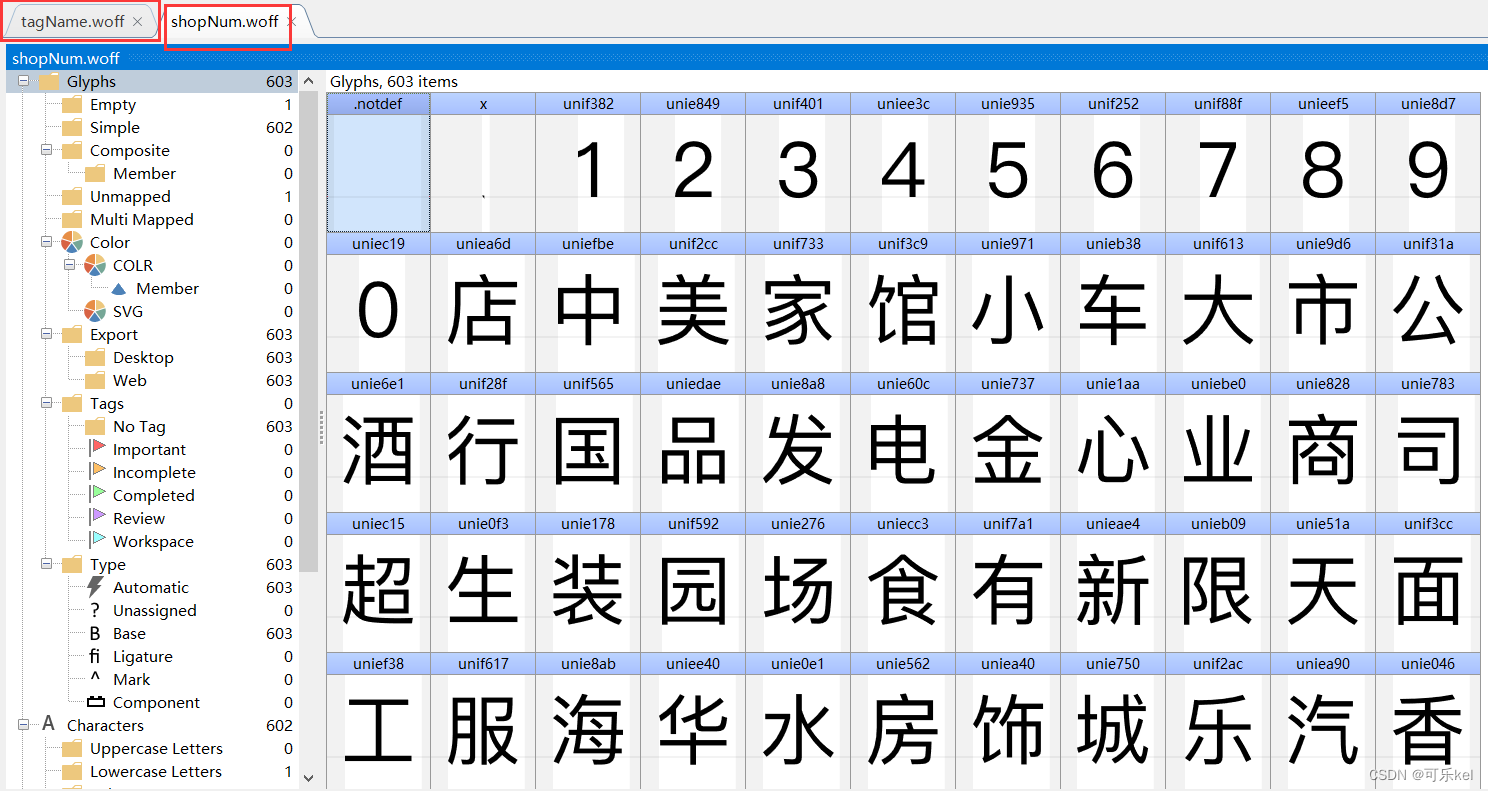
这就是我们下载的两个字体文件
words = '1234567890店中美家馆小车大市公酒行国品发电金心业商司超生装园场食有新限天面工服海华水房饰城乐汽香部利子老艺花专东肉菜学福饭人百餐茶务通味所山区门药银农龙停尚安广鑫一容动南具源兴鲜记时机烤文康信果阳理锅宝达地儿衣特产西批坊州牛佳化五米修爱北养卖建材三会鸡室红站德王光名丽油院堂烧江社合星货型村自科快便日民营和活童明器烟育宾精屋经居庄石顺林尔县手厅销用好客火雅盛体旅之鞋辣作粉包楼校鱼平彩上吧保永万物教吃设医正造丰健点汤网庆技斯洗料配汇木缘加麻联卫川泰色世方寓风幼羊烫来高厂兰阿贝皮全女拉成云维贸道术运都口博河瑞宏京际路祥青镇厨培力惠连马鸿钢训影甲助窗布富牌头四多妆吉苑沙恒隆春干饼氏里二管诚制售嘉长轩杂副清计黄讯太鸭号街交与叉附近层旁对巷栋环省桥湖段乡厦府铺内侧元购前幢滨处向座下臬凤港开关景泉塘放昌线湾政步宁解白田町溪十八古双胜本单同九迎第台玉锦底后七斜期武岭松角纪朝峰六振珠局岗洲横边济井办汉代临弄团外塔杨铁浦字年岛陵原梅进荣友虹央桂沿事津凯莲丁秀柳集紫旗张谷的是不了很还个也这我就在以可到错没去过感次要比觉看得说常真们但最喜哈么别位能较境非为欢然他挺着价那意种想出员两推做排实分间甜度起满给热完格荐喝等其再几只现朋候样直而买于般豆量选奶打每评少算又因情找些份置适什蛋师气你姐棒试总定啊足级整带虾如态且尝主话强当更板知己无酸让入啦式笑赞片酱差像提队走嫩才刚午接重串回晚微周值费性桌拍跟块调糕'
def build_dict(font_file, words):
# 传入woff文件名与words字序
font = TTFont('{}.woff'.format(font_file))
lis = font.getGlyphOrder()[2:] # 删去前两个字符
dic = {} # 构建解密字典
for index, value in enumerate(words):
string = lis[index].replace('uni', '\\u') # 替换font中的uni为\u以便于后续解密
dic[json.loads(f'"{string}"')] = value
return dic
从上面查看的woff文件中,我们可以看到开头两个是空白的,所以要去掉,之后对words建立索引,源码中"美"字\uf2cc,而woff文件中是unif2cc,所以要进行替换,从而进行解密。
import requests
from fontTools.ttLib import TTFont
from lxml import etree
from time import sleep
import pandas as pd
import json
import re
def build_dict(font_file, words):
# 传入woff文件名与words字序
font = TTFont('{}.woff'.format(font_file))
# font.saveXML('{}.xml'.format(font_file)) 可保存为xml格式
lis = font.getGlyphOrder()[2:] # 删去前两个字符
dic = {} # 构建解密字典
for index, value in enumerate(words):
string = lis[index].replace('uni', '\\u') # 替换font中的uni为\u以便于后续解密
dic[json.loads(f'"{string}"')] = value
return dic
def collect(url, cookie):
# 抓取url对应页面
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Cookie': cookie,
'Host': 'www.dianping.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/91.0.4472.114Safari/537.36Edg/91.0.864.54'
}
response = requests.get(url=url, headers=headers).text
return response
def decrypt(word_list, dic):
# 利用解密解密字典对加密字符进行解码
res = ''
for word in word_list:
res += dic.get(word, word) # 在解密字典中查询加密字符
return res
def analyse(page, font_dict):
# 解析页面数据
tree = etree.HTML(page)
shop_list = [] # 创建数据列表
for li in tree.xpath('//div[@id="shop-all-list"]/ul/li'): # 分别解析li标签
try:
name = li.xpath('.//div[@class="tit"]/a/h4/text()')[0] # 店名
except IndexError:
name = ''
price = li.xpath('.//div[@class="comment"]/a[2]/b//text()') # 人均消费
area = li.xpath('.//div[@class="tag-addr"]/a[2]/span//text()') # 地区
comment = li.xpath('.//div[@class="comment"]/a[1]/b//text()') # 评价数
try:
total_score = eval(li.xpath('.//div[@class="nebula_star"]/div/span/@class')[0].split()[1].split('_')[-1]) / 10 # 评分
except IndexError:
total_score = ''
kind = li.xpath('.//div[@class="tag-addr"]/a[1]/span//text()') # 类型
recommend = li.xpath('.//div[@class="recommend"]/a//text()') # 推荐菜
# 创建店铺字典
shop_dict