
分表分库解决方案(mycat,tidb,shardingjdbc)
公司最近有分表分库的需求,所以整理一下分表分库的解决方案以及相关问题。
1.sharding-jdbc(sharding-sphere)
优点:
1.可适用于任何基于java的ORM框架,如:JPA、Hibernate、Mybatis、Spring JDBC Template,或直接使用JDBC
2.可基于任何第三方的数据库连接池,如:DBCP、C3P0、Durid等
3.分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
4.SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
5.性能高,单库查询QPS为原生JDBC的99.8%,双库查询QPS比单库增加94%。
缺点:
1.理论上可支持任意实现JDBC规范的数据库。目前仅支持mysql
2.维护会比较麻烦,需要逐个项目的修改配置。不能进行跨库连接,代码需要进行改造。
3.在扩展数据库服务器时需要考虑一致性哈希问题,或者采用分片键局部取模方式,也难免要进行部分的数据迁移。
2.mycat
优点:
1.支持Mysql集群,可以作为Proxy使用
2.支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用
3.自动故障切换,高可用性
4.支持读写分离,支持Mysql双主多从,以及一主多从的模式 ,支持全局表,数据自动分片到多个节点,用于高效表关联查询
5.支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询
6.多平台支持,部署和实施简单
缺点:
1.mycat不支持二维路由,仅支持单库多表或多库单表 由于自定义连接池,这样就会存在mycat自身维护一个连接池,MySQL也有一个连接池,任何一个连接池上限都会成为性能的瓶。
3.tidb
优点:
1 .高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
2.水平弹性扩展 通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
3.分布式事务 TiDB 100% 支持标准的 ACID 事务。
4. 真正金融级高可用 相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
5 .一站式 HTAP 解决方案 TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP解决方案,一份存储同时处理OLTP & OLAP无需传统繁琐的 ETL 过程。
6.云原生 SQL 数据库 TiDB 是为云而设计的数据库,同 Kubernetes深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
缺点: 该项目较新,还没有经过大量的生产环境检验,可能会存在一定的风险。
不适用场景:
(1) 单机 MySQL 能满足的场景也用不到 TiDB。
(2) 数据条数少于 5000w 的场景下通常用不到 TiDB,TiDB 是为大规模的数据场景 设计的。
(3)如果你的应用数据量小(所有数据千万级别行以下),且没有高可用、强一致性或 者多数据中心复制等要求,那么就不适合使用 TiDB。
下面详细讲一下mycat,因为部署和对系统的改造量相对较小,但实测mycat的网络消耗和线程池的问题对性能的消耗还是挺严重的,所以还是根据现有情况选择。
mycat
1.架构
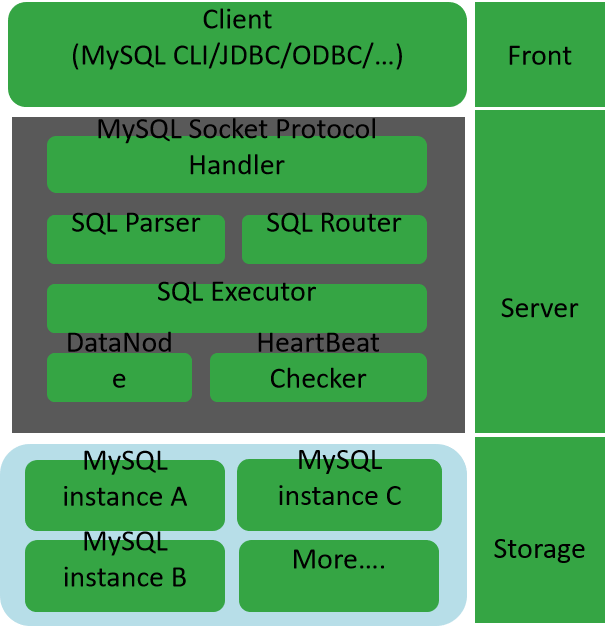
如图所示:MyCAT使用Mysql的通讯协议模拟成了一个Mysql服务器,并建立了完整的Schema(数据库)、Table (数据表)、User(用户)的逻辑模型,并将这套逻辑模型映射到后端的存储节点DataNode(MySQL Instance)上的真实物理库中,这样一来,所有能使用Mysql的客户端以及编程语言都能将MyCAT当成是Mysql Server来使用,不必开发新的客户端协议。
2.工作原理
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
当Mycat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字段的值,并匹配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以select * from Orders where prov=?语句为例,查到prov=wuhan,按照分片函数,wuhan返回dn1,于是SQL就发给了MySQL1,去取DB1上的查询结果,并返回给用户。
3.分片策略(分表分库)
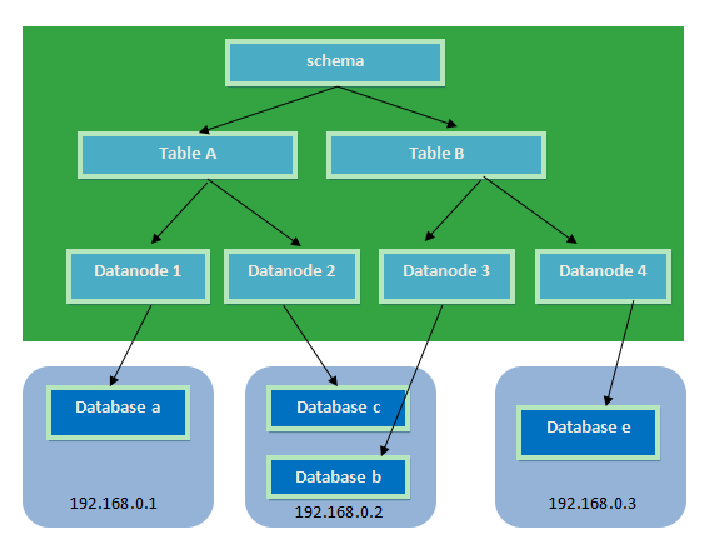
MyCAT通过定义表的分片规则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法。
1、Schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
2、Table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode。在此可以指定表的分片规则。
3、DataNode:MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上
4、DataSource:定义某个物理库的访问地址,用于捆绑到Datanode上
4.分片规则
1.分片枚举 通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则.
2.固定分片 hash 算法 本条规则类似于十进制的求模运算,区别在于是二进制的操作,是取 id 的二进制低 10 位,即 id 二进制 &1111111111。 此算法的优点在于如果按照 10 进制取模运算,在连续插入 1-10 时候 1-10 会被分到 1-10 个分片,增大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。
3.按日期分片 此规则为按天分片。 按单月小时拆分 此规则是单月内按照小时拆分,最小粒度是小时,可以一天最多 24 个分片,最少 1 个分片,一个月完后下月从头开始循环。每个月月尾,需要手工清理数据。 4.截取数字 hash 解析 此规则是截取字符串中的 int 数值 hash 分片。 5.日期范围 hash 分片 思想与范围求模一致,当由于日期在取模会有数据集中问题,所以改成 hash 方法。 先根据日期分组,再根据时间 hash 使得短期内数据分布的更均匀。 优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题。要求日期格式尽量精确些,不然达不到局部均匀的目的
6.一致性 hash 一致性哈希主要应用于分布式集群对机器添加、删除的管理 1 按照常用hash算法将要管理的对象映射到一个2^32-1的闭合环形上 2 按照常用hash算法将机器映射也映射到此闭合环形上 3 以顺时针计算,将要管理的对象纳入离自己最近的机器上
4.删除节点时,该机器存储的对象按照顺时针就近原理分配到临近机器上
5.增加节点时,按照哈希算法获得机器hash值,然后把临近对象分配到该节点
6. 通过虚拟节点方式,增加hash环节点的密集度,保障平衡性 特性: 1 平衡性:各节点的对象个数相对均衡 2 单调性:新对象加入时不影响原对象的存储位置 3 分散性:相同内容会被分散到相同节点 4 负载:同一个节点不能被不同用户映射不同内容
5.读写分离
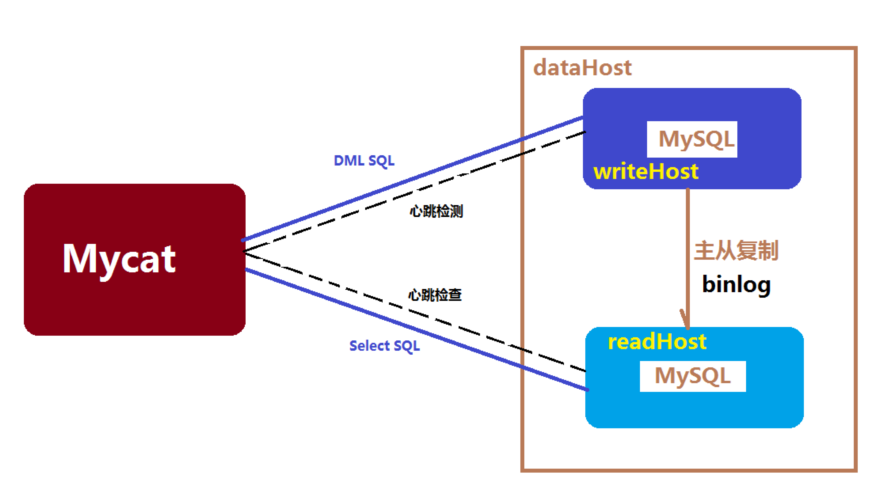
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个读节点的配置 Mycat读写分离和自动切换机制,需要mysql的主从复制机制配合。
6.mysql主从复制
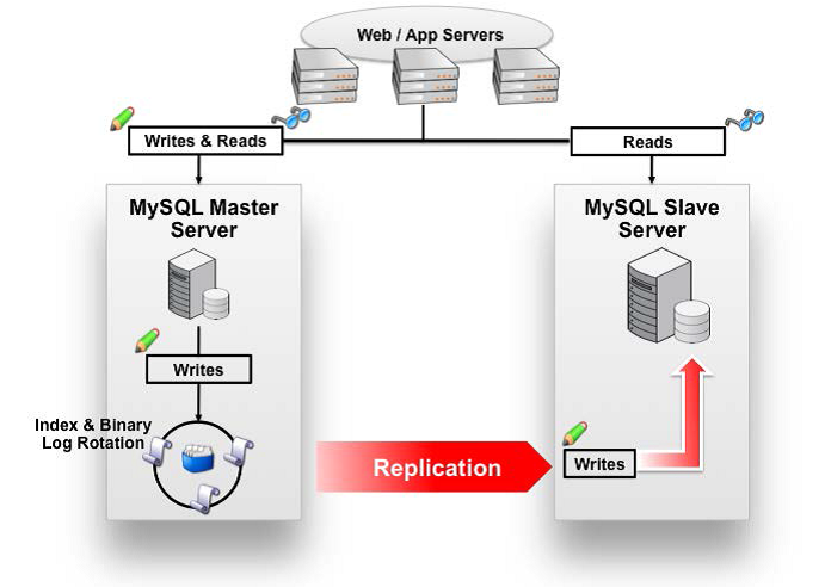
1、主DB server和从DB server数据库的版本一致
2、主DB server和从DB server数据库数据一致[ 这里就会可以把主的备份在从上还原,也可以直接将主的数据目录拷贝到从的相应数据目录]
3、主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一
7.mycat分布式事务解决方案
准备阶段:事务协调者(事务管理器)给每个参与者(资源管理器)发送准备消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志但不提交,可以进一步将准备阶段分为以下三个步骤: 1)协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。 2)参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。 3)各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。 提交阶段:如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息,否则发送提交(Commit)消息,参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。 二阶段提交所存在缺点的: 1)同步阻塞问题,执行过程中所有参与节点都是事务阻塞型的,当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。 2)单点故障,由于协调者的重要性一旦协调者发生故障参与者会一直阻塞下去。 3)数据不一致,在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求,而在这部分参与者接到commit请求之后就会执行commit操作,但是其他部分未接到commit请求的机器则无法执行事务提交,于是整个分布式系统便出现了数据部一致性的现象。
8.mycat不适用场景
1.非分片字段查询 如果该分片字段选择度高,也是业务常用的查询维度,一般只有一个或极少数个DB节点命中(返回结果集)。示例中只有3个DB节点,而实际应用中的DB节点数远超过这个,假如有50个,那么前端的一个查询,落到MySQL数据库上则变成50个查询,会极大消耗Mycat和MySQL数据库资源。
2.分页排序 但Mycat向应用返回的结果集取决于哪个DB节点最先返回结果给Mycat。如果Mycat最先收到DB1节点的结果集,那么Mycat返回给应用端的结果集为 [0,1],如果Mycat最先收到DB2节点的结果集,那么返回给应用端的结果集为 [5,6]。也就是说,相同情况下,同一个SQL,在Mycat上执行时会有不同的返回结果。
3.任意表JOIN 无法跨库join
4.分布式事务 Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的 弱XA事务


 浙公网安备 33010602011771号
浙公网安备 33010602011771号