【MySQL之轨迹】查询语句归纳总结合集
—— 归纳总结 ——
◉ 序 & 热身
复习复习复习复习复习复习ohhhhhhhhhhh!!!!
- SQL语句不区分大小写,仅仅是在关键字上不区分
- 推荐使用大写,小写也是可以的
- 有字符串的地方需用单引号 ‘…’ 括起来,而不能用双引号
- 星号 * 代表所有字段名
- 在字段名后面 + 空格 / AS + 字符串,可以给该字段重命名
◉ 一条完整的查询语句
关键字 内容 执行顺序
————————————————————————————————
SELECT ... 5
FROM ... 1
WHERE ... 2
GROUP BY ... 3
HAVING ... 4
ORDER BY ... 6
LIMIT ... 7
解释:
(FROM) 从 xx 表中取出 (WHERE) 有 xx 属性的
(GROUP BY) 按 xx 分组,(HAVING) 再过滤出有 xx 属性的
(SELECT) 然后进行查询
(ORDER BY) 之后按照 xx 排序,(LIMIT) 再选出 xx 条数据
注意点:
SELECT和FROM必须出现- 必须有
GROUP BY出现,HAVING才能出现 - 由于
GROUP BY在WHERE之后出现,WHERE后不能直接跟分组函数
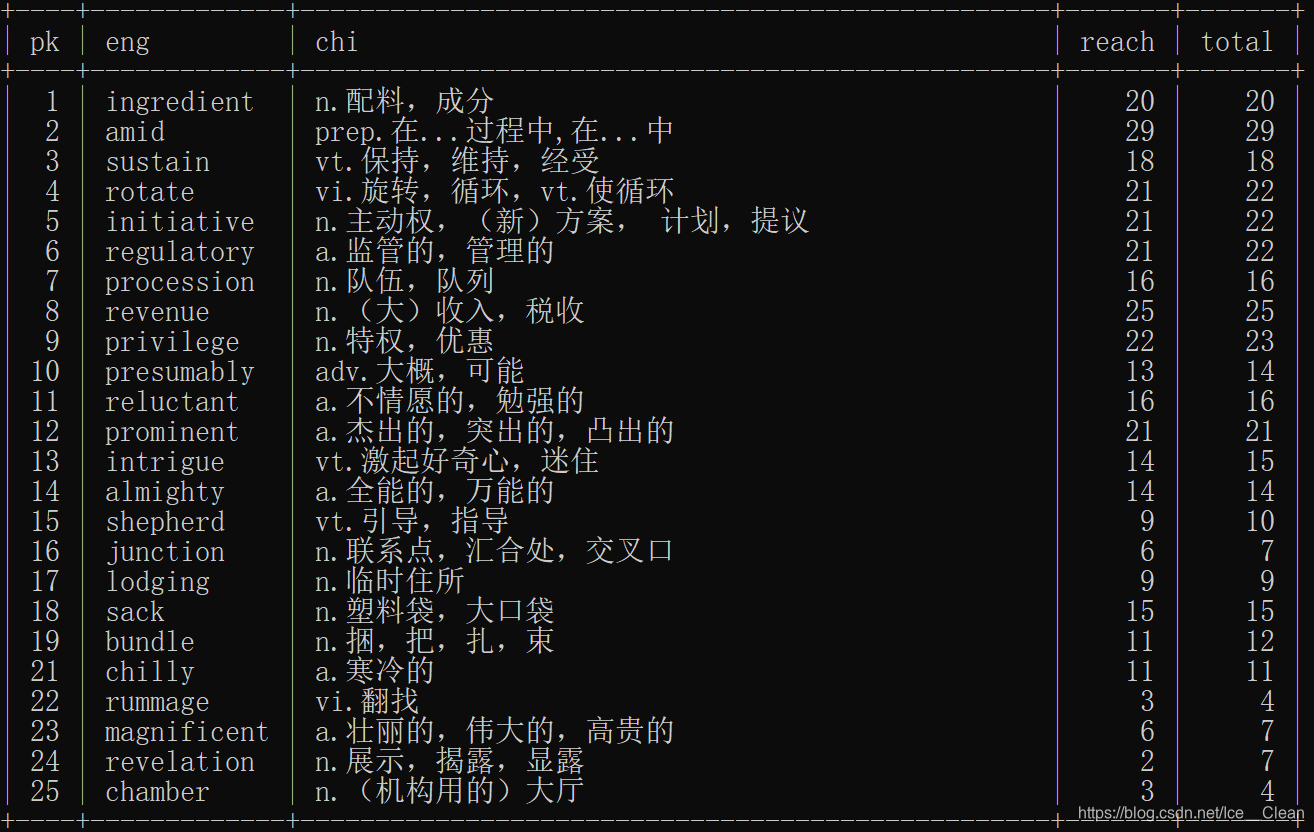
◉ 练习过程使用的表
SELECT * FROM spe01;
● SHOW 语句
SHOW DATABASES; 显示所有数据库
SHOW TABLES; 查看当前使用数据库中所有的表
SHOW CREATE TABLE <name>; 查看创建表的语句
● WHERE 条件查询
—① 常规符号 & AND & OR
> >= < <= 大于、大于等于、小于、小于等于
<> != 两个都可以表示不等于
= 一个等号判断相等,注意不要习惯性用两个等号哦
中间可以用 AND 、OR 连接多个条件
SELECT eng, reach FROM spe01 WHERE reach >= 15 AND reach <= 20 AND reach <> 18 OR reach = 25;
+------------+-------+
| eng | reach |
+------------+-------+
| ingredient | 20 |
| procession | 16 |
| revenue | 25 |
| reluctant | 16 |
| sack | 15 |
+------------+-------+
—② IN & NOT IN
IN 用来判断是否与列出的值相匹配,NOT IN 则相反
注意!!!此处为枚举,不是范围
可以放数字以及字符
SELECT eng, reach FROM spe01 WHERE reach IN (14, 15, 18);
+----------+-------+
| eng | reach |
+----------+-------+
| sustain | 18 |
| intrigue | 14 |
| almighty | 14 |
| sack | 15 |
+----------+-------+
—③ BETWEEN … AND …
SELECT eng, reach FROM spe01 WHERE reach BETWEEN 15 AND 20;
+------------+-------+
| eng | reach |
+------------+-------+
| ingredient | 20 |
| sustain | 18 |
| procession | 16 |
| reluctant | 16 |
| sack | 15 |
+------------+-------+
注意:BETWEEN AND 可以放数字和字符,对于数字来说范围是 闭区间 ,对于字符来说是 左闭右开,如:
SELECT eng, reach FROM spe01 WHERE eng BETWEEN 'a' AND 'c';
+----------+-------+
| eng | reach |
+----------+-------+
| amid | 29 |
| almighty | 14 |
| bundle | 11 |
+----------+-------+
—④ NULL
NULL 表示 ‘ 空 ’ ,不是一个值,判断时不能用 =NULL
可供使用的是 IS NULL 和 IS NOT NULL
SELECT eng FROM spe01 WHERE eng IS NULL;
Empty set (0.01 sec)
没有为空的
—⑤ LIKE
LIKE 用于模糊查询
有两个符号,一个是 %,一个是 _
% 代表任意多个字符,_ 代表任意1个字符
SELECT eng FROM spe01 WHERE eng LIKE '__g%';
解释:表示查询 eng 中第三个字母为 'g' 的
+-------------+
| eng |
+-------------+
| ingredient |
| regulatory |
| magnificent |
+-------------+
注意: 如果有特殊需求,比如需要查询含有 _ 或 % 的,直接写会冲突而达不到效果,这时候需要用到转义字符反斜杠‘ \ ’ ,如:
SELECT eng FROM spe01 WHERE eng LIKE '__\%%';
解释:查询第三个位置为 % 的,这里没有
Empty set (0.00 sec)
● ORDER BY 排序查询
默认是升序
可手动指定,ASC 表示升序,DESC 表示降序
SELECT eng, reach FROM spe01 ORDER BY reach DESC LIMIT 5;
解释:按达成数降序排序查询,为了方便只截取了前五条
+------------+-------+
| eng | reach |
+------------+-------+
| amid | 29 |
| revenue | 25 |
| privilege | 22 |
| rotate | 21 |
| regulatory | 21 |
+------------+-------+
2021-9-15 补充
有些时候默认的败絮规则已经满足不了我们的需求
最近一次遇到的是根据名字高级程度进行排序,如按 特等奖 一等奖 二等奖 三等奖 进行排序
按默认排序的话,特等奖会排到一二三等级后面,这显然不满足要求
这时就需要用到 field 自定义排序规则了,如下(示例):
SELECT * FROM xxx ORDER BY field(level, '特等奖', '一等奖', '二等奖', '三等奖');
这样就实现了排序规则的自定义,同样也支持 asc,desc 升降序
● 分组函数
别称: 多行处理函数,指处理多行最后只显示一行
分组函数一共有 5 个:
count 计数
sum 求和
avg 平均值
max 最大值
min 最小值
注意 1 : 所有的分组函数都是对 “某一组” 数据进行操作的,如果没有使用 GROUP BY 进行分组,默认会全部自成一组
注意 2 : 分组函数会自动忽略值为 NULL 的,所以后面不需要再加 WHERE xx IS NOT NULL ,多余!
SELECT COUNT(eng) 'num', SUM(reach) 'sum', AVG(reach) 'avg', MAX(reach) 'max', MIN(reach) 'min' FROM spe01;
分别查出 单词总数,总达成数,平均达成数,最大达成数,最小达成数
+-----+------+---------+------+------+
| num | sum | avg | max | min |
+-----+------+---------+------+------+
| 24 | 346 | 14.4167 | 29 | 2 |
+-----+------+---------+------+------+
特别注意: 由上面语句的执行顺序可知,WHERE 在 GROUP BY 之前执行,也就是说执行 WHERE 时还没有分组完毕,所以在 WHERE 中不能直接使用分组函数!
SELECT eng, reach FROM spe02 WHERE reach > AVG(reach);
解释:这里想找出达成数大于平均达成数的单词,但却出错了
ERROR 1111 (HY000): Invalid use of group function
错因是没有有效的分组
emmmm 那该怎么办呢?
常规思路应该是先把平均数算出来,再进行比较
那么就可以想到嵌套,也就是子查询,如:
SELECT eng, reach FROM spe02 WHERE reach > (SELECT AVG(reach) FROM spe02);
+------------+-------+
| eng | reach |
+------------+-------+
| ingredient | 20 |
| amid | 29 |
| sustain | 18 |
| rotate | 21 |
| initiative | 21 |
......
子查询部分后面再一起总结
● GROPU BY 分组查询
注意 1 : GROUP BY 后面只能更分组函数和参与分组的字段,否则报错
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY
注意 2 : HAVING 后面出现的字段必须是已经在 SELECT 后出现的字段,否则报错
ERROR 1054 (42S22): Unknown column <name> in 'having clause'
注意 3 : 能用 WHERE 尽量不要用 HAVING,WHERE 效率较高
SELECT total, AVG(reach) FROM spe01 GROUP BY total HAVING AVG(reach)<5;
解析:将 total 相同的数据归为一组再取平均值,然后再筛选出其中小于 5 的
(例子不太好,这个处理没什么意义)
+-------+------------+
| total | AVG(reach) |
+-------+------------+
| 4 | 3.0000 |
| 7 | 4.6667 |
+-------+------------+
● 单行处理函数
—① 字符函数
字符函数常见有以下 6 个
LENGTH 获取参数值的字节个数
CONCAT 拼接字符串
UPPER、LOWER 改变字符的大小写
SUBSTR(注意:索引从1开始)
INSTR 返回字符串第一次出现的索引,如果找不到返回 0
REPLACE 替换
LENGTH、CONCAT、UPPER 演示
SELECT eng, LENGTH(eng) 'len', CONCAT('> ',eng, ' <') 'new', UPPER(eng) 'change' FROM spe01 LIMIT 5;
+------------+------+----------------+------------+
| eng | len | new | change |
+------------+------+----------------+------------+
| ingredient | 10 | > ingredient < | INGREDIENT |
| amid | 4 | > amid < | AMID |
| sustain | 7 | > sustain < | SUSTAIN |
| rotate | 6 | > rotate < | ROTATE |
| initiative | 10 | > initiative < | INITIATIVE |
+------------+------+----------------+------------+
Tip: CONCAT 可以多重拼接
SUBSTR、INSTR、REPLACE 演示
SELECT eng, SUBSTR(eng, 4, 2) '4~6', INSTR(eng, 'n') 'begin n', REPLACE(eng, 'i', 'I') 'i -> I' FROM spe01 LIMIT 5;
+------------+------+---------+------------+
| eng | 4~6 | begin n | i -> I |
+------------+------+---------+------------+
| ingredient | re | 2 | IngredIent |
| amid | d | 0 | amId |
| sustain | ta | 7 | sustaIn |
| rotate | at | 0 | rotate |
| initiative | ti | 2 | InItIatIve |
+------------+------+---------+------------+
Tip: SUBSTR 的索引从 1 开始,再后面跟的是个数
—② 其他函数
ROUND 四舍五入
IFNULL 空处理
SELECT ROUND(AVG(IFNULL(reach, 0))) 'reach avg round' FROM spe01;
解释:套了三个函数,如果 reach 是空的话按 0 处理(虽然没什么意义就是233)
然后取平均数再四舍五入
IFNULL(字段名,为空时当作什么处理)
+-----------------+
| reach avg round |
+-----------------+
| 14 |
+-----------------+
● 多表查询
双表连接方式分类:
- 内连接:等值连接,非等值连接,自连接
- 外连接:左外连接(左连接),右外连接(右连接)
① 等值连接与非等值连接
select a.name, b.name
from aaa a
[inner] join bbb b # inner 可省
on a.id = b.id; # 使用等于号为等值连接
on a.id > b.id; # 使用不等号或者 between and 为非等值连接
② 自连接
一张表看成两张表就行了
select a.name, b.name
from aaa a
[inner] join aaa b
on a.id1 = b.id2;
③ 左连接与右连接
select a.name, b.name
from aaa a
left [outer] join bbb b
on a,id=b,id;
left join 表示左边的表为主表,即左边的表数据将全部显示出来
没有和右表匹配上的,有用到右表数据的采用 NULL 代替
右连接相似
④ 多表连接
select a.name, b.name, c.name, d.name
from aaa a
join bbb b on a.id = b.id
left join ccc c on a.id > c.id
right join ddd d on a.id < d.id
可以内外连接混合使用
未完待续(寒冰小澈)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号