流处理
流处理
1.1简介
流处理是针对流式数据的实时计算。它具有实时持续、来源众多、不关注存储等特点。典型的应用场景有互联网业务的日志数据处理、金融领域的银行股票数据处理等。
1.2 处理流程
传统数据处理流程是用户发起查询请求,请求被翻译成数据库查询语句,最终通过数据户将查询结果返回给用户。此时用户是主动的,DBMS是被动的
流处理数据处理流程是数据实时采集、实时计算、实时接受查询服务。用户接收流处理后的结果。此时用户是被动的,DBMS是主动的。
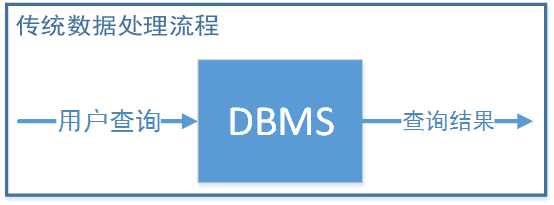
传统数据处理流程

流处理数据处理流程
2.流处理系统
2.1 Storm
2.1.1Storm简介
Storm (event processor)是一个分布式计算框架,主要由Clojure编程语言编写。最初是由Nathan Marz及其团队创建于BackType,该项目在被Twitter取得后开源。它通过使用者定义的“喷嘴(spouts)”和“阀门(bolts)”来定义数据源和相应的操作来实现批量、分布式处理流式数据。最初版本发布于2011年9月17日,目前最新稳定版本为2016年8月10日的1.0.2版本。
Storm应用被设计称为一个拓扑结构,该拓扑结构是一个有向无环图(Directed Acyclic Graph,DAG)。有向无环图的顶点是“喷嘴”和“阀门”,边是数据流。一个简单的拓扑结构如图2-1所示:
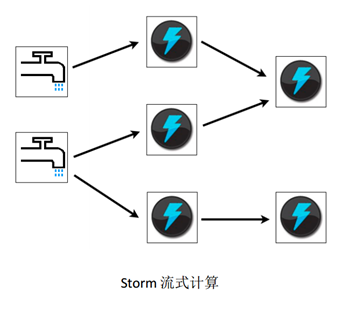
图2-1 Storm流式计算拓扑
下面对Storm中的重要概念进行简要介绍。
2.1.1.1Streams(流)
Storm对于流Stream的抽象:流是一个不间断的无界的连续Tuple(元组,是元素有序列表)。Stream消息流,是一个没有边界的Tuple序列,这些Tuples会被以一种分布式的方式并行地创建和处理。如图2-2所示。

图2-2 Streams抽象
2.1.1.2 Spouts(喷嘴)
Storm认为每个Stream都有一个源头,它将这个源头抽象为Spouts。Spouts流数据源,它会从外部读取流数据并发出Tuple。如图2-3所示。

图2-3 Spouts
2.1.1.3 Bolts(阀门)
Storm将流的中间状态转换抽象为Bolts,Bolts可以处理Tuples,同时它也可以发送新的流给其他Bolts使用。Bolts消息处理者,所有的消息处理逻辑被封装在Bolts里面,处理输入的数据流并产生输出的新数据流,可执行过滤,聚合,查询数据库等操作。如图2-4所示。

图2-4 Bolts
2.1.1.4 Topology(拓扑)
为了提高效率,在Spout源接上多个Bolts处理器。Storm将这样的有向无环图抽象为Topology(拓扑)。Topology是Storm中最高层次的抽象概念,它可以被提交到Storm集群执行,一个拓扑就是一个流转换图。图中的边表示Bolt订阅了哪些流。当Spout或者Bolt发送元组到流时,它就发送元组到每个订阅了该流的Bolt上进行处理。如图2-5所示:

2-5 Topology
2.1.1.5 Stream Groupings(消息分组策略)
定义一个 Topology 的其中一步是定义每个Bolt 接收什么样的流作为输入。Stream Grouping 就是用来定义一个Stream 应该如何分配给Bolts 上面的多个Tasks。Storm 里面有6 种类型的Stream Grouping。
● Shuffle Grouping:随机分组,随机派发Stream 里面的tuple,保证每个Bolt 接收到的tuple 数目相同。
● Fields Grouping:按字段分组,比如按userid 来分组,具有同样userid 的tuple 会被分到相同的Bolts,而不同的userid 则会被分配到不同的Bolts。
● All Grouping:广播发送,对于每一个tuple,所有的Bolts 都会收到。
● Global Grouping: 全局分组,这个tuple 被分配到Storm 中一个Bolt 的其中一个Task。再具体一点就是分配给id 值最低的那个Task。
● Non Grouping:不分组,这个分组的意思是Stream 不关心到底谁会收到它的tuple。目前这种分组和Shuffle Grouping 是一样的效果,有一点不同的是Storm 会把这个Bolt 放到此Bolt 的订阅者同一个线程里面去执行。
● Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个Task 处理这个消息。只有被声明为Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple 必须使用emitDirect 方法来发送。消息处理者可以通过TopologyContext 来获取处理它的消息的taskid(OutputCollector.emit 方法也会返回taskid)。
2.1.1.6 Reliability(可靠性)
Storm 可以保证每个消息tuple 会被Topology 完整地处理,Storm 会追踪每个从Spout 发送出的消息tuple 在后续处理过程中产生的消息树(Bolt 接收到的消息完成处理后又可以产生0 个或多个消息,这样反复进行下去,就会形成一棵消息树),Storm 会确保这棵消息树被成功地执行。Storm 对每个消息都设置了一个超时时间,如果在设定的时间内,Storm 没有检测到某个从Spout 发送的tuple 是否执行成功,Storm 会假设该tuple 执行失败,因此会重新发送该tuple。这样就保证了每条消息都被正确地完整地执行。
Storm 保证消息的可靠性是通过在发送一个tuple 和处理完一个tuple 的时候都需要像Storm 一样返回确认信息来实现的,这一切是由OutputCollector 来完成的。通过它的emit 方法来通知一个新的tuple 产生,通过它的ack 方法通知一个tuple 处理完成。
2.1.1.7 Task(任务)
在 Storm 集群上,每个Spout 和Bolt 都是由很多个Task 组成的,每个Task对应一个线程,流分组策略就是定义如何从一堆Task 发送tuple 到另一堆Task。在实现自己的Topology 时可以调用TopologyBuilder.setSpout() 和TopBuilder.setBolt()方法来设置并行度,也就是有多少个Task。
2.1.1.8 Worker(工作进程)
一个 Topology 可能会在一个或者多个工作进程里面执行,每个工作进程执行整个Topology 的一部分。比如,对于并行度是300 的Topology 来说,如果我们使用50 个工作进程来执行,那么每个工作进程会处理其中的6 个Tasks(其实就是每个工作进程里面分配6 个线程)。Storm 会尽量均匀地把工作分配给所有的工作进程。
2.1.1.9 Config(配置)
在 Storm 里面可以通过配置大量的参数来调整Nimbus、Supervisor 以及正在运行的Topology 的行为,一些配置是系统级别的,一些配置是Topology 级别的。所有有默认值的配置的默认配置是配置在default.xml 里面的,用户可以通过定义一个storm.xml 在classpath 里来覆盖这些默认配置。并且也可以使用Storm Submitter 在代码里面设置一些Topology 相关的配置信息。当然,这些配置的优先级是default.xml<storm.xml<TOPOLOGY-SPECIFIC 配置。
Storm集群表面类似Hadoop集群:
- 在Hadoop上运行的是“MapReduce jobs”,在Storm上运行的是
- “Topologies”。两者大不相同,一个关键不同是一个MapReduce的Job
最终会结束,而一个Topology永远处理消息(或直到kill它)。
- Storm集群有两种节点:控制(Master)节点和工作者(Worker)节点。
- 控制节点运行一个称之为“Nimbus”的后台程序,负责在集群范围内分
发代码、为worker分配任务和故障监测。
- 每个工作者节点运行一个称之“Supervisor”的后台程序,监听分配给它
所在机器的工作,基于Nimbus分配给它的事情来决定启动或停止工作者进程。
Storm工作流程如图2-6所示:
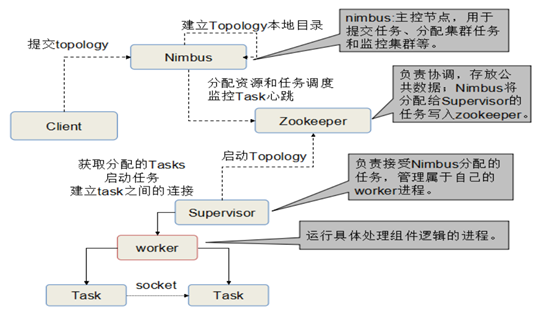
图2-6 Storm工作流程
2.1.2 Storm特征
Storm 在官方网站中列举了它的几大关键特征。
● 适用场景广:Storm 可以用来处理消息和更新数据库(消息的流处理),对一个数据量进行持续的查询并将结果返回给客户端(连续计算),对于耗费资源的查询进行并行化处理(分布式方法调用),Storm 提供的计算原语可以满足诸如以上所述的大量场景。
● 可伸缩性强:Storm 的可伸缩性可以让Storm 每秒处理的消息量达到很高,如100 万。实现计算任务的扩展,只需要在集群中添加机器,然后提高计算任务的并行度设置。Storm 网站上给出了一个具有伸缩性的例子,一个Storm应用在一个包含10 个节点的集群上每秒处理1 000 000 个消息,其中包括每秒100 多次的数据库调用。Storm 使用Apache ZooKeeper 来协调集群中各种配置的同步,这样Storm 集群可以很容易地进行扩展。
● 保证数据不丢失:实时计算系统的关键就是保证数据被正确处理,丢失数据的系统使用场景会很窄,而Storm 可以保证每一条消息都会被处理,这是Storm 区别于S4(Yahoo 开发的实时计算系统)系统的关键特征。
● 健壮性强:不像Hadoop 集群很难进行管理,它需要管理人员掌握很多Hadoop 的配置、维护、调优的知识。而Storm 集群很容易进行管理,容易管理是Storm 的设计目标之一。
● 高容错:Storm 可以对消息的处理过程进行容错处理,如果一条消息在处理过程中失败,那么Storm 会重新安排出错的处理逻辑。Storm 可以保证一个处理逻辑永远运行。
● 语言无关性:Storm 应用不应该只能使用一种编程平台,Storm 虽然是使用Clojure 语言开发实现,但是,Storm 的处理逻辑和消息处理组件都可以使用任何语言来进行定义,这就是说任何语言的开发者都可以使用Storm。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需要实现一个简单的额Storm通信协议即可。
2.1.3 Storm容错处理
Storm 的容错分为如下几种类型。
(1)工作进程worker 失效:如果一个节点的工作进程worker“死掉”,supervisor 进程会尝试重启该worker。如果连续重启worker 失败或者worker 不能定期向Nimbus 报告“心跳”,Nimbus 会分配该任务到集群其他的节点上执行。
(2)集群节点失效:如果集群中某个节点失效,分配给该节点的所有任务会因超时而失败,Nimbus 会将分配给该节点的所有任务重新分配给集群中的其他节点。
(3)Nimbus 或者supervisor 守护进程失败:Nimbus 和supervisor 都被设计成快速失败(遇到未知错误时迅速自我失败)和无状态的(所有的状态信息都保存在Zookeeper 上或者是磁盘上)。Nimbus 和supervisor 守护进程必须在一些监控工具(例如,daemontools 或者monitor)的辅助下运行,一旦Nimbus 或者supervisor 失败,可以立刻重启它们,整个集群就好像什么事情也没发生。最重要的是,没有工作进程worker 会因为Nimbus 或supervisor 的失败而受到影响,Storm 的这个特性和Hadoop 形成了鲜明的对比,如果JobTracker 失效,所有的任务都会失败。
(4)Nimbus 所在的节点失效:如果Nimbus 守护进程驻留的节点失败,工作节点上的工作进程worker 会继续执行计算任务,而且,如果worker 进程失败,supervisor 进程会在该节点上重启失败的worker 任务。但是,没有Nimbus的影响时,所有worker 任务不会分配到其他的工作节点机器上,即使该worker所在的机器失效。
2.1.4 Storm 典型应用场景
Storm 有许多应用领域,包括实时分析、在线机器学习、信息流处理(例如,可以使用Storm 处理新的数据和快速更新数据库)、连续性的计算(例如,使用Storm 连续查询,然后将结果返回给客户端,如将微博上的热门话题转发给用户)、分布式RPC(远过程调用协议,通过网络从远程计算机程序上请求服务)、ETL(Extraction Transformation Loading,数据抽取、转换和加载)等。
2.1.5 Storm处理性能
Storm 的处理速度惊人,经测试,每个节点每秒可以处理100 万个数据元组。Storm 可扩展且具有容错功能,很容易设置和操作。Storm 集成了队列和数据库技术,Storm 拓扑网络通过综合的方法,将数据流在每个数据平台间进行重新分配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号