车牌识别(end-to-end-for-chinese-plate-recognition)项目搭建基于Mxnet(Python 3.5)
最近看到geihub上有个车牌识别的项目,感觉很有意思,从上面fork了一下弄到本地自己跑了下。在安装过程中遇到了一些问题,记录如下。
项目github连接:https://github.com/szad670401/end-to-end-for-chinese-plate-recognition ,本机环境Win8 64bit
该项目是基于Python做的,所以首先安装python,本着用最新版本的原则,选择了Python3.5.2(开始用的32位版本,中间不能加载libmxnet.dll,后改为用64bit)
1.Python下载连接:https://www.python.org/downloads/release/python-352/ 依据操作系统进行选择,我选择的是如下版本
2.安装Python,并配置好环境变量
3.安装vs2015,由于mxnet中使用了vs2015的库,所以需要提前安装vs2015,不然后报"error: Setup script exited with error: Unable to find vcvarsall.bat” 下载地址:http://103.254.64.34:9999/download.microsoft.com/download/5/f/7/5f7acaeb-8363-451f-9425-68a90f98b238/visualcppbuildtools_full.exe。
4.下载Mxnet ,地址:https://github.com/dmlc/mxnet/releases 我下载的是20160531_win10_x64_cpu.7z
5.安装Mxnet ,解压上面的压缩包后进入mxnet目录,执行setupenv.cmd 然后进入该目录下的python目录,执行python setup.py install 命令进行安装
6.下载opencv,下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv 我选择的是:opencv_python-3.1.0+contrib_opencl-cp35-cp35m-win_amd64.whl
7.安装opencv ,在python安装目录执行 pip install opencv_python-3.1.0+contrib_opencl-cp35-cp35m-win_amd64.whl
8.下载Pillow,由于官方目前PIL没有3.5版本,故采用非官方的Pillow替代,下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#pillow 版本:Pillow-3.3.1-cp34-cp34m-win_amd64.whl
9.安装Pillow,在python安装目录执行 pip install Pillow-3.3.1-cp34-cp34m-win_amd64.whl
到此安装过程完毕,用IDEA打开执行,但是报了如下错误,并附上解决办法;
错误1.
error: (-215) ssize.area() > 0 in function cv::resize 传入文件为空 错误原因:genplate.py的generate函数中
L163 len(text) == 9改为len(text) == 7
错误2
L164 text.decode(encoding="utf-8")改为text.encode('utf-8').decode(encoding="utf-8") (python3.5特性)
错误3.
找不到xrange
原因:使用3.5内置的range替代2.7的xrange 修改方法:xrange--range
range内除法操作如range(self.count / self.batch_size)需改为 range((int)(self.count / self.batch_size))
不然有 “'float' object cannot be interpreted as an integer”错误
修改后的代码github连接:https://github.com/ibyte2011/end-to-end-for-chinese-plate-recognition
安装好后开始训练;一个2.5Ghz的 CPU
实验一:训练了4个小时,训练数据3w准确率约为 60%
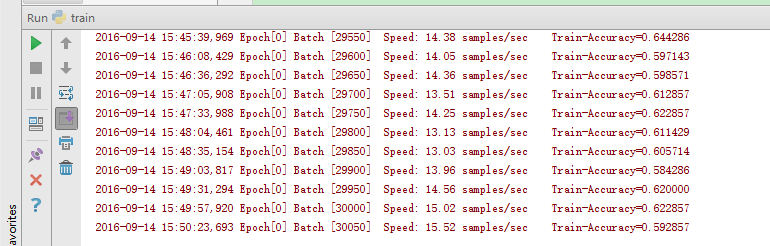
开始测试:
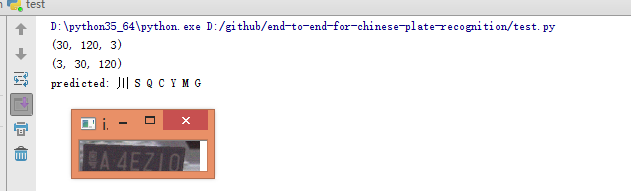
由于训练时间过短,检测全部错误。等花一天训练后再试。
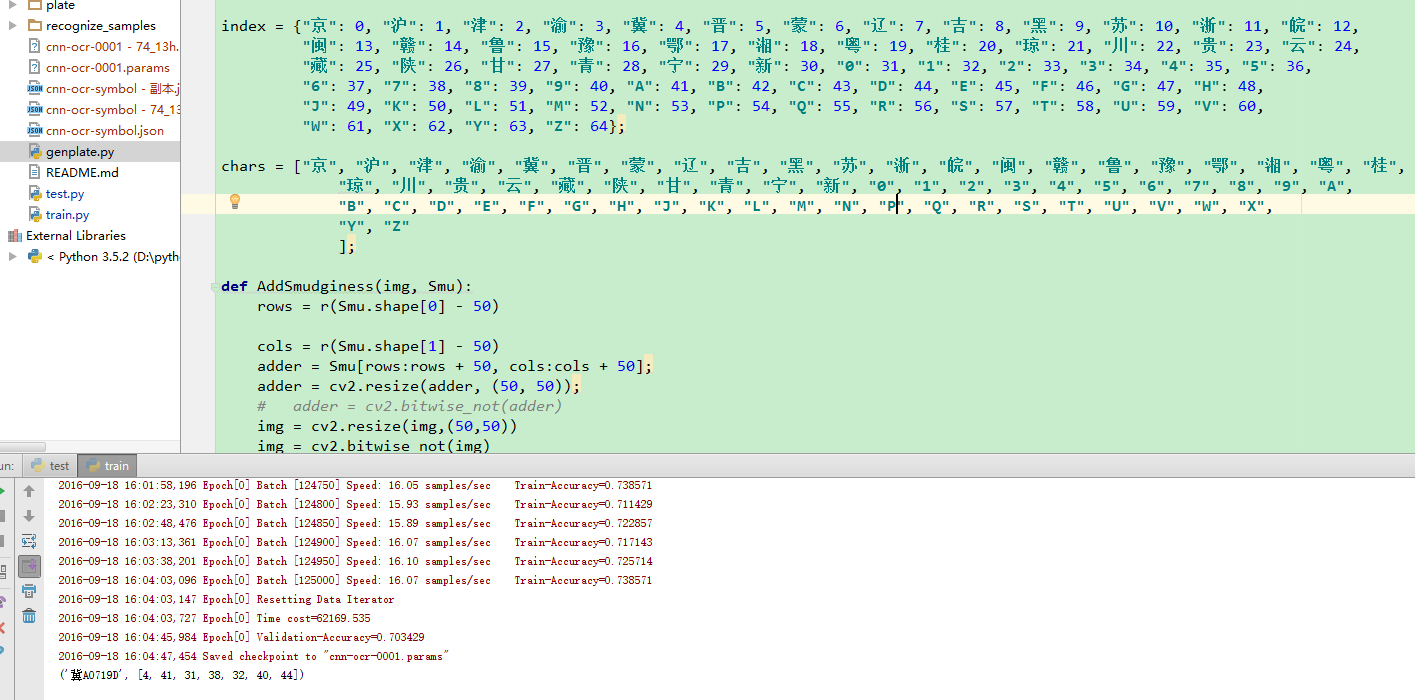
实验二:
训练数据12.5W,时间17hours,准确率70%
测试:
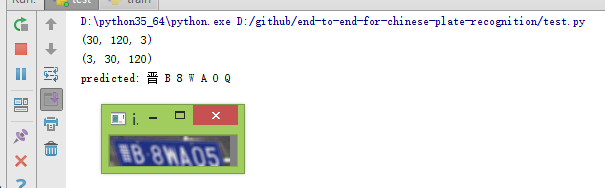
从测试结果看这次好于实验一,有一个字母识别错误,不过在多次测试过程中,清楚字体如下图情况下识别完全正确:
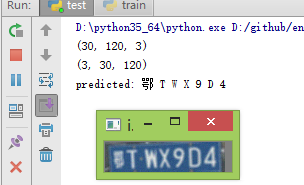
在字体模糊或者变形严重情况下识别会出现错误比较大,7个只对了1个。
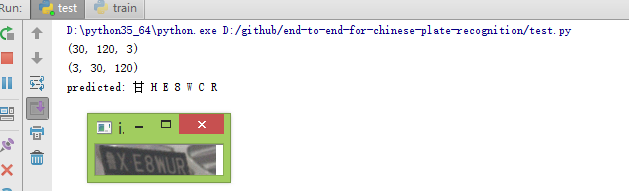
故加大实验数据进行实验三。
实验三:调整了准确率计算函数参数,将train.py L135行
pred.shape[0] / 4 改为 pred.shape[0] / 7 训练12.5 hours 准确率为94%
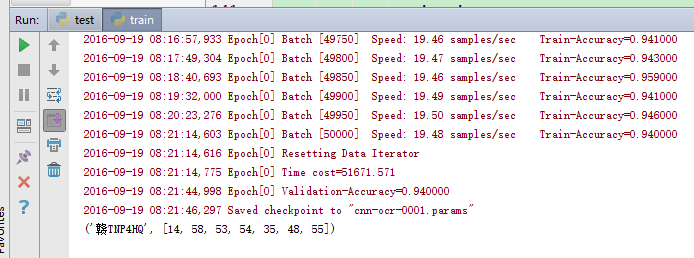
测试:
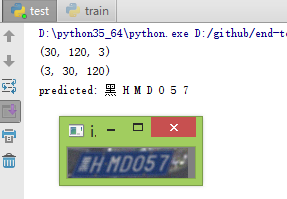
模糊测试:
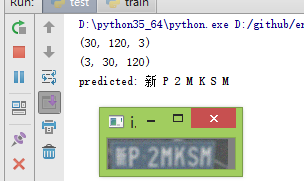
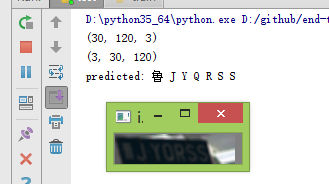
从测试结果看明显好于实验二。
简单记录,希望对此项目感兴趣的同学有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号