大数据第二课-HDFS Java API开发
1、配置windows当中的环境变量
解压资料当中的 hadoop-2.6.0-cdh5.14.2_windows环境配置安装包.rar 这个压缩文件文件到一个没有中文没有空格的目录下
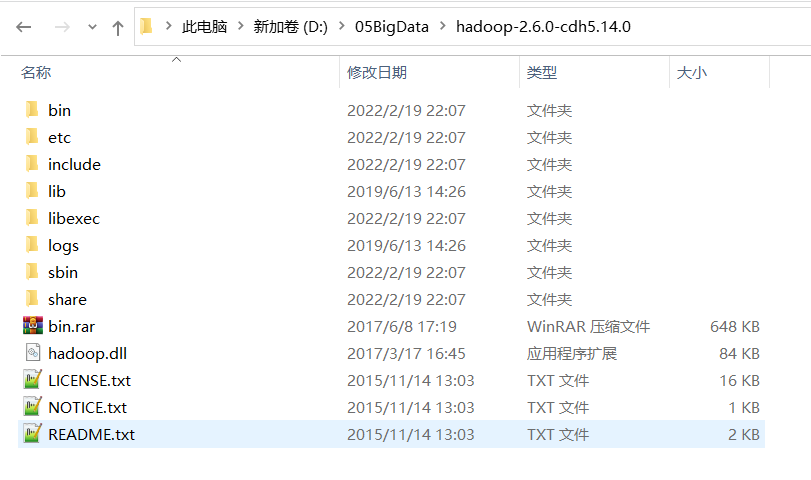
然后在windows当中配置hadoop的环境变量

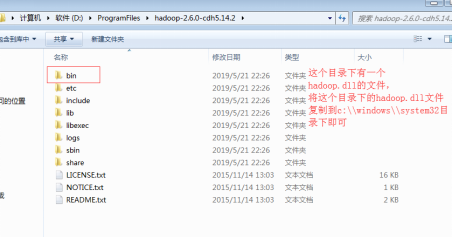
然后将hadoop.dll文件拷贝到C:\Windows\System32
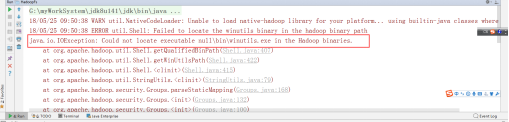
注意 如果没有 配置好windows的hadoop的环境变量,那么就会报以下错误
二、创建Maven工程并导入jar包
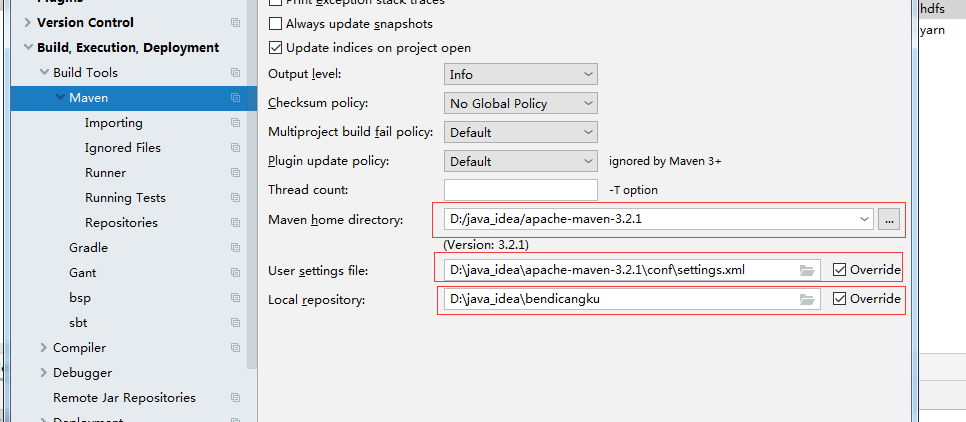
1、首先,需要配置Maven的本地仓库,远程仓库,安装路径等(具体参考别人的博客)
2、创建Maven工程,导入jar包
创建工程参考别人博客,我这只给下面的 pom.xml 文件内容(最好在没网的时候创建,不要Enable import Automatic,我这之前老是自动加载包出错)
<repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0-mr1-cdh5.14.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0-cdh5.14.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.0-cdh5.14.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.0-cdh5.14.2</version> </dependency> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>7.0.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> <!-- <verbal>true</verbal>--> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <minimizeJar>true</minimizeJar> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
然后在下面这个文件下创建 .java 文件
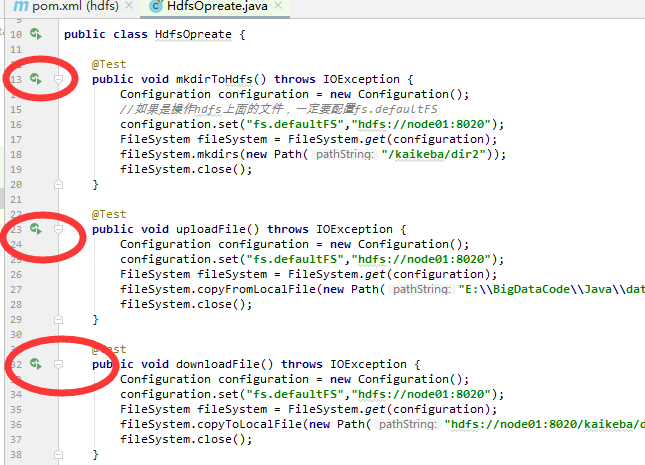
HdfsOpreate.java的内容如下:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.Test; import java.io.IOException; public class HdfsOpreate { @Test public void mkdirToHdfs() throws IOException { Configuration configuration = new Configuration(); //如果是操作hdfs上面的文件,一定要配置fs.defaultFS configuration.set("fs.defaultFS","hdfs://node01:8020"); FileSystem fileSystem = FileSystem.get(configuration); fileSystem.mkdirs(new Path("/kaikeba/dir2")); fileSystem.close(); } @Test public void uploadFile() throws IOException { Configuration configuration = new Configuration(); configuration.set("fs.defaultFS","hdfs://node01:8020"); FileSystem fileSystem = FileSystem.get(configuration); fileSystem.copyFromLocalFile(new Path("E:\\BigDataCode\\Java\\data\\wc\\input\\text1.txt"),new Path("hdfs://node01:8020/kaikeba/dir2")); fileSystem.close(); } @Test public void downloadFile() throws IOException { Configuration configuration = new Configuration(); configuration.set("fs.defaultFS","hdfs://node01:8020"); FileSystem fileSystem = FileSystem.get(configuration); fileSystem.copyToLocalFile(new Path("hdfs://node01:8020/kaikeba/dir1/word.txt"),new Path("E:\\BigDataCode\\Java\\data\\word2.txt")); fileSystem.close(); } }
然后执行代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号