


如何优化SQL
一、SQL简介
1.1.什么是SQL?
SQL(结构化查询语言)是一种用于访问和处理数据库的标准计算机语言。
1.2.SQL能做什么?
- SQL 面向数据库执行查询
- SQL 可从数据库取回数据
- SQL 可在数据库中插入新的记录
- SQL 可更新数据库中的数据
- SQL 可从数据库删除记录
- SQL 可创建新数据库
- SQL 可在数据库中创建新表
- SQL 可在数据库中创建存储过程
- SQL 可在数据库中创建视图
- SQL 可以设置表、存储过程和视图的权限
二、如何优化SQL?
在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用 系统提交实际应用后,随着数据库中数据的增加,系统的响应速度就成为目前系统需要解决的最主要的问题之一。系统优化中一个很重要的方面就是SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见对于一个系统不是简单地能实现其功能就可,而是要写出高质量的SQL语句,提高系统的可用性。
由此可见,SQL的优化非常重要,那么优化SQL的方法有哪些呢?
2.1.使用索引
2.1.1索引简介
索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
2.1.2索引分类以及原理
按照索引数据的存储方式可以将索引分为B树索引、位图索引、反向键索引和基于函数的索引等,其中B树索引是Oralce数据库中最常用的索引类型(也是默认的),原理如下图,其中Root为根节点,branch 为分支节点,leaf 到最下面一层称为叶子节点。每个节点表示一层,当查找某一数据时先读根节点,再读支节点,最后找到叶子节点。叶子节点会存放index entry (索引入口),每个索引入口对应一条记录。
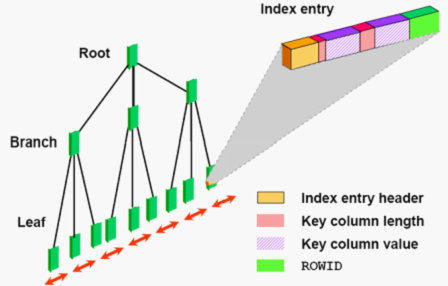
Index entry 的组成部分:
Indexentry entry header 存放一些控制信息。
Key column length 某一key的长度
Key column value 某一个key 的值
ROWID 指针,具体指向于某一个数据
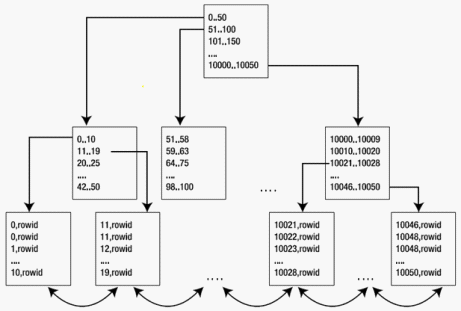
下面这张图能更加清晰的描述索引的结构。
跟节点记录0至50条数据的位置,分支节点进行拆分记录0至10.......42至50,叶子节点记录每条数据的长度和值,并由指针指向具体的数据。
最后一层的叶子节是双向链接,它们是被有序的链接起来,这样才能快速锁定一个数据范围。
2.1.3索引的应用
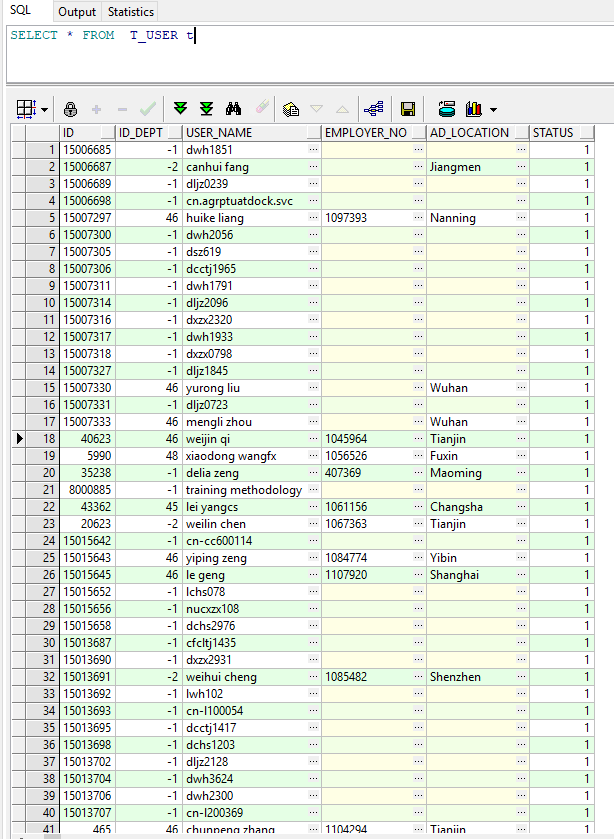
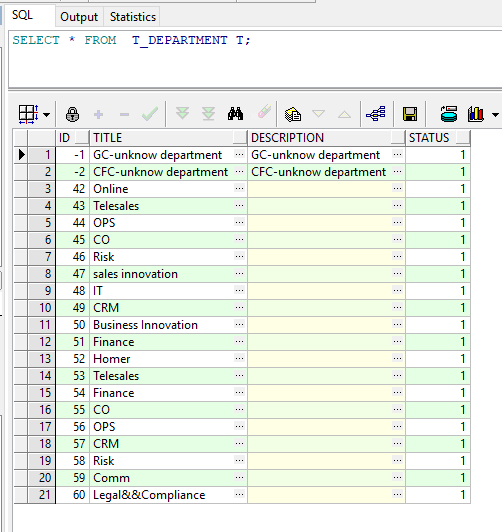
了解完索引的原理之后,来看看索引的基本应用。创建一张User表和一张Department表,两者多对一关系,并往User表插入10万左右的数据,往Department表插入21条数据,DDL语句如下:
create table T_USER ( id NUMBER not null, id_dept NUMBER, user_name VARCHAR2(100) not null, employer_no VARCHAR2(100), ad_location VARCHAR2(100), status NUMBER not null )
alter table T_USER add constraint PK_USER_ID primary key (ID) using index
tablespace jay;
create table T_DEPARTMENT ( id NUMBER not null, title VARCHAR2(100 CHAR) not null, description VARCHAR2(200 CHAR), status NUMBER not null ); alter table T_DEPARTMENT add constraint PK_DEPARTMENT_ID primary key (ID) using index tablespace jay;
需求1:查询AD_LOCATION为Beijing的用户的USER_NAME,SQL语句如下:
select t.user_name from t_user t where t.ad_location ='Beijing';
执行计划如下:

由此可见,该查询语句目前是走的全表扫描,当表的数据量很大时,查询效率会比较低下,可以通过建立索引进行优化:
create index idx_location on t_user (ad_location);
再执行SQL,执行计划如下:

可以看到,创建索引idx_location之后,查询走了索引,Cost和Time都变小了,查询效率得到了提升。
需求2:查询AD_LOCATION为Beijing,且ID_DEPT为48的用户的USER_NAME,SQL语句如下:
select t.user_name from t_user t where t.ad_location ='Beijing' and t.id_dept= 48;
执行计划如下:

可以看到查询走了刚刚创建的索引IDX_LOCATION,但是又没有更快的方法呢?
由于where语句后面有两列查询条件,可以基于这两列建立复合索引:
create index idx_location_dept on t_user (ad_location,id_dept);
再看执行计划:

可以看到创建了复合索引后,查询走了复合索引idx_location_dept,Cost更小了。
那还能不能更好呢?
把select后面的user_name字段加到复合索引上面来:
create index idx_location_dept_username on t_user (ad_location,id_dept,user_name);
执行计划如下:

可以看到查询走了复合索引idx_location_dept_username,Cost更小了,而TABLE ACCESS BY INDEX ROWID这一行也消失了,这是因为通过索引找到记录时,select后面的user_name也在索引里面,不需要再通过关联rowid回表查询user_name,所以效率更快。
2.1.4如何避免索引失效
上面说完了索引的基本使用,然而在实际的开发工作中,有很多的不当操作都会使得索引失效,下面列举一些常用的使得索引失效的操作,并学习如何避免索引失效。
1.不要在索引列上做计算或者函数操作。
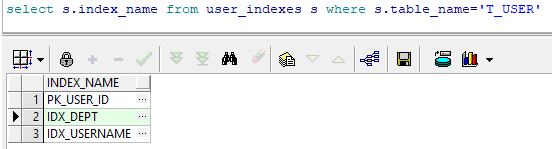
由上图可知目前T_USER表里有两个索引,以IDX_DEPT为例,执行以下SQL:
select * from t_user t where t.id_dept = 48;

可以看到正常走索引了。
如果对索引列进行计算:
select * from t_user t where t.id_dept*2 = 96

可以看到对索引列进行计算,索引失效了。
2.尽量避免like查询以%开头,以%开头会使索引失效
例如查询T_USER表中user_name以jay开头的人的AD_LOCATION:
select t.ad_location from t_user t where t.user_name like 'jay%'

正常走了索引,如果是查询以jay结尾的人的AD_LOCATION呢
select t.ad_location from t_user t where t.user_name like '%jay'

证实了索引列查询如果以%开头会使该索引失效。
3.字符型字段为数字时在where条件里需要添加引号
例如查询T_USER表中user_name为001的人的AD_LOCATION:
select t.ad_location from t_user t where t.user_name = '001'

正常做索引,如果不加引号:
select t.ad_location from t_user t where t.user_name = 001

就变成了全表扫描,放弃了走索引。
4.where条件后面加is null会使索引失效
select t.ad_location from t_user t where t.user_name is null


 浙公网安备 33010602011771号
浙公网安备 33010602011771号