1 # -*- coding: utf-8 -*-
2 """
3 Created on Mon Mar 20 15:35:58 2023
4
5 @author: sanmu
6 """
7
8 import pandas as pd
9 import matplotlib.pyplot as plt
10 import numpy as np
11 from sklearn.preprocessing import StandardScaler
12 from sklearn.neural_network import MLPClassifier
13 import joblib
14 from sklearn.metrics import classification_report
15 from sklearn.metrics import roc_curve
16
17 inputfile = 'D:/anaconda/data/original_data.xls'
18 data = pd.read_excel(inputfile)
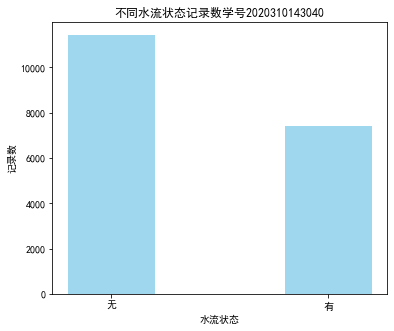
19 # 查看有无水流的分布
20 # 数据提取
21 lv_non = pd.value_counts(data['有无水流'])['无']
22 lv_move = pd.value_counts(data['有无水流'])['有']
23 # 绘制条形图
24
25 fig = plt.figure(figsize = (6 ,5)) # 设置画布大小
26 plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
27 plt.rcParams['axes.unicode_minus'] = False
28 plt.bar(x=range(2), height=[lv_non,lv_move], width=0.4, alpha=0.8,
29 color='skyblue')
30 plt.xticks([index for index in range(2)], ['无','有'])
31 plt.xlabel('水流状态')
32 plt.ylabel('记录数')
33 plt.title('不同水流状态记录数学号2020310143040')
34 plt.show()
35 plt.close()
36
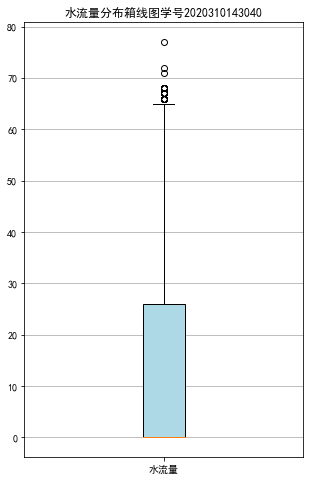
37 # 查看水流量分布
38 water = data['水流量']
39 # 绘制水流量分布箱型图
40 fig = plt.figure(figsize = (5 ,8))
41 plt.boxplot(water,
42 patch_artist=True,
43 labels = ['水流量'], # 设置x轴标题
44 boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
45 plt.title('水流量分布箱线图学号2020310143040')
46 # 显示y坐标轴的底线
47 plt.grid(axis='y')
48 plt.show()
49
50 # 属性规约
51 print('初始状态的数据形状为:', data.shape)
52 # 删除热水器编号、有无水流、节能模式属性
53 data.drop(labels=["热水器编号","有无水流","节能模式"],axis=1,inplace=True)
54 print('删除冗余属性后的数据形状为:', data.shape)
55 data.to_csv('water_heart.csv',index=False)
56
57 # 划分用水事件
58 # 读取数据
59 data = pd.read_csv('water_heart.csv')
60 # 划分用水事件
61 threshold = pd.Timedelta('4 min') # 阈值为4分钟
62 data['发生时间'] = pd.to_datetime(data['发生时间'], format = '%Y%m%d%H%M%S') # 转换时间格式
63 data = data[data['水流量'] > 0] # 只要流量大于0的记录
64 sjKs = data['发生时间'].diff() > threshold # 相邻时间向前差分,比较是否大于阈值
65 sjKs.iloc[0] = True # 令第一个时间为第一个用水事件的开始事件
66 sjJs = sjKs.iloc[1:] # 向后差分的结果
67 sjJs = pd.concat([sjJs,pd.Series(True)]) # 令最后一个时间作为最后一个用水事件的结束时间
68 # 创建数据框,并定义用水事件序列
69 sj = pd.DataFrame(np.arange(1,sum(sjKs)+1),columns = ["事件序号"])
70 sj["事件起始编号"] = data.index[sjKs == True]+1 # 定义用水事件的起始编号
71 sj["事件终止编号"] = data.index[sjJs == True]+1 # 定义用水事件的终止编号
72 print('当阈值为4分钟的时候事件数目为:',sj.shape[0])
73 sj.to_csv('sj.csv',index = False)
74
75 # 确定单次用水事件时长阈值
76 # 确定单次用水事件时长阈值
77 n = 4 # 使用以后四个点的平均斜率
78 threshold = pd.Timedelta(minutes=5) # 专家阈值
79 data['发生时间'] = pd.to_datetime(data['发生时间'], format='%Y%m%d%H%M%S')
80 data = data[data['水流量'] > 0] # 只要流量大于0的记录
81 # 自定义函数:输入划分时间的时间阈值,得到划分的事件数
82 def event_num(ts):
83 d = data['发生时间'].diff() > ts # 相邻时间作差分,比较是否大于阈值
84 return d.sum() + 1 # 这样直接返回事件数
85 dt = [pd.Timedelta(minutes=i) for i in np.arange(1, 9, 0.25)]
86 h = pd.DataFrame(dt, columns=['阈值']) # 转换数据框,定义阈值列
87 h['事件数'] = h['阈值'].apply(event_num) # 计算每个阈值对应的事件数
88 h['斜率'] = h['事件数'].diff()/0.25 # 计算每两个相邻点对应的斜率
89 h['斜率指标']= h['斜率'].abs().rolling(4).mean() # 往前取n个斜率绝对值平均作为斜率指标
90 ts = h['阈值'][h['斜率指标'].idxmin() - n]
91 # 用idxmin返回最小值的Index,由于rolling_mean()计算的是前n个斜率的绝对值平均
92 # 所以结果要进行平移(-n)
93 if ts > threshold:
94 ts = pd.Timedelta(minutes=4)
95 print('计算出的单次用水时长的阈值为:',ts)
96
97 data = pd.read_csv('water_heart.csv') # 读取热水器使用数据记录
98 sj = pd.read_csv('sj.csv') # 读取用水事件记录
99 # 转换时间格式
100 data["发生时间"] = pd.to_datetime(data["发生时间"],format="%Y%m%d%H%M%S")
101
102 # 构造特征:总用水时长
103 timeDel = pd.Timedelta("0.5 sec")
104 sj["事件开始时间"] = data.iloc[sj["事件起始编号"]-1,0].values- timeDel
105 sj["事件结束时间"] = data.iloc[sj["事件终止编号"]-1,0].values + timeDel
106 sj['洗浴时间点'] = [i.hour for i in sj["事件开始时间"]]
107 sj["总用水时长"] = np.int64(sj["事件结束时间"] - sj["事件开始时间"])/1000000000 + 1
108
109 # 构造用水停顿事件
110 # 构造特征“停顿开始时间”、“停顿结束时间”
111 # 停顿开始时间指从有水流到无水流,停顿结束时间指从无水流到有水流
112 for i in range(len(data)-1):
113 if (data.loc[i,"水流量"] != 0) & (data.loc[i + 1,"水流量"] == 0) :
114 data.loc[i + 1,"停顿开始时间"] = data.loc[i +1, "发生时间"] - timeDel
115 if (data.loc[i,"水流量"] == 0) & (data.loc[i + 1,"水流量"] != 0) :
116 data.loc[i,"停顿结束时间"] = data.loc[i , "发生时间"] + timeDel
117
118 # 提取停顿开始时间与结束时间所对应行号,放在数据框Stop中
119 indStopStart = data.index[data["停顿开始时间"].notnull()]+1
120 indStopEnd = data.index[data["停顿结束时间"].notnull()]+1
121 Stop = pd.DataFrame(data={"停顿开始编号":indStopStart[:-1],
122 "停顿结束编号":indStopEnd[1:]})
123 # 计算停顿时长,并放在数据框stop中,停顿时长=停顿结束时间-停顿结束时间
124 Stop["停顿时长"] = np.int64(data.loc[indStopEnd[1:]-1,"停顿结束时间"].values-
125 data.loc[indStopStart[:-1]-1,"停顿开始时间"].values)/1000000000
126 # 将每次停顿与事件匹配,停顿的开始时间要大于事件的开始时间,
127 # 且停顿的结束时间要小于事件的结束时间
128 for i in range(len(sj)):
129 Stop.loc[(Stop["停顿开始编号"] > sj.loc[i,"事件起始编号"]) &
130 (Stop["停顿结束编号"] < sj.loc[i,"事件终止编号"]),"停顿归属事件"]=i+1
131
132 # 删除停顿次数为0的事件
133 Stop = Stop[Stop["停顿归属事件"].notnull()]
134
135 # 构造特征 用水事件停顿总时长、停顿次数、停顿平均时长、
136 # 用水时长,用水/总时长
137 stopAgg = Stop.groupby("停顿归属事件").agg({"停顿时长":sum,"停顿开始编号":len})
138 sj.loc[stopAgg.index - 1,"总停顿时长"] = stopAgg.loc[:,"停顿时长"].values
139 sj.loc[stopAgg.index-1,"停顿次数"] = stopAgg.loc[:,"停顿开始编号"].values
140 sj.fillna(0,inplace=True) # 对缺失值用0插补
141 stopNo0 = sj["停顿次数"] != 0 # 判断用水事件是否存在停顿
142 sj.loc[stopNo0,"平均停顿时长"] = sj.loc[stopNo0,"总停顿时长"]/sj.loc[stopNo0,"停顿次数"]
143 sj.fillna(0,inplace=True) # 对缺失值用0插补
144 sj["用水时长"] = sj["总用水时长"] - sj["总停顿时长"] # 定义特征用水时长
145 sj["用水/总时长"] = sj["用水时长"] / sj["总用水时长"] # 定义特征 用水/总时长
146 print('用水事件用水时长与频率特征构造完成后数据的特征为:\n',sj.columns)
147 print('用水事件用水时长与频率特征构造完成后数据的前5行5列特征为:\n',
148 sj.iloc[:5,:5])
149
150 data["水流量"] = data["水流量"] / 60 # 原单位L/min,现转换为L/sec
151 sj["总用水量"] = 0 # 给总用水量赋一个初始值0
152 for i in range(len(sj)):
153 Start = sj.loc[i,"事件起始编号"]-1
154 End = sj.loc[i,"事件终止编号"]-1
155 if Start != End:
156 for j in range(Start,End):
157 if data.loc[j,"水流量"] != 0:
158 sj.loc[i,"总用水量"] = (data.loc[j + 1,"发生时间"] -
159 data.loc[j,"发生时间"]).seconds* \
160 data.loc[j,"水流量"] + sj.loc[i,"总用水量"]
161 sj.loc[i,"总用水量"] = sj.loc[i,"总用水量"] + data.loc[End,"水流量"] * 2
162 else:
163 sj.loc[i,"总用水量"] = data.loc[Start,"水流量"] * 2
164
165 sj["平均水流量"] = sj["总用水量"] / sj["用水时长"] # 定义特征 平均水流量
166 # 构造特征:水流量波动
167 # 水流量波动=∑(((单次水流的值-平均水流量)^2)*持续时间)/用水时长
168 sj["水流量波动"] = 0 # 给水流量波动赋一个初始值0
169 for i in range(len(sj)):
170 Start = sj.loc[i,"事件起始编号"] - 1
171 End = sj.loc[i,"事件终止编号"] - 1
172 for j in range(Start,End + 1):
173 if data.loc[j,"水流量"] != 0:
174 slbd = (data.loc[j,"水流量"] - sj.loc[i,"平均水流量"])**2
175 slsj = (data.loc[j + 1,"发生时间"] - data.loc[j,"发生时间"]).seconds
176 sj.loc[i,"水流量波动"] = slbd * slsj + sj.loc[i,"水流量波动"]
177 sj.loc[i,"水流量波动"] = sj.loc[i,"水流量波动"] / sj.loc[i,"用水时长"]
178
179 # 构造特征:停顿时长波动
180 # 停顿时长波动=∑(((单次停顿时长-平均停顿时长)^2)*持续时间)/总停顿时长
181 sj["停顿时长波动"] = 0 # 给停顿时长波动赋一个初始值0
182 for i in range(len(sj)):
183 if sj.loc[i,"停顿次数"] > 1: # 当停顿次数为0或1时,停顿时长波动值为0,故排除
184 for j in Stop.loc[Stop["停顿归属事件"] == (i+1),"停顿时长"].values:
185 sj.loc[i,"停顿时长波动"] = ((j - sj.loc[i,"平均停顿时长"])**2) * j + \
186 sj.loc[i,"停顿时长波动"]
187 sj.loc[i,"停顿时长波动"] = sj.loc[i,"停顿时长波动"] / sj.loc[i,"总停顿时长"]
188
189 print('用水量和波动特征构造完成后数据的特征为:\n',sj.columns)
190 print('用水量和波动特征构造完成后数据的前5行5列特征为:\n',sj.iloc[:5,:5])
191 # 筛选候选洗浴事件
192 sj_bool = (sj['用水时长'] >100) & (sj['总用水时长'] > 120) & (sj['总用水量'] > 5)
193 sj_final = sj.loc[sj_bool,:]
194 sj_final.to_excel('sj_final.xlsx',index=False)
195 print('筛选出候选洗浴事件前的数据形状为:',sj.shape)
196 print('筛选出候选洗浴事件后的数据形状为:',sj_final.shape)
197
198 # 模型构建
199 # 读取数据
200 Xtrain = pd.read_excel('sj_final.xlsx')
201 ytrain = pd.read_excel('D:/anaconda/data/water_heater_log.xlsx')
202 test = pd.read_excel('D:/anaconda/data/test_data.xlsx')
203 # 训练集测试集区分。
204 x_train, x_test, y_train, y_test = Xtrain.iloc[:,5:],test.iloc[:,4:-1],\
205 ytrain.iloc[:,-1],test.iloc[:,-1]
206 # 标准化
207 stdScaler = StandardScaler().fit(x_train)
208 x_stdtrain = stdScaler.transform(x_train)
209 x_stdtest = stdScaler.transform(x_test)
210 # 建立模型
211 # 经过参数优化,发现两个隐藏层,隐藏节点分别为17和10时,优化效果较好
212 bpnn = MLPClassifier(hidden_layer_sizes = (17,10), max_iter = 200, solver = 'lbfgs',random_state=50)
213 bpnn.fit(x_stdtrain, y_train)
214 # 保存模型
215 joblib.dump(bpnn,'water_heater_nnet.m')
216 print('构建的模型为:\n',bpnn)
217
218 # 模型检验
219 # 模型评价
220 bpnn = joblib.load('water_heater_nnet.m') # 加载模型
221 y_pred = bpnn.predict(x_stdtest) # 返回预测结果
222 print('神经网络预测结果评价报告:\n',classification_report(y_test,y_pred))
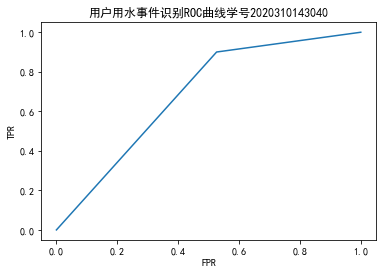
223 # 绘制roc曲线图
224 plt.rcParams['font.sans-serif'] = 'SimHei' # 显示中文
225 plt.rcParams['axes.unicode_minus'] = False # 显示负号
226 fpr, tpr, thresholds = roc_curve(y_pred,y_test) # 求出TPR和FPR
227 plt.figure(figsize=(6,4)) # 创建画布
228 plt.plot(fpr,tpr) # 绘制曲线
229 plt.title('用户用水事件识别ROC曲线学号2020310143040') # 标题
230 plt.xlabel('FPR') # x轴标签
231 plt.ylabel('TPR') # y轴标签
232 plt.savefig('D:/anaconda/data/用户用水事件识别ROC曲线.png') # 保存图片
233 plt.show() # 显示图形



 浙公网安备 33010602011771号
浙公网安备 33010602011771号