打怪升级之小白的大数据之旅(二十)<Java面向对象进阶之集合三Set集合>
打怪升级之小白的大数据之旅(二十)
Java面向对象进阶之集合三Set集合
上次回顾
Set集合
因为set集合没有并没有什么特别强调的地方,它跟collection差不多,因此就简单介绍一下,它的重点是它的实现类
- Set接口是Collection的子接口,同样继承了Collection的方法
- Set接口没有提供额外的方法,但是比Collection接口更加严格:
- Set 集合不允许包含相同的元素,即元素唯一
- Set集合没有索引
- Set集合支持的遍历方式和Collection集合一样:foreach和Iterator,因为没有索引,因此不支持普通for循环
- Set的常用实现类有:HashSet、TreeSet、LinkedHashSet。
HashSet(java.util.HashSet)
概述
- HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类
- HashSet 底层的实现其实是一个java.util.HashMap支持,然后HashMap的底层物理实现是一个Hash表
- 它存储的元素是唯一的,无序的
- 哈希表的查询效率要优于链表
- HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能
Hash表
Hash表的底层结构是链表和数组,既继承了数组的查询块优点,又继承了链表增删块的优点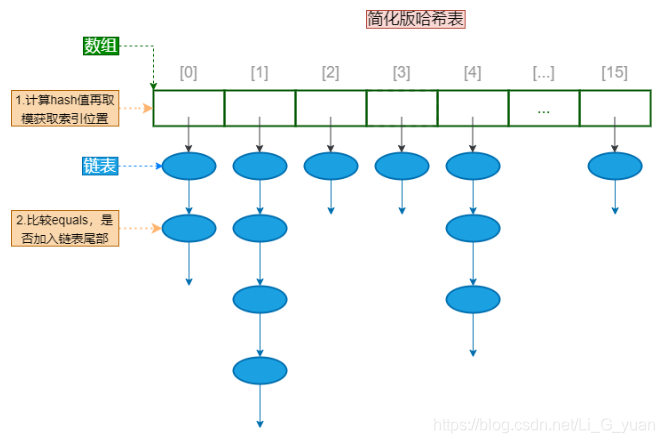
- Hash表的存储原理
- 当有存储一个数据时,会先计算该数据的hash值,再进行取模,获取其索引位置,比如我定义了一个15个元素的集合,那么就对其进行取模15,就会得到0~14的索引
- 接着,会调用equals方法对数据进行比对,进行去重处理,没有重复的,就会添加到索引对应位置的链表尾部,因为没有需要回退的必要,因此,它是一个单向链表
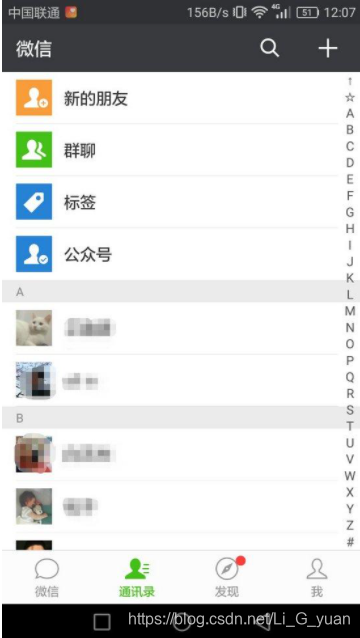
- 举个实际例子来理解哈希表
![在这里插入图片描述]()
- 通讯录就相当于一个哈希表,它首先会有A-Z的数组,然后根据首字母进行存储,我们根据首字母后,还需要自上而下进行查看才可以看到所需要的电话(链表也是这么查看的)
HashSet基本方法
它没有什么特殊的方法,因此我直接使用示例代码来展示它的方法了
- 系统类型创建集合
import org.junit.Test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
// hashset的实现类练习
public class Demo {
// 创建数组集合
@Test
public void hashSetIntTest() {
// 创建集合对象
HashSet<Integer> intHash = new HashSet<>();
// 添加元素
intHash.add(25);
intHash.add(12);
intHash.add(23);
intHash.add(4);
intHash.add(11);
intHash.add(12);
intHash.add(17);
// 删除元素
intHash.remove(17);
// 获取元素长度
System.out.println("intHash.size() = " + intHash.size());
// 遍历方式一 迭代器遍历
Iterator<Integer> it = intHash.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
System.out.println("---------------------------");
// 遍历方式二 增强for
for (Integer num : intHash) {
System.out.println(num);
}
}
// 创建字符串集合
@Test
public void hashSetStringTest() {
// 创建字符串集合对象
Set<String> strHash = new HashSet<>();
// 添加元素
strHash.add("hello");
strHash.add("world");
strHash.add("hello");
strHash.add("中国");
// 遍历方式一 iterator迭代器遍历
Iterator<String> strIt = strHash.iterator();
while (strIt.hasNext()) {
System.out.println(strIt.next());
}
// 遍历方式二 增强for 遍历
for (String str : strHash) {
System.out.println(str);
}
}
}
这里注意一下,因为HashSet没有索引,因此删除元素时只能传递需要删除的对象
- 自定义对象创建集合
import org.junit.Test; import java.util.HashSet; // hashset的实现类练习 public class Demo { // 创建对象集合 @Test public void hashSetInstranceTest(){ // 创建集合对象 HashSet<Student> instranceHash = new HashSet<>(); // 添加元素 instranceHash.add(new Student("张三丰",18)); instranceHash.add(new Student("李小龙",19)); instranceHash.add(new Student("林冲",25)); instranceHash.add(new Student("孙悟空",500)); instranceHash.add(new Student("孙悟空",500)); // 遍历 for (Student stu : instranceHash) { System.out.println(stu); } } } class Student{ private String name; private int age; // 创建构造器 public Student(String name, int age) { this.name = name; this.age = age; } // 定义getter/setter方法 public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } // 重写toString方法 @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } }
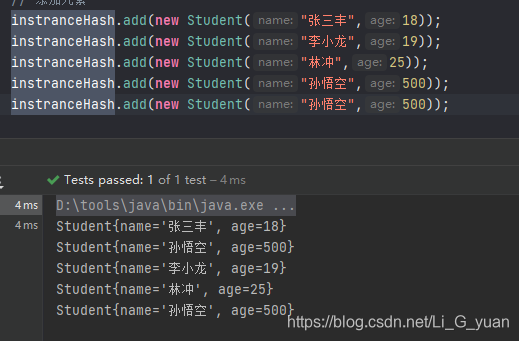
咦?不是说好Set默认去重的么?为什么这里,孙悟空这个对象并没有去重呢?
重写HashCode
当我们自定义创建一个对象时,JVM并不知道应该怎么比较大小,源码如下:
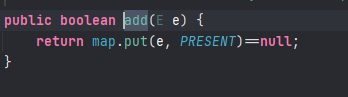
add方法调用的是map中的put方法,这里下一章会讲解原因
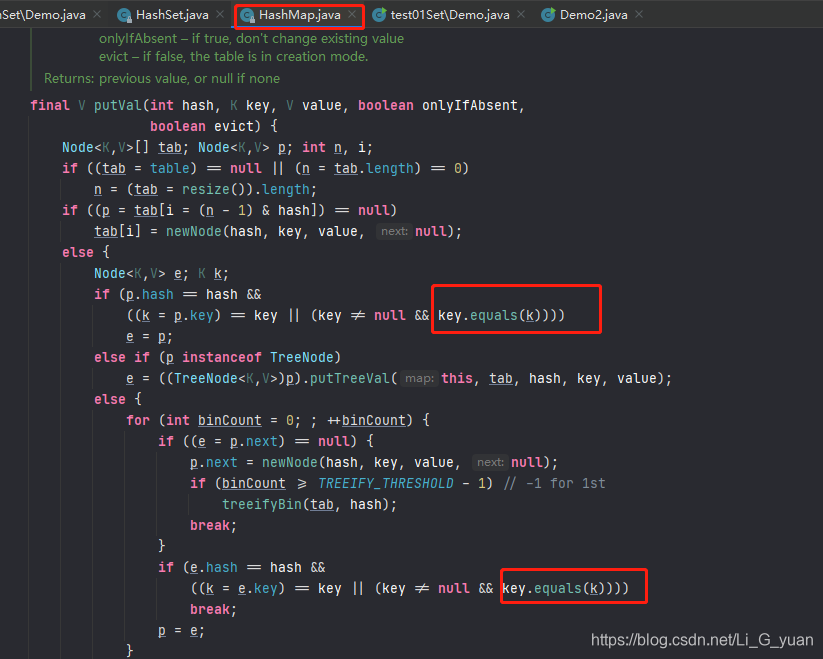
而在我put方法中,是对其进行equals比较的,

而我们将自定义对象添加到集合中时,JVM会当作两个新的对象存储,在内存中,new了两个孙悟空对象并开辟了两个内存空间,equals当然会认为它们是两个对象了
-
好了,原理解释清楚了,下面我应该怎么做呢?
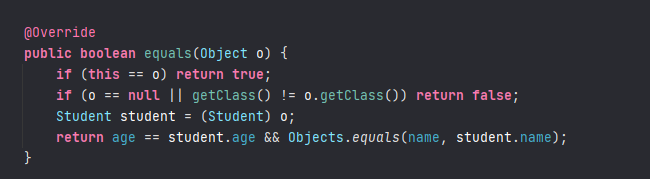
- 是不是直接在创建这个类中,重写equals方法就好了呢?就像这样:
![在这里插入图片描述]()
为什么不行呢?它还是没有去重??
![在这里插入图片描述]()
因为我前面说了,Set的底层的数据结构是哈希表,它在存储时,首先会计算对象进行hashCode然后通过取模来确定它的存储位置,然后再会对该对象进行equals比对去重
- 是不是直接在创建这个类中,重写equals方法就好了呢?就像这样:
-
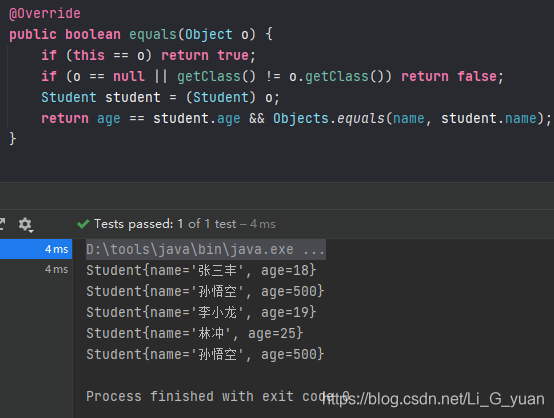
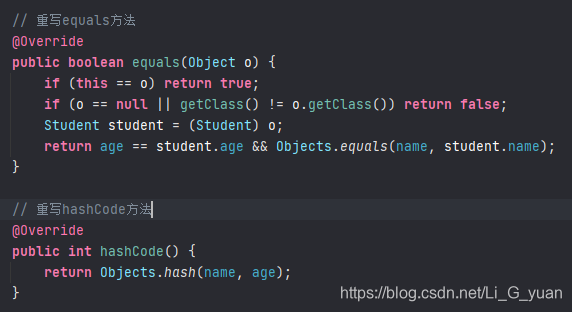
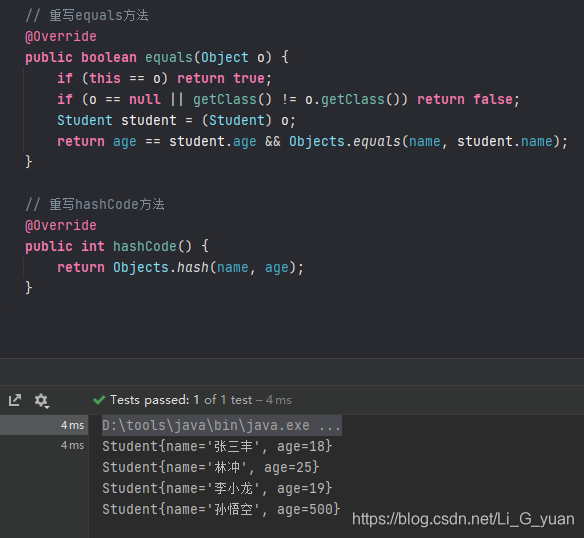
所以,我们需要再重写他的hashCode方法才可以:正确的方法如下:
![在这里插入图片描述]()
-
这次运行后,果真去重了
![在这里插入图片描述]()
好了,基本上HashSet的具体就介绍完了。记住我们后面需要自定义对象并存储为Set集合中时,一定要重写hashCode和equals方法
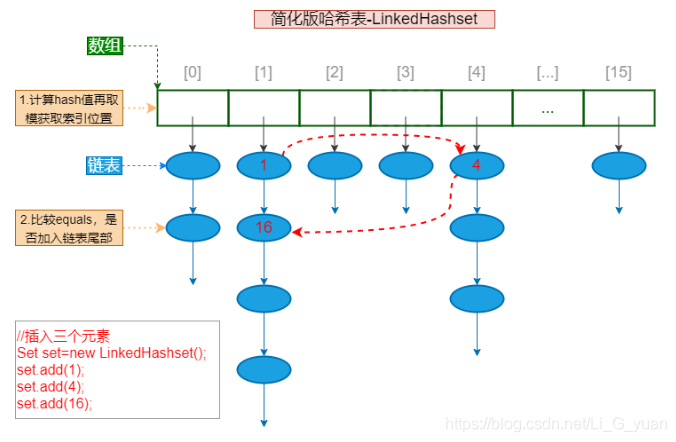
LinkedHashSet
- 这货是HashSet的子类,顾名思义,它继承了所有HashSet的属性和方法,那么它有什么作用呢?答案就是顺序,因为前面说了Set是无序的,我们添加对象时的顺序是一个样,真正输出的时候又是另外一个样
- 原理就是它在HashSet的基础上,在结点中增加两个属性before和after维护了结点的前后添加顺序。java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能
- 它的链表原理参考LinkedList就好啦
- 就像这样:
![在这里插入图片描述]()
好了,举个例子就结束对它的介绍了,实在没什么太多知识点可讲的
import org.junit.Test;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Objects;
// hashset的实现类练习
public class Demo {
// 创建对象集合
@Test
public void hashSetInstranceTest(){
// 创建LinkedHashSet
LinkedHashSet<String> set = new LinkedHashSet<>();
// 添加元素
set.add("张三");
set.add("李四");
set.add("王五");
set.add("张三");
// 遍历
System.out.println("元素个数:" + set.size());
for (String name : set) {
System.out.println(name);
}
}
}
TreeSet
概念
- 它是Set中另一个重要的Set实现类
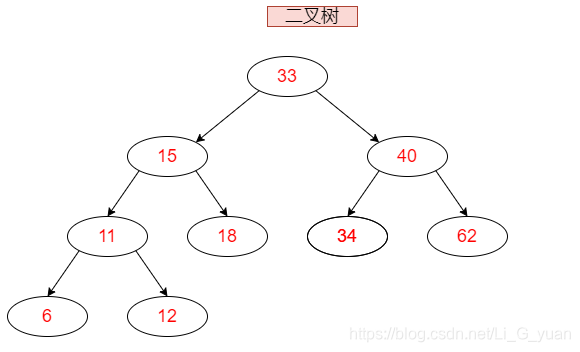
- 类如其名,它的底层结构是以二叉树的结构进行存储,就像这样
![在这里插入图片描述]()
- 准确一点,它的底层结构是红黑树,这是一种相对平衡的二叉树,它的查询效率高于链表,等下下面为大家讲解一下二叉树与红黑树,我先把TreeSet介绍完…
TreeSet特点
- TressSet最大的特点就是可以对该集合进行排序
- 它第二个特点就是去重
- 等会介绍完二叉树我就为大家介绍一下TreeSet的去重和排序逻辑,了解清楚这两个,也是为下一期Mapping做个铺垫
二叉树与红黑树
二叉树
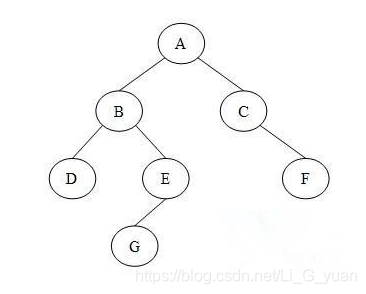
- 首先,二叉树,就像它的名字,它像一颗倒置的树,并且它的每个节点只有两个分叉,如图:
![在这里插入图片描述]()
- 它的顶点,也就是图中⑩的位置,称作根(root),它的分支元素,及两个不相交的、被分别称为左子树(在图中是⑤)和右子树(在图中⑰)的二叉树组成,它是有序树。当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称作一个节点
- 在存储元素时,默认把小的存左子树,大的存右子树,这就要求元素可以比较大小
- 接着,普及一下二叉树的遍历原理,它有三种遍历方式:
- 前序遍历,即 中左右
- 中序遍历,即 左中右
- 后序遍历,即 左右中
- 我们的TreeSet遍历采用的是中序遍历,就按上图的例子,左中右的遍历结果就是: 6 11 23 15 18 33 34 40 62
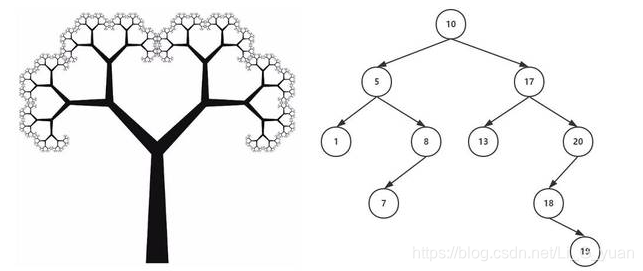
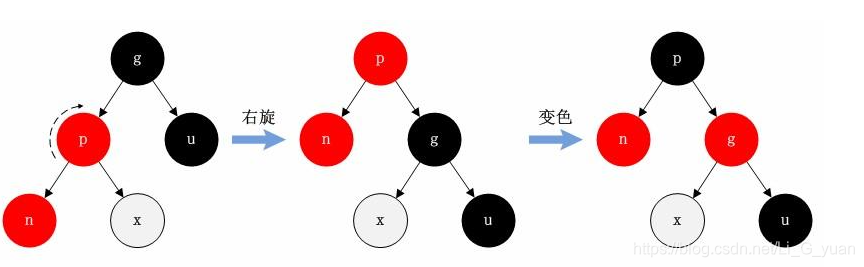
红黑树
- 红黑树也称为平衡二叉树,它为了避免左右子树元素不对称而影响遍历效率时,就会采用红黑树这种相对平衡的二叉树,就像下图这样
![在这里插入图片描述]()
- 红黑树原理:
- 红黑树的原理就是设定节点分别是红色和黑色,通过算法和颜色的变换来追求完美的平衡
- 平衡二叉树追求绝对的平衡,左右子树的差值不能超过1,底层的算法就不讲了,有点复杂,大家可以度娘详细了解,但不建议,因为我们是搞大数据的~~~
![在这里插入图片描述]()
TreeSet的去重与排序
- 首先,演示一下TreeSet集合的创建与遍历,没有什么特殊的:
package test04TreeSetComparator; // TreeSet案例 import org.junit.Test; import java.util.Set; import java.util.TreeSet; public class Demo2 { // 将基本数据类型存储到TreeSet中 @Test public void Test1(){ // 创建TreeSet集合 Set<Integer> intSet = new TreeSet<>(); // 添加元素 intSet.add(1); intSet.add(21); intSet.add(11); intSet.add(10); intSet.add(122); // 遍历 for (Integer num : intSet) { System.out.println(num); } } // 将字符串存储到TreeSet中 @Test public void Test2(){ // 创建TreeSet集合 Set<String> intSet = new TreeSet<>(); // 添加元素 intSet.add("abc"); intSet.add("hello"); intSet.add("bd"); intSet.add("zz"); intSet.add("apple"); // 遍历 for (String num : intSet) { System.out.println(num); } } } ```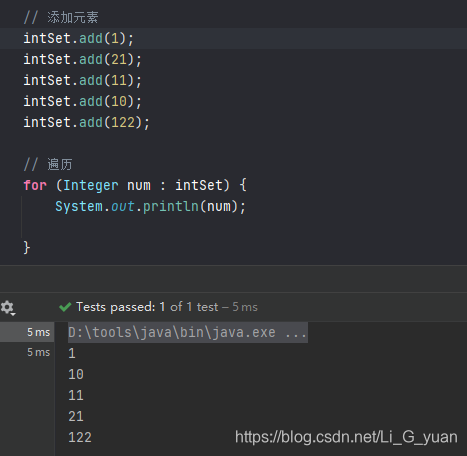
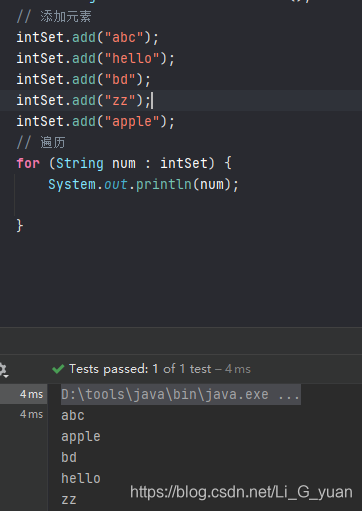
- 上面两个示例,我们看到,它确实对数据进行了排序,数字是按照大小排序的,而字符串是按照字母的首字母进行排序,如果相同,那么就会比对第二个字母,假如我们想让字符串按照长短排序呢?别急,先看下面的示例:
import java.util.Set; import java.util.TreeSet; public class Demo { public static void main(String[] args) { // 自定义对象排序,自然排序 Set<Employee> emp = new TreeSet<>(); emp.add(new Employee(10011,"tom",10000)); emp.add(new Employee(10210,"jary",20000)); emp.add(new Employee(10320,"jack",13000)); emp.add(new Employee(10210,"rose",10500)); emp.add(new Employee(10221,"tom",32000)); emp.add(new Employee(10221,"jack",20000)); // 遍历 for (Employee employee : emp) { System.out.println(employee); } } } // Employee类 class Employee{ // 定义属性 private String name; private int id; private double salary; // 定义构造器 public Employee(int id, String name, double salary) { this.id = id; this.name = name; this.salary = salary; } // 定义getter/setter方法 public String getName() { return name; } public void setName(String name) { this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public double getSalary() { return salary; } public void setSalary(double salary) { this.salary = salary; } // 重写toString @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", id=" + id + ", salary=" + salary + '}'; } }

-
咦?为什么无法遍历?而且告诉我们没法进行Comparable?还记得前面说的TreeSet的概念吗?它的底层是一个红黑树,而二叉树在存储元素时,默认把小的存左子树,大的存右子树,这就要求元素可以比较大小,在前面我们介绍HashSet也提到过,自定义对象JVM是不知道怎么比较大小的,因此,我们需要自定义一个比较大小的方法
-
但为什么前面Int类型和字符串类型的数据都可以比较大小呢?请看下图:
![在这里插入图片描述]()
下面是字符串的源码
![在这里插入图片描述]()
我们可以看到,无论是Integer类型还是String类型,它们底层都实现了Comparable这个接口![在这里插入图片描述]()
-
我们回到集合的开篇,集合的这个框架图中我们可以看到,集合框架中有针对对象的两个排序接口,Comparable和Comparator
-
而Comparable的底层就是对它们的ASCII码进行比对,才实现了排序
-
Comparator接口继承了Comparable,目的就是为了可以让我们自定义排序规则
-
好了,了解清楚了这些,我们对上面这个自定义对象进行改造
package test04TreeSetComparator; import java.util.Comparator; import java.util.Set; import java.util.TreeSet; /* * 1.使用TreeSet存储字符串元素,按照字符串的长度进行降序排序 * 2.使用TreeSet存储自定义对象Employee,属性: id, name,salary * ①自然排序: 薪资升序,id升序,name升序 * ②自定义排序,薪资降序,id升序,name升序 * */ public class Demo { public static void main(String[] args) { // 字符串长度排序 Set<String> strTree= new TreeSet<>(new Comparator<String>() { @Override public int compare(String o1, String o2) { int i = o2.length()- o1.length(); i = i==0?o1.compareTo(o2):i; return i; } }); strTree.add("tom"); strTree.add("jack"); strTree.add("as"); strTree.add("aoligai"); strTree.add("computers"); strTree.add("msi"); strTree.add("thshtunxhusangd"); for (String s : strTree) { System.out.println(s); } System.out.println("----------------------------------"); // 自定义对象排序,自然排序 Set<Employee> emp = new TreeSet<>(); emp.add(new Employee(10011,"tom",10000)); emp.add(new Employee(10210,"jary",20000)); emp.add(new Employee(10320,"jack",13000)); emp.add(new Employee(10210,"rose",10500)); emp.add(new Employee(10221,"tom",32000)); emp.add(new Employee(10221,"jack",20000)); // 遍历 for (Employee employee : emp) { System.out.println(employee); } System.out.println("-------------------------------"); // 自定义对象排序,自定义排序 Set<Employee> emp1 = new TreeSet<>(new Comparator<Employee>() { @Override public int compare(Employee o1, Employee o2) { int i = Double.compare(o2.getSalary(),o1.getSalary()); i = i == 0 ? o1.getId() - o2.getId() :i; i = i == 0 ? o1.getName().compareTo(o2.getName()):i; return i; } }); emp1.add(new Employee(10011,"tom",10000)); emp1.add(new Employee(10210,"jary",20000)); emp1.add(new Employee(10320,"jack",13000)); emp1.add(new Employee(10210,"rose",10500)); emp1.add(new Employee(10221,"tom",32000)); emp1.add(new Employee(10221,"jack",20000)); // 遍历 for (Employee employee : emp1) { System.out.println(employee); } } } // Employee类 class Employee implements Comparable{ // 定义属性 private String name; private int id; private double salary; // 定义构造器 public Employee(int id, String name, double salary) { this.id = id; this.name = name; this.salary = salary; } // 定义getter/setter方法 public String getName() { return name; } public void setName(String name) { this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public double getSalary() { return salary; } public void setSalary(double salary) { this.salary = salary; } // 重写toString @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", id=" + id + ", salary=" + salary + '}'; } // 自然排序 @Override public int compareTo(Object o) { Employee emp = (Employee)o; int i = Double.compare(this.getSalary(),emp.getSalary()); i = i == 0 ? this.getId() - emp.getId() :i; i = i == 0 ? emp.getName().compareTo(this.getName()):i; return i; } } ```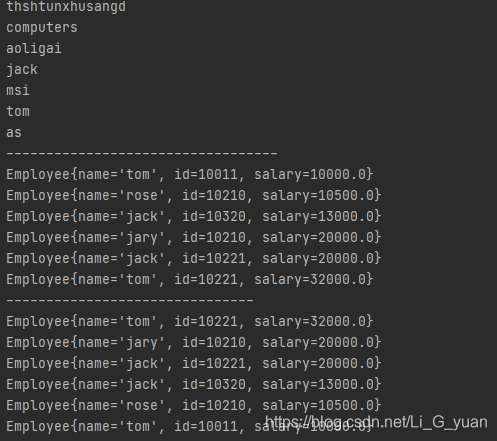 -
我对这个员工类进行改造,让他也成为Comparable实现类并且重写了compareTo的排序规则
-
好了,成功运行并且排序了,而且我重写了字符串的排序规则后也可以成功对其安装字符串的长度排序了
-
这里注意,当我同时使用Comparable和Comparator时,依旧是就近原则
-
Comparator这个实现使用的是前面学习的匿名类的手法(忘了的可以回头看一下匿名类那一章)
-
TreeSet介绍完了,到此,整个Collection基本介绍完了,为什么说是基本,因为还有前面留的那个坑(HashSet的add使用的是Map的put方法)


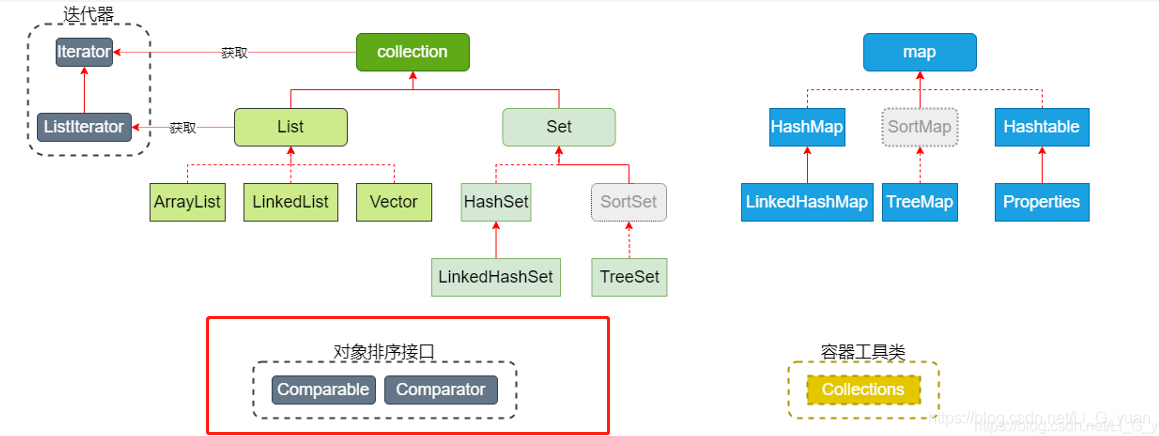
Collection集合小结
首先我将整个Collecton关系做了个图
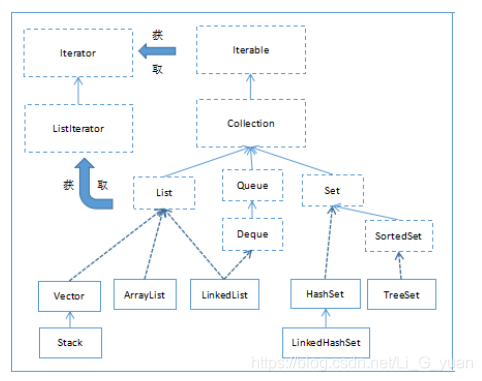
再结合集合框架图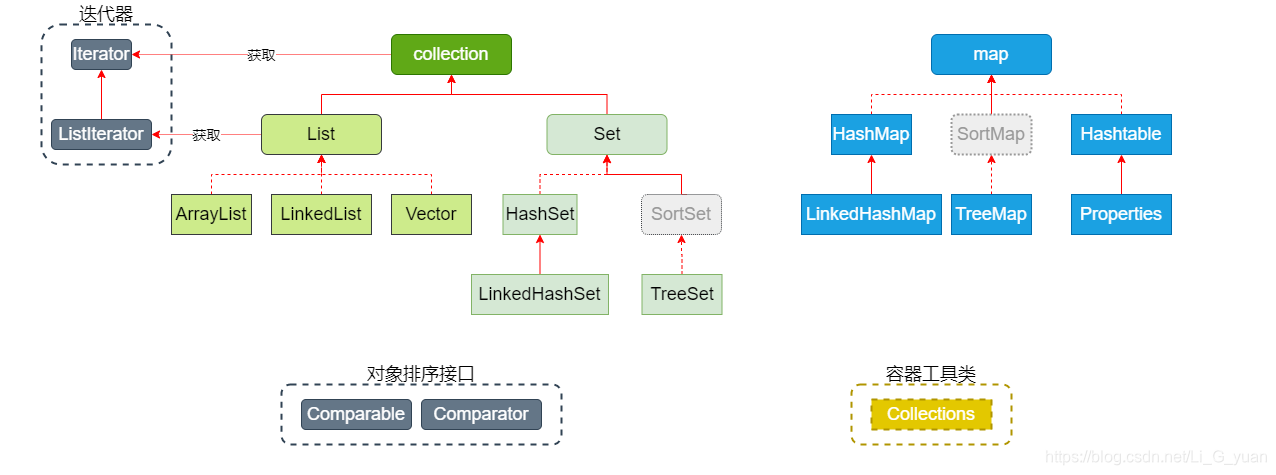
Collection:集合根接口,存储一组对象。
- List:接口,特点是,元素可重复,有序(存取顺序一致)
- ArrayList:底层结构为数组,查询快,增删慢,线程不安全
- LinkedList:底层结构为链表,查询慢,增删快
- Vector:底层结构为数组,线程安全,效率低,不推荐使用
- Set:接口,特点是,元素唯一
- Hash表 = 数组+链表
- HashSet:底层结构为Hash表,查询和增删效率都高
- TreeSet:底层结构为红黑树,查询效率高于链表,增删效率高于数组,元素实现排序
- LinkedHashSet:底层结构为hash表+链表,在哈希表基础上维护了一个链表,保证元素的有序
总结
- 本章,我介绍了Hash表的原理、树形结构–二叉树,以及Set集合中的各个实现类及其原理
- 到目前为之,我们已经基本介绍完了Collection,迭代器和对象排序接口,这么多的实现类主要目的就是为了满足不同的实际需求:
- 当我们需要重复的有序数据时,那么就使用List集合中的ArrayList,对增删元素要求高,就使用LinkedList
- 当我们需要对元素进行去重,就使用Set中的HashSet,需要让元素安装我们添加的元素展示,就使用LinkedHashSet,需要对元素进行排序时就使用TreeSet集合
- 下一章,我会对集合的最终章:Map集合进行介绍,对于本章中的知识点,有疑问或我代码、原理解释有问题,欢迎后台留言,相互学习,相互探讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号