【李宏毅机器学习】(一)正确认识ChatGPT
该文是一篇机器学习的学习笔记,学习内容:李宏毅2023春机器学习课程
ChatGPT(Chat Generative Pre-trained Transformer) 是一个以对话的方式进行交互的语言模型,由 OpenAI 发布。
常见误解
对 ChatGPT 的常见误解:
- ChatGPT 是从开发者事先准备好的答案里随机抽取一个回答。
- ChatGPT 的答案是网络搜寻的结果。
ChatGPT 的工作原理是文字接龙:
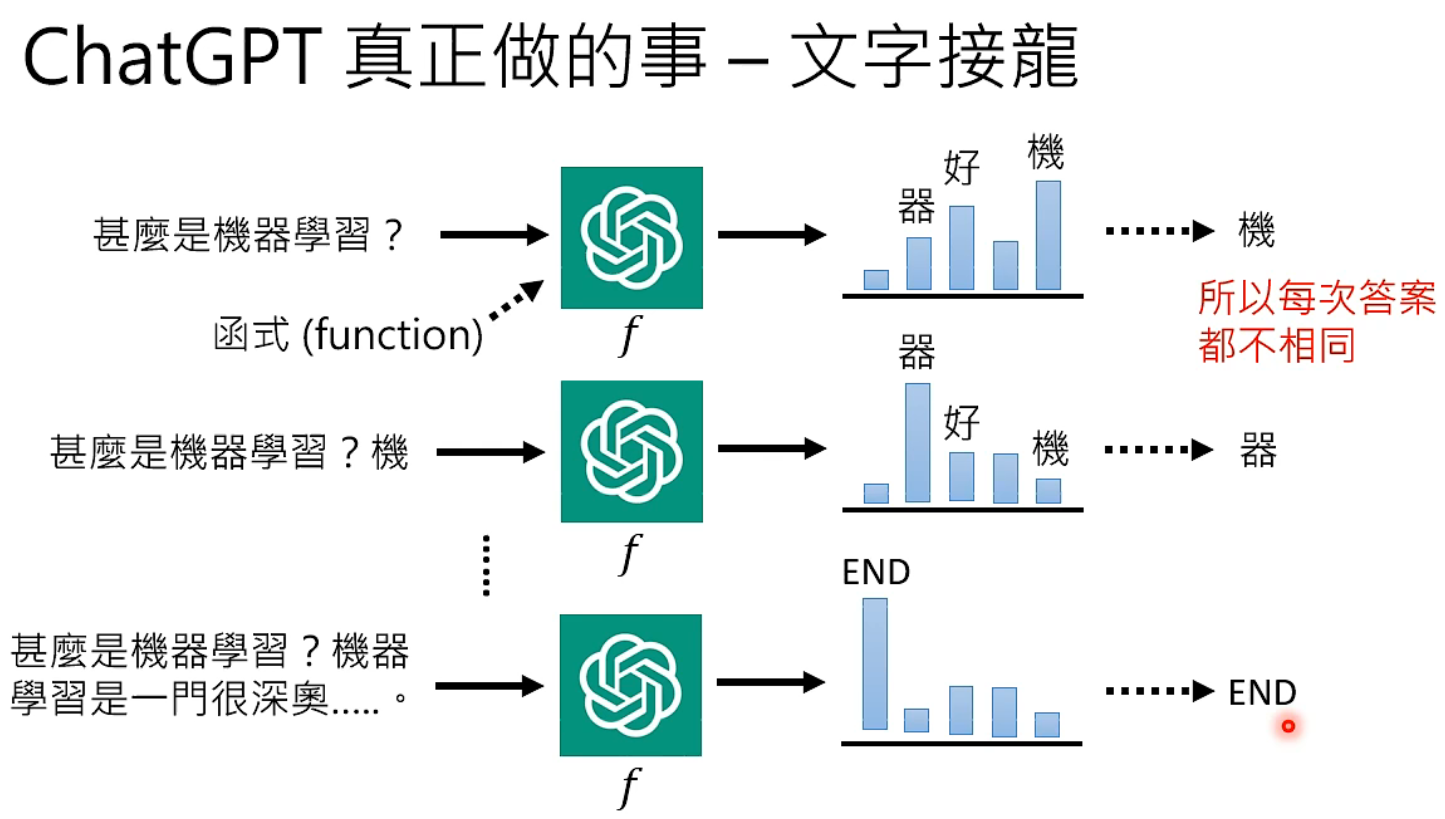
ChatGPT 将问题作为 input 传入 function,得到的 output 是 input 后应该接的词汇的概率分布。ChatGPT 从分布中 sample 一个词汇,并将其加到原来的 input 得到新的 input,重复操作,知道 sample 到结束符。
ChatGPT 是如何根据上下文回答问题?
ChatGPT 将同一则对话的历史记录+新问题作为 input 传入 function。
ChatGPT 的 function 是如何找到的?
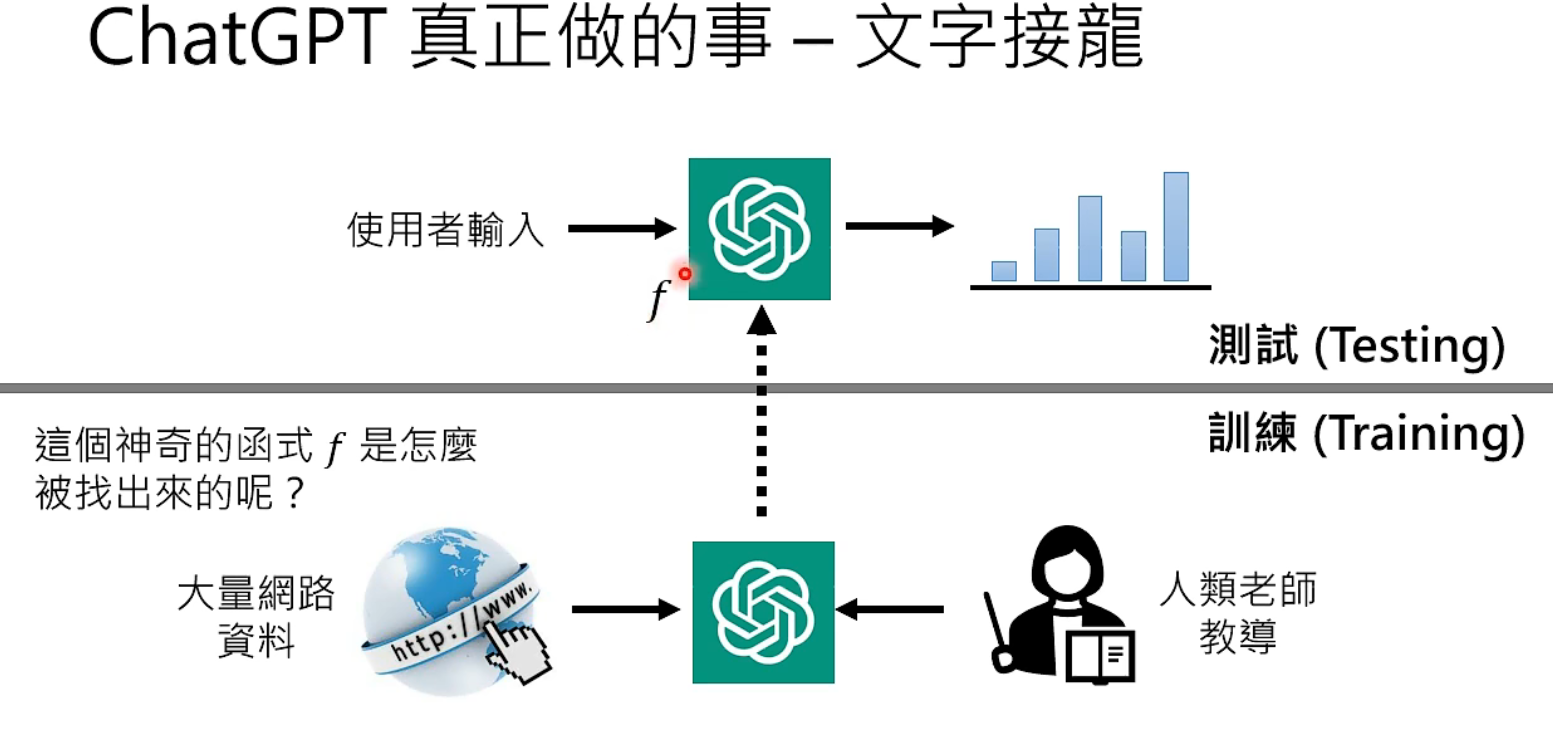
function 是在训练过程中由开发者和大量网络资料一起推导出来的。function 包含上亿个参数(如 f = ax + b 里,a 和 b 就是参数)
预训练(Pre-train)
ChatGPT 背后的关键技术:预训练(Pre-train),又叫自督导式学习(Self-supervised Learning)。预训练得到的模型叫基石模型(Foundation Model)。
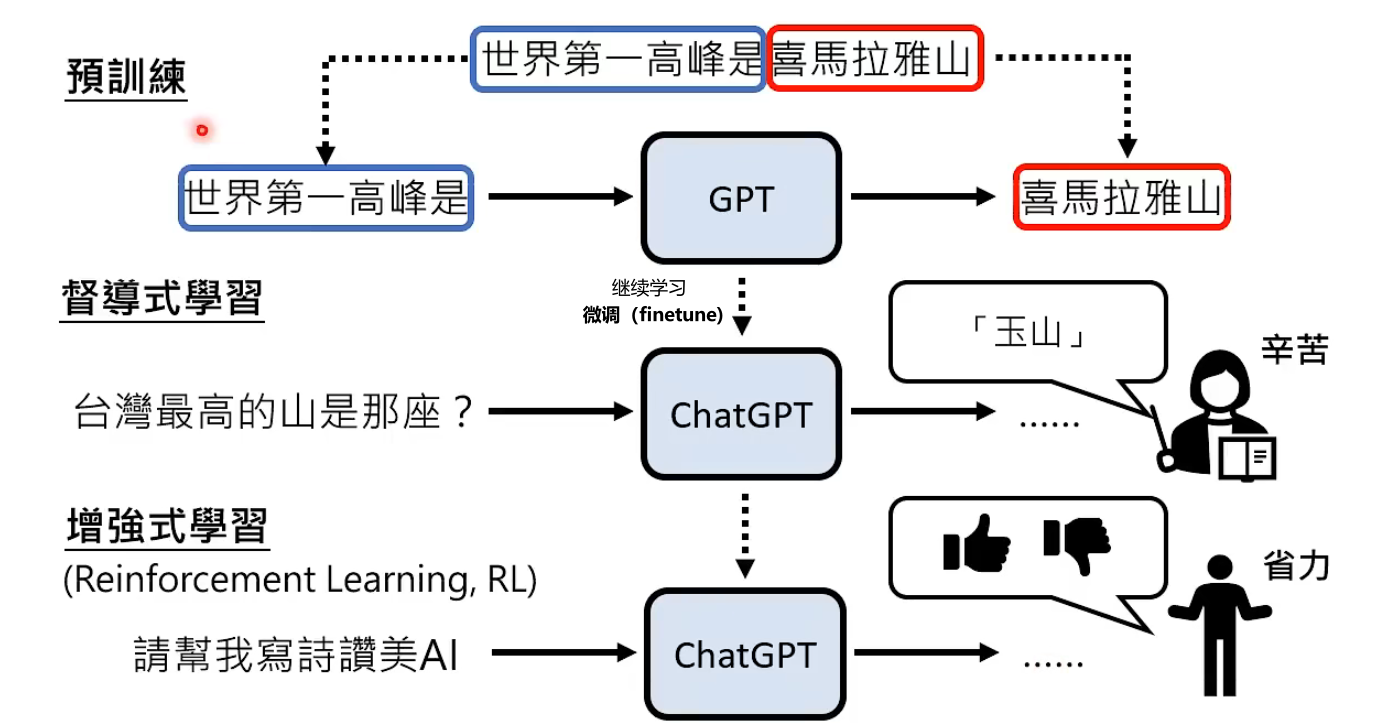
ChatGPT 训练的三个步骤:
-
预训练从网络资料学习文字接龙。网络上每一段文字都可以无痛制造成对资料来教机器做文字接龙,缺点是预训练出的 GPT 对于一些问题的回答不一定是我们想要的。
-
为了引导 GPT 产生有用的输出,需要对 GPT 进行督导式学习,由开发者提供成对的资料进行训练,引导文字接龙的方向。
-
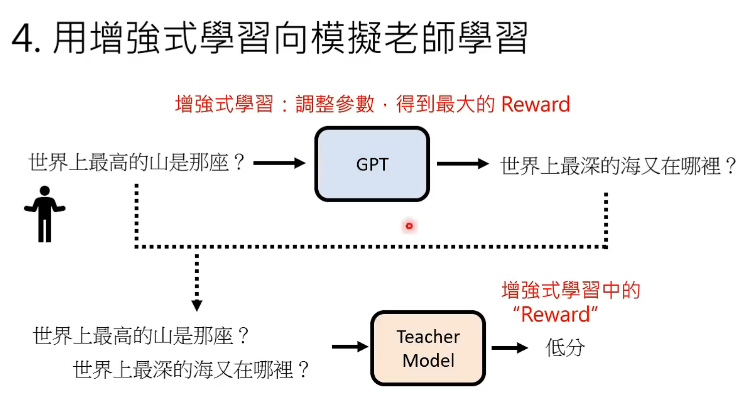
还会对 ChatGPT 进行增强式学习,相较于督导式学习,开发者不用给出答案,只需要对结果回馈对错。为了节省人力,可以通过模拟人类老师的喜好训练 Teacher Model,用增强式学习向模拟老师学习。
ChatGPT 带来的研究问题
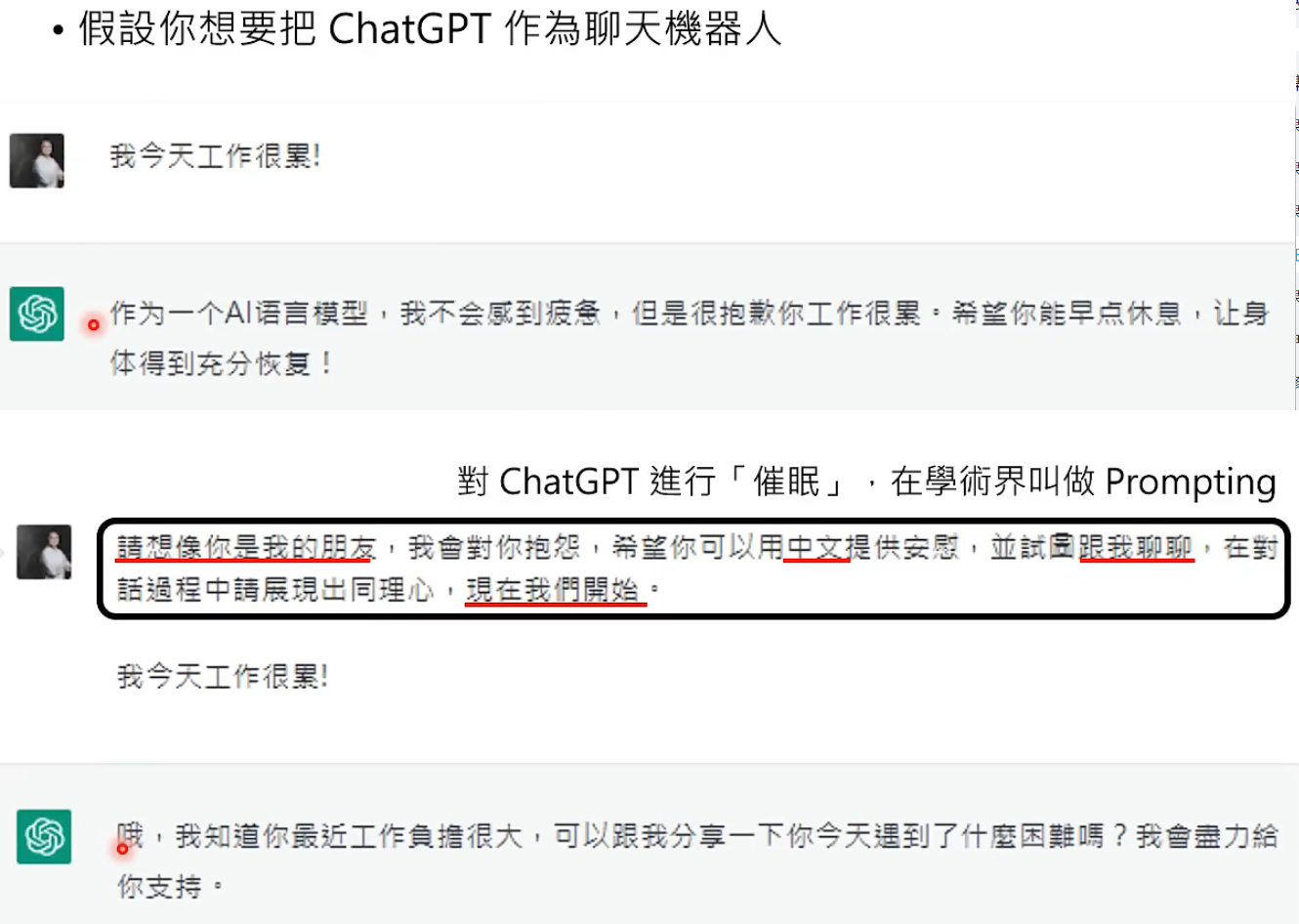
- 如何精准提出需求。
- 如何更正错误。当回答出现错误时,我们对其进行更正,反而会带来更多新的错误。新研究课题【Neural Editing】就是研究如何避免这种情况。

- 侦测 AI 生成的物件。怎样用模型侦测一段文字是否为 AI 生成,同样的概念可以被用到语音、影像上。
- 不小心泄露隐私。想让 ChatGPT 遗忘一些不该知道的内容,新研究课题【Machine Unlearning】。
本文来自博客园,作者:hzyuan,转载请注明原文链接:https://www.cnblogs.com/hzyuan/p/17418954.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号