

【MySQL】多表查询的各种JOIN算法
引言
多表连接的核心是根据指定的连接条件从表之间筛选出匹配的行并组合成结果集,其底层的执行过程并不会固定采用单一的某种算法,而是由优化器根据表的大小、索引情况、数据分布等因素,自动选择最优的连接算法来执行。
1.索引嵌套循环连接(Index Nested-Loop Join)
索引嵌套循环连接利用索引来提高表之间连接操作的效率,适用于被驱动表在连接条件上有索引且索引未失效的情况。其核心思路是避免内层循环的全表扫描,避免外层循环的记录和内层循环的每条记录都进行比较,这样极大的减少了对内层表的匹配次数,从原来的匹配次数=外层表行数内层表行数,变成了外层表的行数内层表索引的高度。
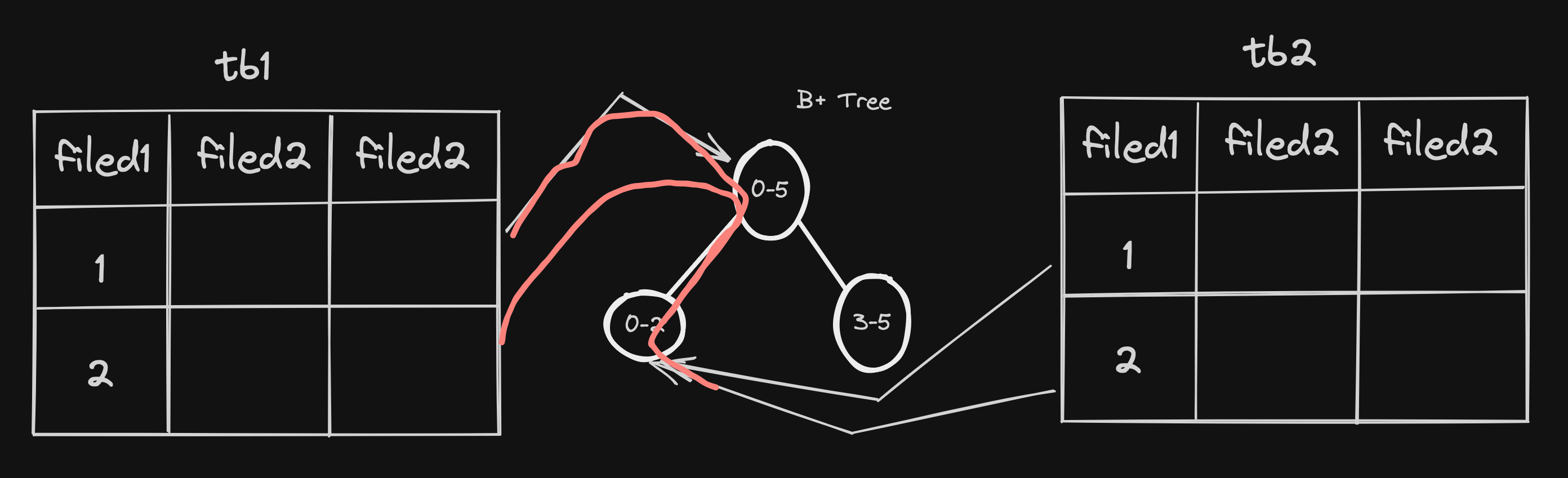
工作过程:
1.选择驱动表:在执行索引连接之前,数据库优化器会选择一个表作为驱动表(通常是较小的表或结果集中行数较少的表)。
2.扫描驱动表:数据库系统会逐一扫描驱动表中的每一条记录。
3.使用索引查找匹配行:对于驱动表中的每一行,数据库系统会使用被连接表上的索引来快速查找满足连接条件的匹配行。索引允许数据库系统直接定位到匹配的行,而无需扫描整个表。
4.结果组合:找到匹配的行后,数据库系统会将它们与驱动表中的当前行组合起来,形成查询结果的一部分。
5.继续扫描:数据库系统继续扫描驱动表的下一行,并重复上述过程,直到扫描完驱动表的所有行。
2.哈希连接(Hash Join)
哈希连接是MySQL8.0及以上版本引入的算法,专门针对两张大表且连接条件为等值连接的场景。其核心思想是通过构建一个哈希表保存驱动表中的数据,再用被驱动表的数据逐一进行匹配,这样就将原来的嵌套循环变成了单层循环。
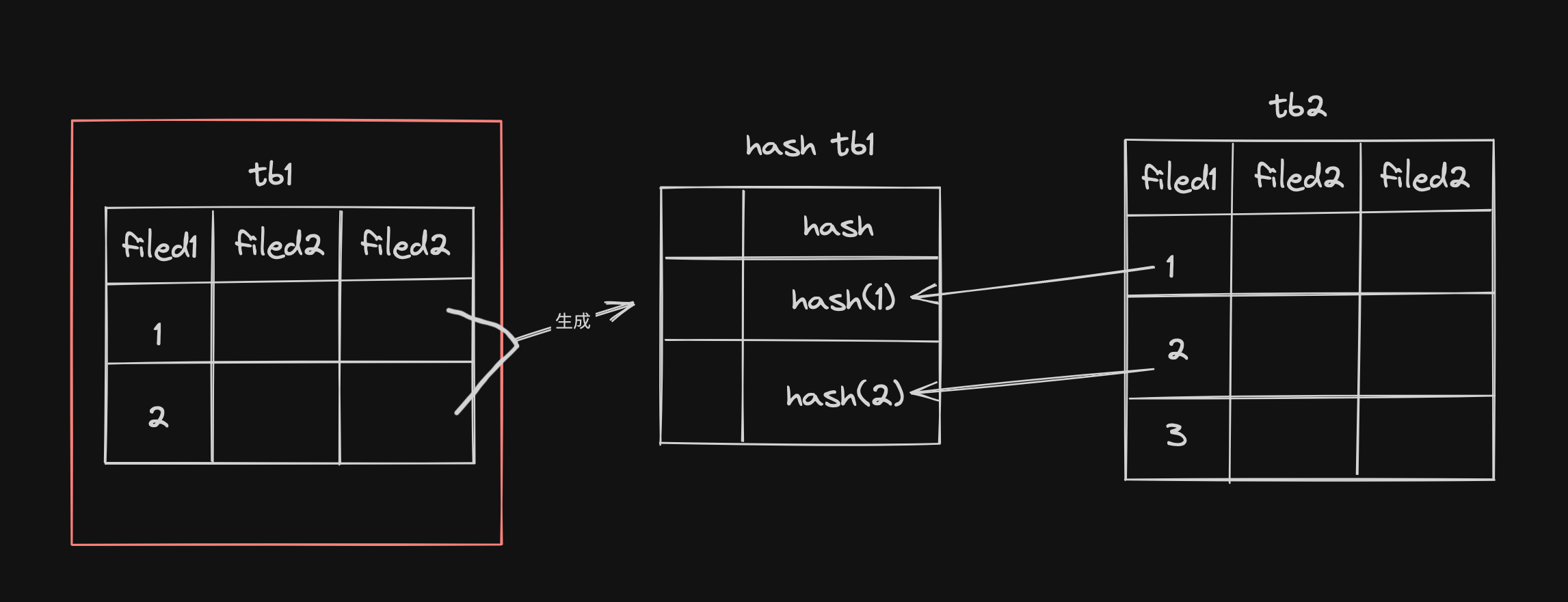
工作过程:
1.构建哈希表:数据库系统会扫描其中驱动表(构建表),并使用哈希函数将连接字段的值与表中的记录构建成一个哈希表。
2.扫描和探测哈希表:数据库系统会扫描被驱动表(探测表),并对其中每一条记录的连接字段应用相同的哈希函数,然后在哈希表中查找相匹配的记录。
3.结果组合:如果找到匹配的记录,数据库系统会将它们与探测表中的当前行组合起来,形成查询结果的一部分。这个过程会持续进行,直到扫描完探测表的所有行。
3.块嵌套循环连接 (Block Nested-Loop Join)
块嵌套循环连接用于被驱动表的连接字段没有索引或索引失效的情况。其核心思路是利用Join Buffer减少读取驱动表的次数,这样就减少了外层循环的循环次数,也就减少了被驱动表的全表扫描的IO次数。
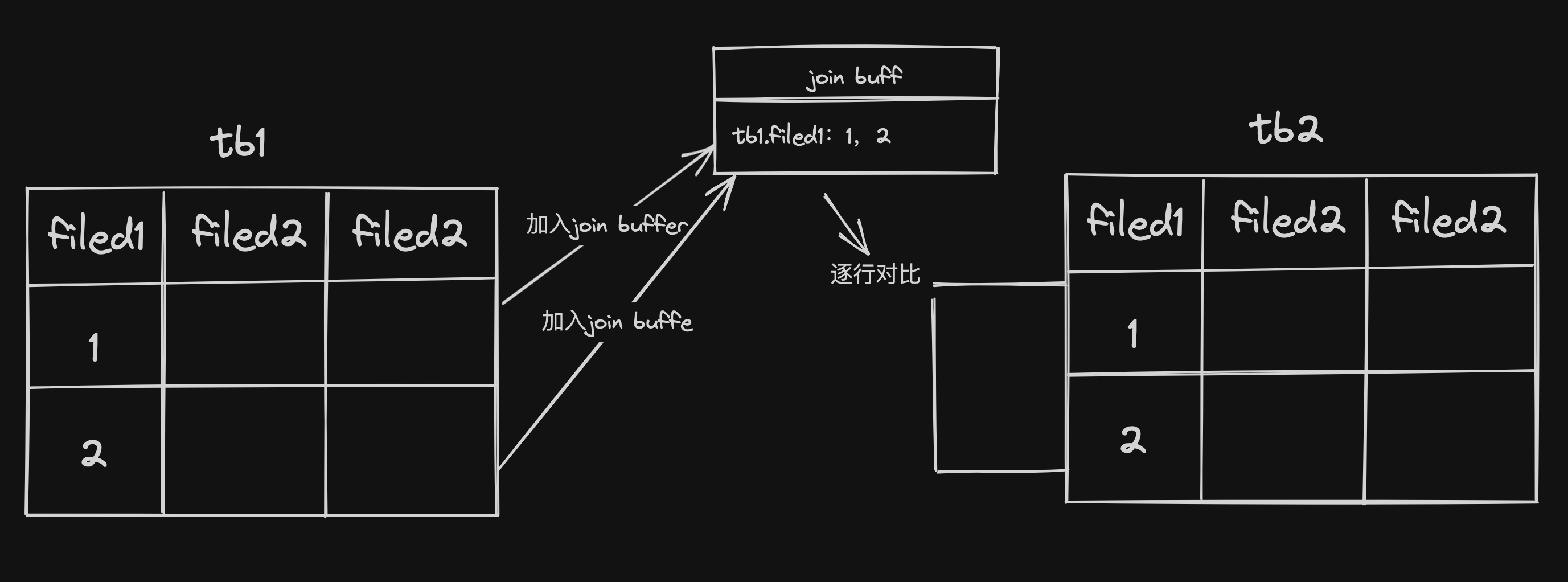
工作过程:
1.填充Join Buffer:数据库会将驱动表的若干行缓存在内存中的Join Buffer中。
2.扫描被驱动表:然后,数据库会全表扫描被驱动表,读取其中的每一行。
3.内存匹配:对于被驱动表的每一行,会与Join Buffer中的所有行进行比较,检查连接条件是否满足。
4.返回结果:如果匹配,就将这两行组合并保存到结果集。
5.清空并重复:处理完被驱动表的所有行后,清空Join Buffer,再从驱动表中读入一批新行,重复上述过程直到驱动表的所有行都处理完毕。
4.简单的嵌套循环连接(Simple Nested-Loop Join)
这是一种基本的连接策略。其核心思想是两层嵌套的循环,外部循环遍历一个表,而内部循环则针对外部循环中的每一行遍历一次表。
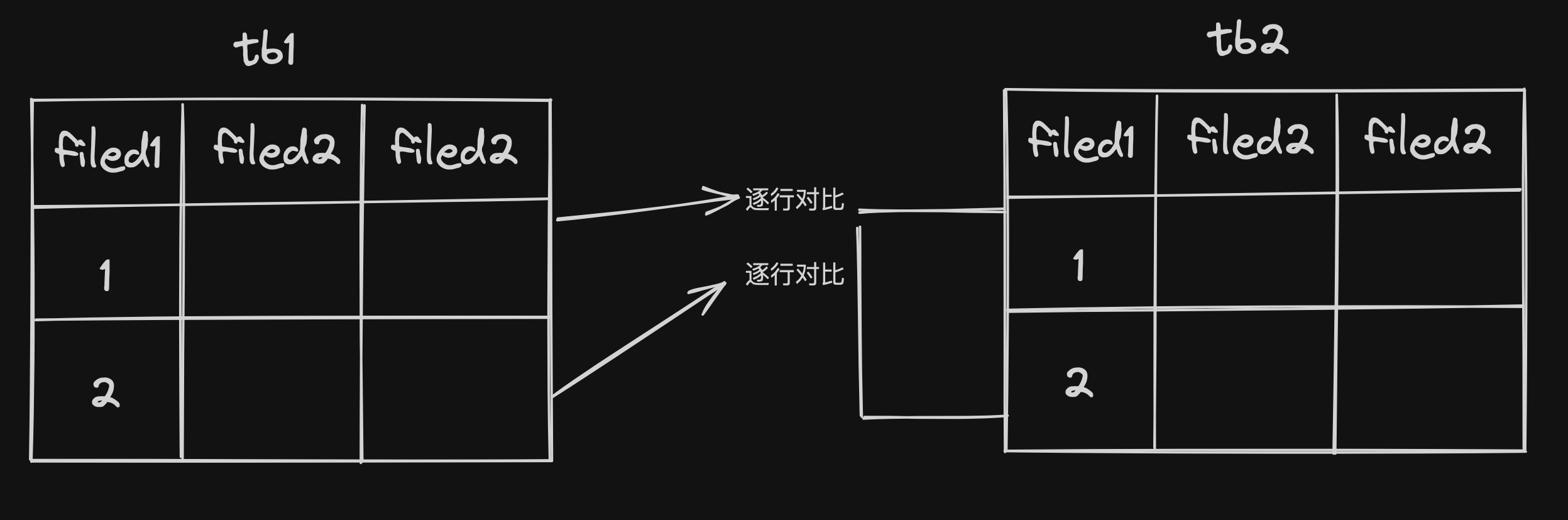
工作过程:
1.外部循环:首先,数据库系统会从驱动表中选择一行。
2.内部循环:然后,对于驱动表中的这一行,数据库系统会在被驱动表中逐行搜索匹配的行。
3.结果组合:如果找到匹配的行,数据库系统就会将这些行与外表中的当前行组合起来,形成查询结果的一部分。
4.循环继续:外部循环继续到下一行,然后内部循环再次执行,直到遍历完外表的所有行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号