第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目作业 |
| 这个作业的目标 | 论文查重功能的实现+PSP表格应用+GitHub代码管理+性能分析工具使用+单元测试&回归测试学习 |
| GitHub地址 |
1.需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:
- 今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
2.前言
2.1 开发环境
-
编程语言:JavaSE-10
-
IDE:Eclipse Java 2018-09(后面测试用的是IDEA 2021)
-
单元测试:JUnit
-
代码性能分析工具:JProfiler
2.2 流程设计
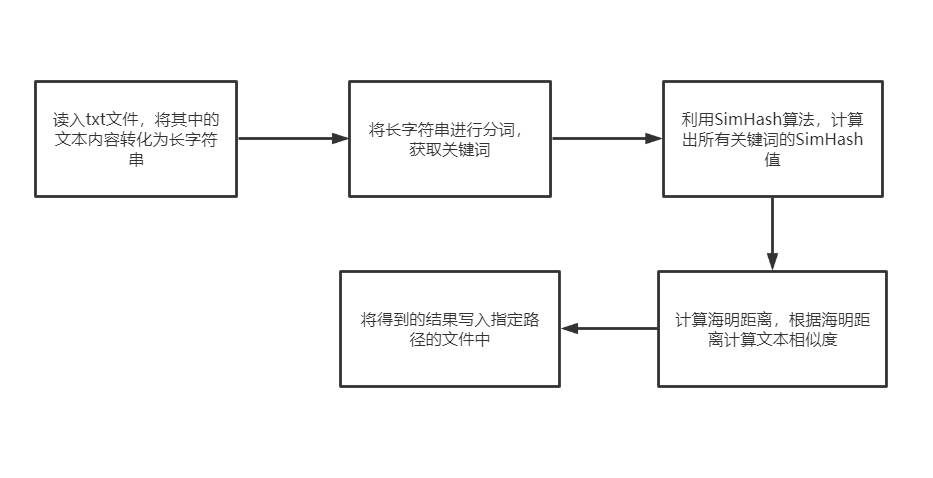
2.3 接口与类
- TxtFileInput:实现txt文件的读取
- SimHash:接口,接口内含核心算法模块
- SimHash_Finish:实现SimHash接口中的方法,最终计算出文本相似度
- Test:对给定的文本进行重复率测试,并将结果写入指定路径的文件中
2.4 包结构
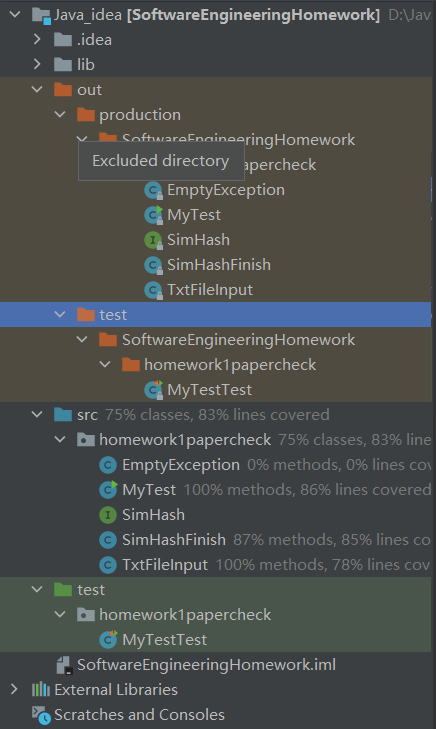
2.4 核心算法
- SimHash + 海明距离
2.4.1 算法简介
- SimHash也即相似Hash,是一类特殊的信息指纹,常用来比较文章的相似度。与传统Hash相比,传统Hash只负责将原始内容尽量随机的映射为一个特征值,并保证相同的内容一定具有相同的特征值,而且如果两个hash值是相等的,则说明原始数据在一定概率下也是相等的。但通过传统hash来判断文章的内容是否相似是非常困难的,原因在于传统hash只唯一标明了其特殊性,并不能作为相似度比较的依据。SimHash最初是由Google使用,其值不但提供了原始值是否相等这一信息,还能通过该值计算出内容的差异程度。
2.4.2 算法原理
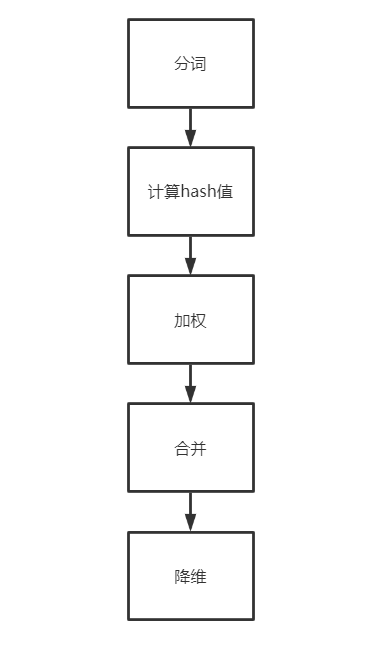
- simhash是由 Charikar 在2002年提出来的,参考 《Similarity estimation techniques from rounding algorithms》。该算法主要分为这几步:
- (1)分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,权重值越大代表重要程度越高。
例子:假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。 - (2)hash,通过hash算法把每个词变成hash值,因为数字计算能提高相似度计算性能。
例子:比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。 - (3)加权,得到hash生成结果后,需要按照分词的权重形成加权数字串。
例子:比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。 - (4)合并,将所有关键字的加权数字串序列值累加,变成只有一个序列串。
例子:比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。 - (5)降维,将合并后的数字串的每一位进行检查,若该位大于等于0,则置为1;否则,置为0,形成最终的simhash签名。
算法参考
3.接口的设计与实现过程
3.1 txt文件读取类
类:TxtFileInput
方法:beString,实现对文件的读取以及将文本内容转化为字符串

3.2 SimHash接口
接口:SimHash
方法:
(1)simHash:核心算法,计算关键词的SimHash值
(2)hashValue:计算每个分词对应的hash值
(3)hammingDistance:获取海明距离
(4)getDistance:计算两个字符串的海明距离
(5)FiDistance:获取SimHash特征值

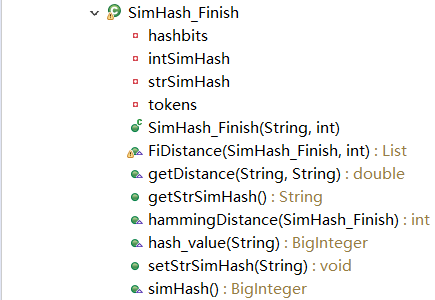
3.3 SimHash接口实现类(关键)
类:SimHash_Finish
方法:
(1)SimHash_Finish:构造方法
(2)fiDistance:获取SimHash特征值,输出为列表
(3)getDistance:输入两个字符串,计算两个字符串的海明距离(double型)并返回
(4)getStrSimHash:获取simhash签名(String型)
(5)hammingDistance:获取海明距离(int型)
(6)hashValue:输入字符串,计算每个分词对应的hash值(BigInteger型)
(7)setStrSimHash:设置simhash签名
(8)simHash:完成分词和特征数组的创建
3.4 测试类
类:Test
方法:
(1)countSimilarity:计算相似度,结果精确到小数点后两位,path1为测试文件路径,path2为结果存放路径
- 相似度计算公式:

(2)getFilename:获取文件名
4.接口部分的性能改进
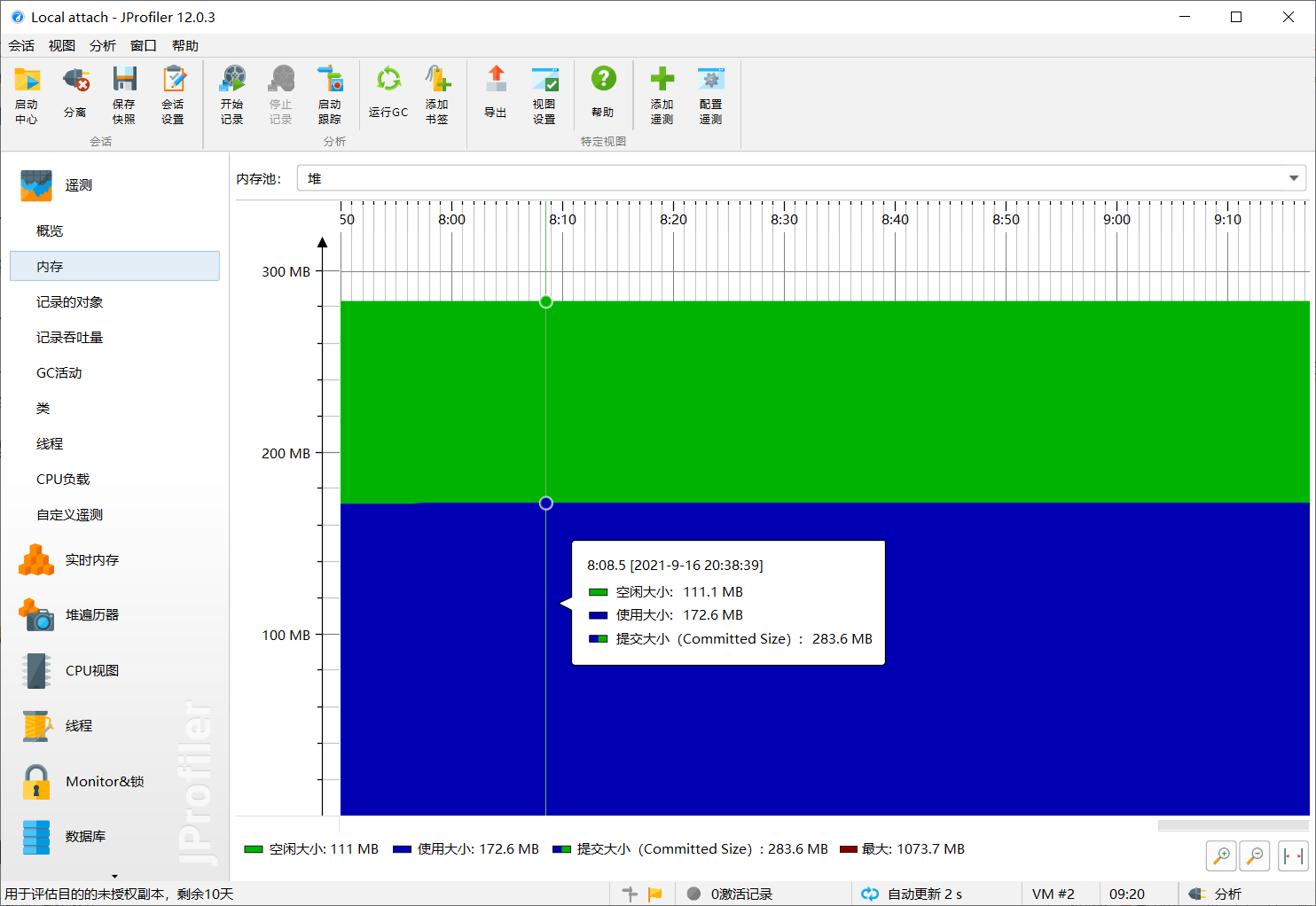
4.1 内存占用情况
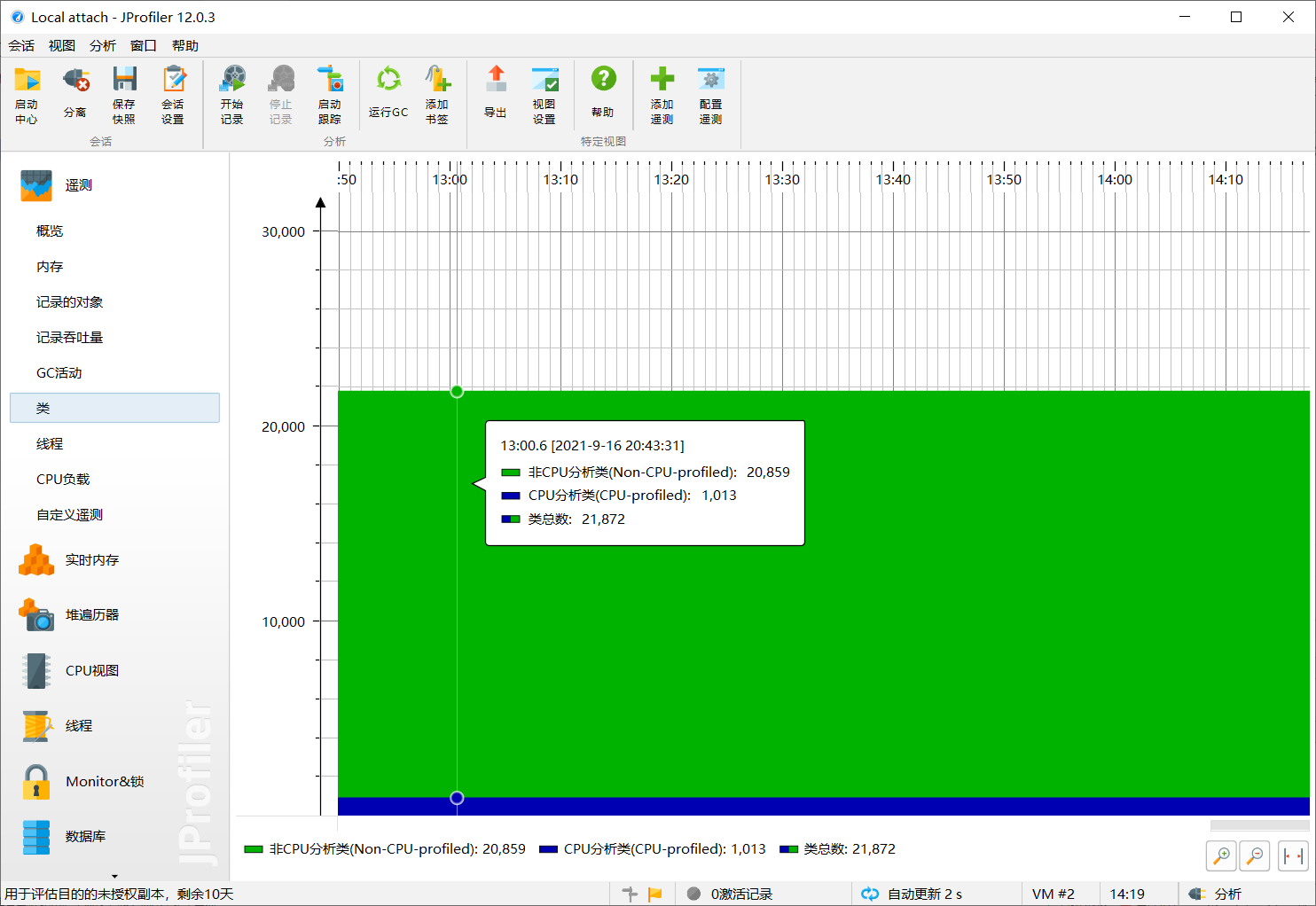
4.2 类的占用情况
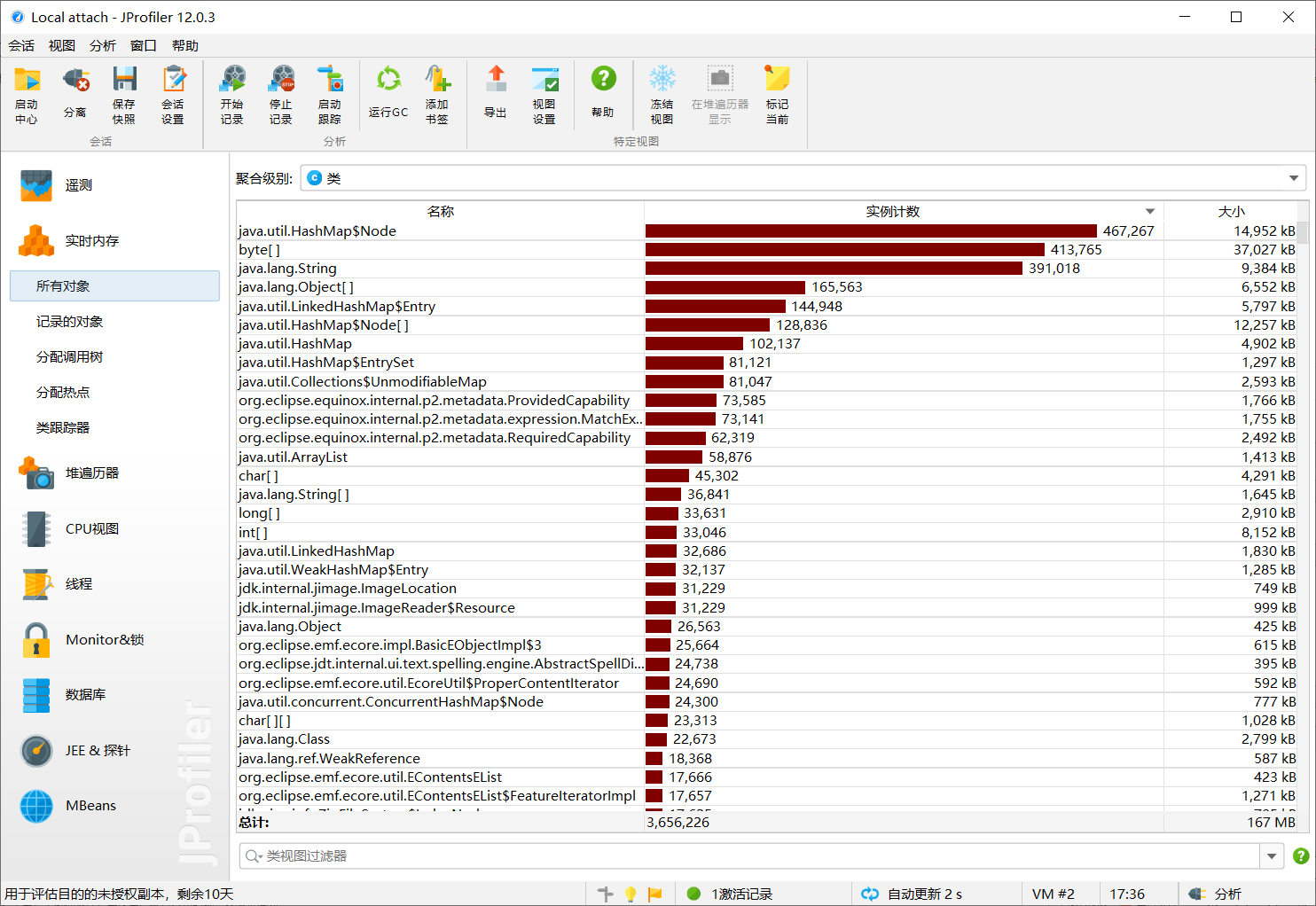
4.3 耗时情况
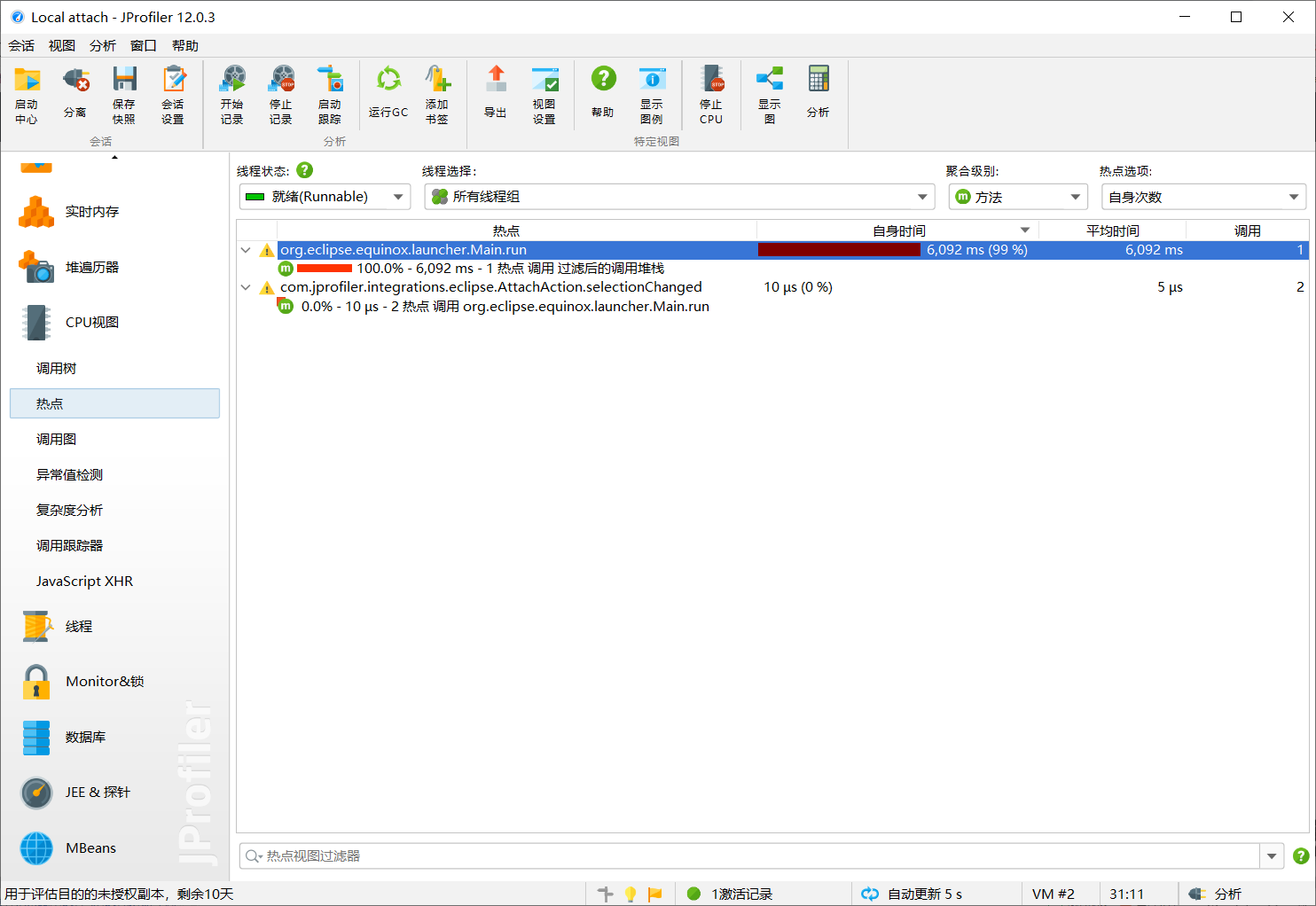
分析:由上图可以看出,simHash函数消耗最大,即处理分词以及计算hash值花了很多时间。性能瓶颈在于该函数,由于本人水平所限,目前无法优化该函数。
4.3 CPU负载
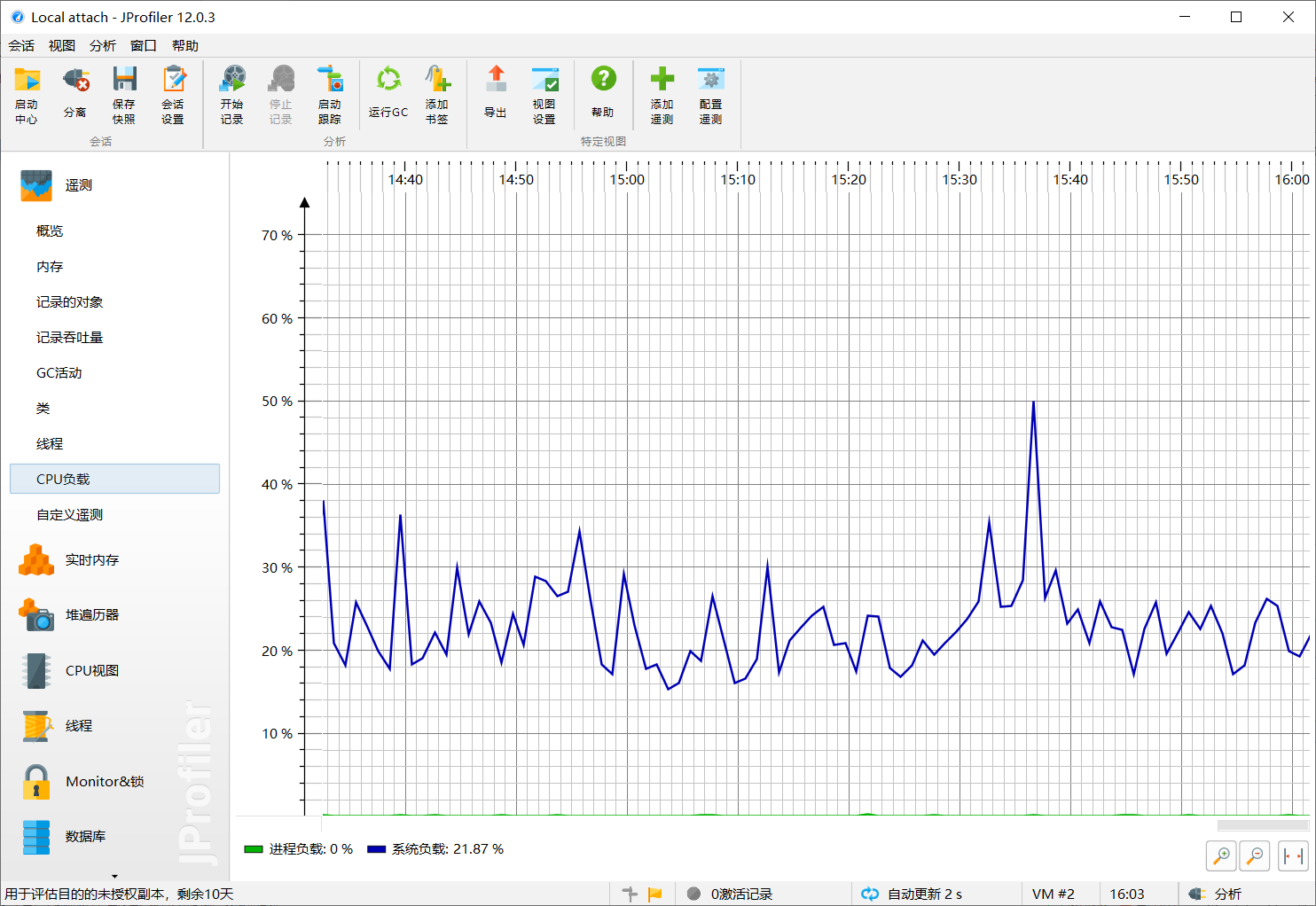
5.计算模块部分单元测试展示
5.1 白盒测试
对原文件的添加、删除、修改、空白、文件不存在进行测试:
5.1.1 测试用例:
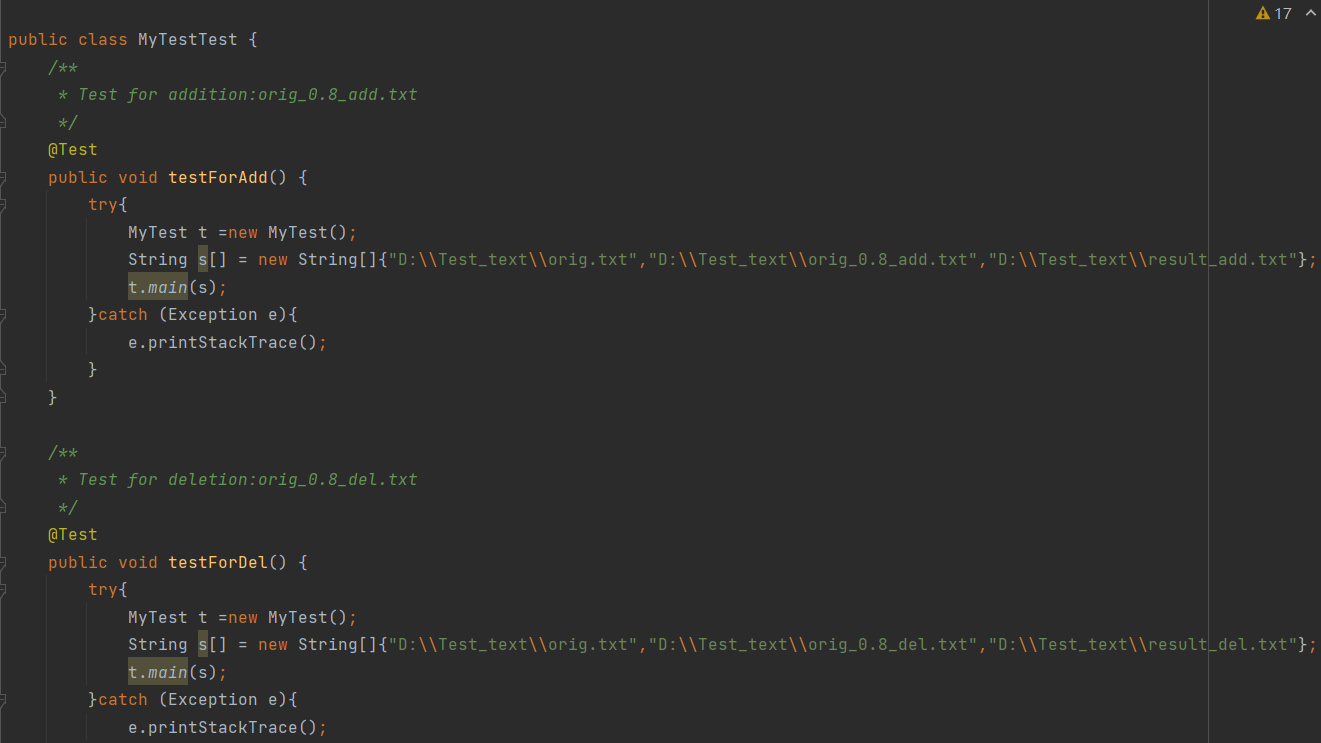
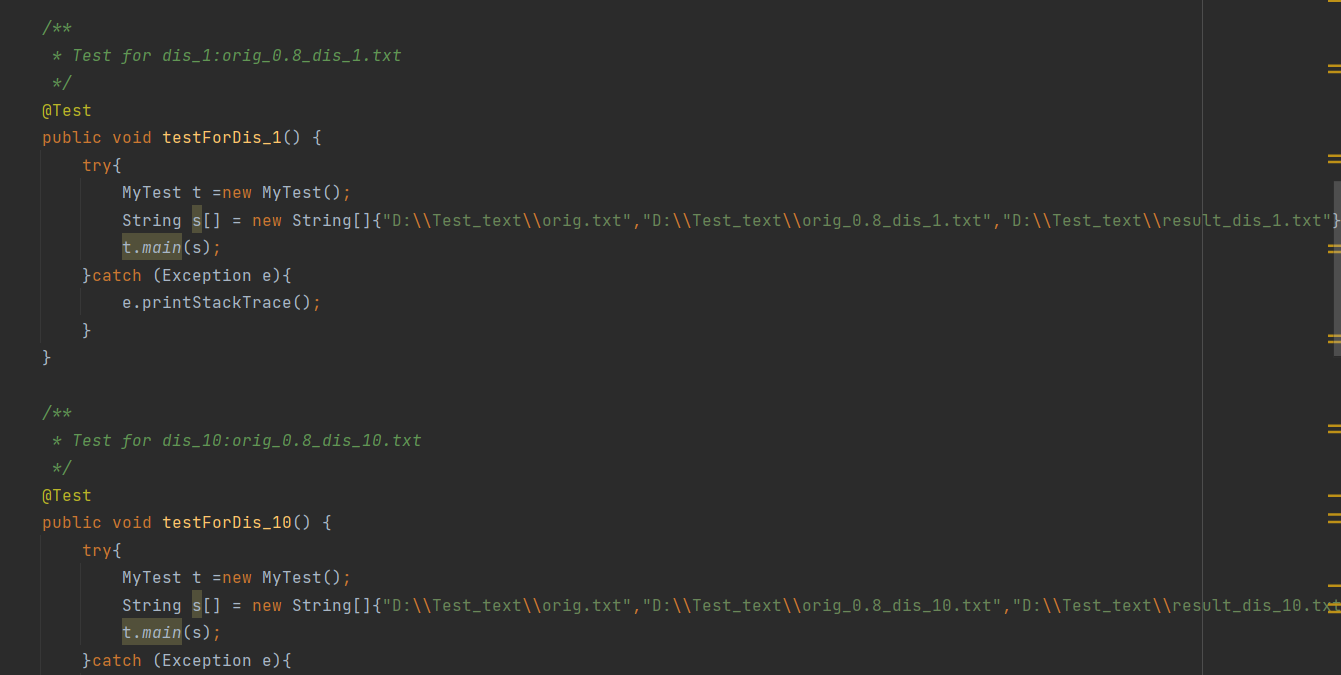
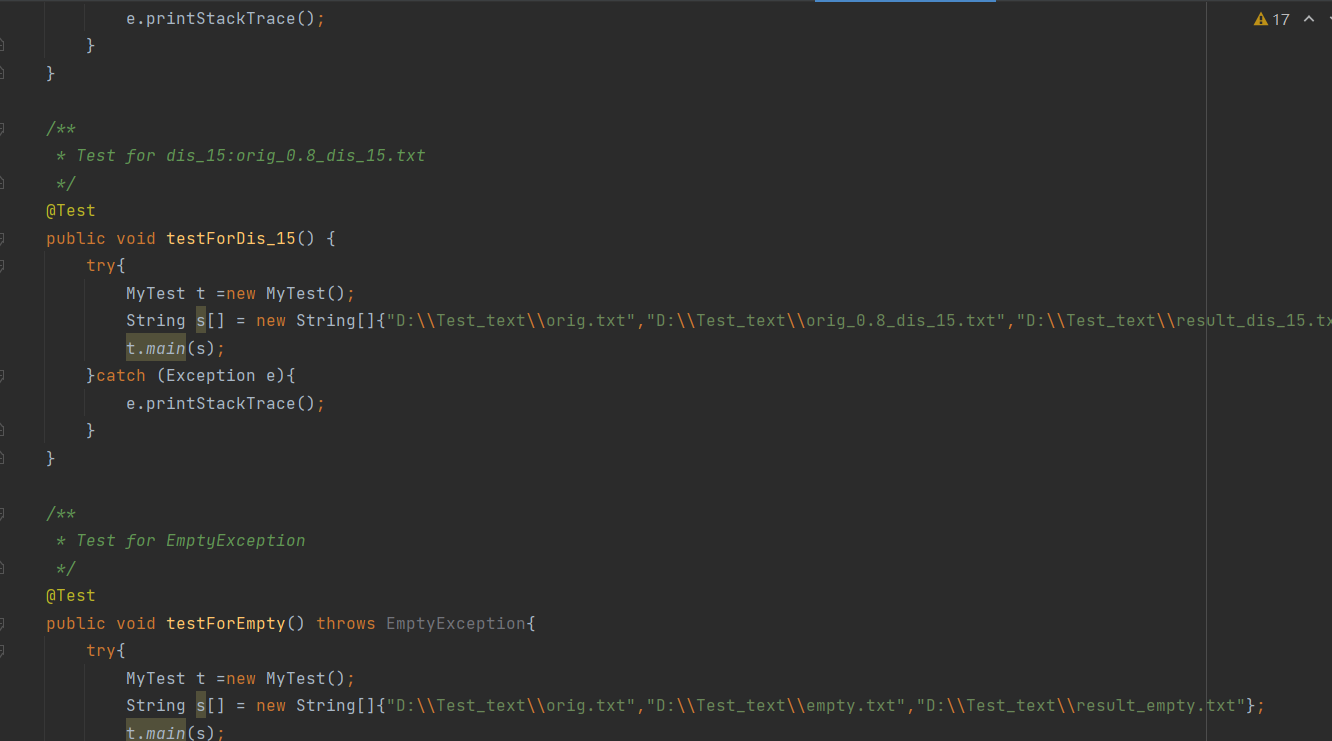
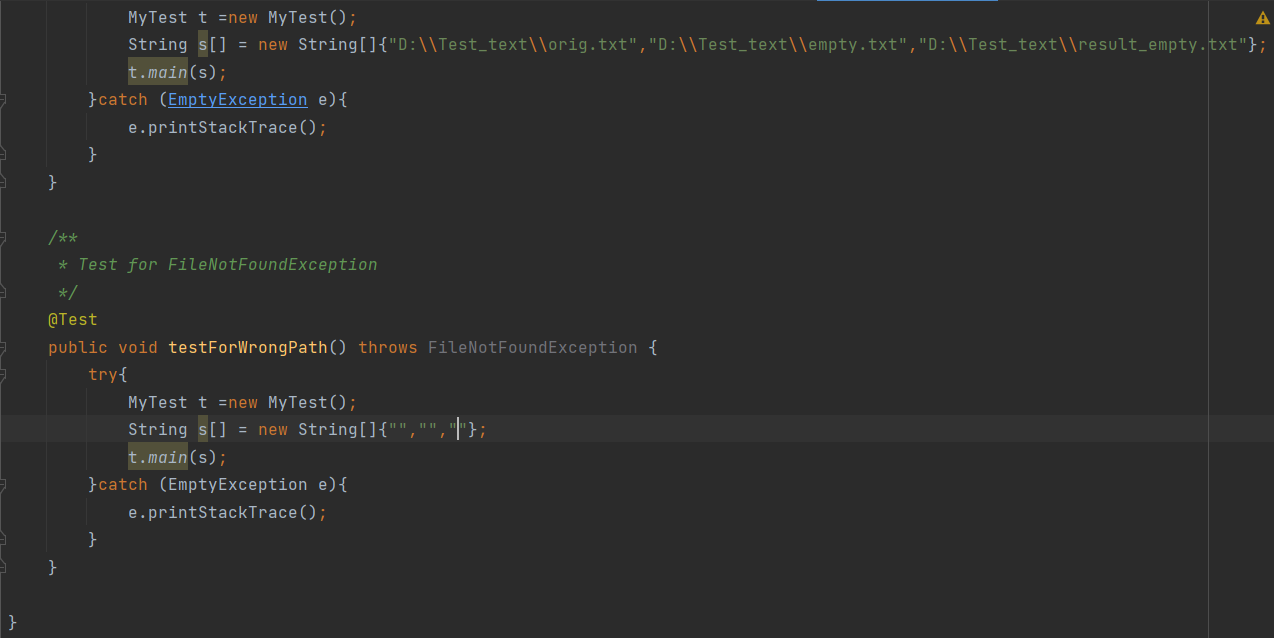
5.1.2 运行结果
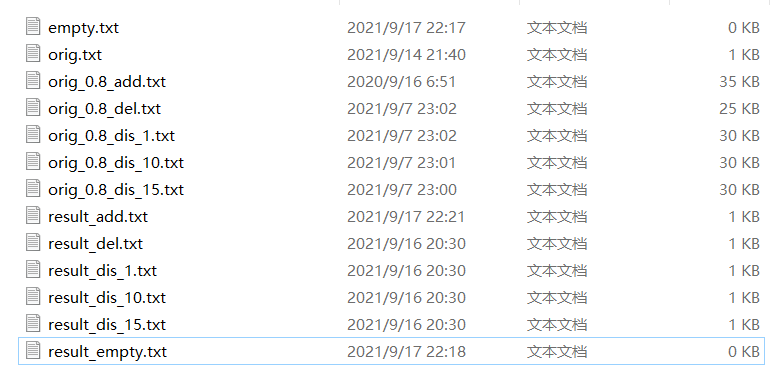





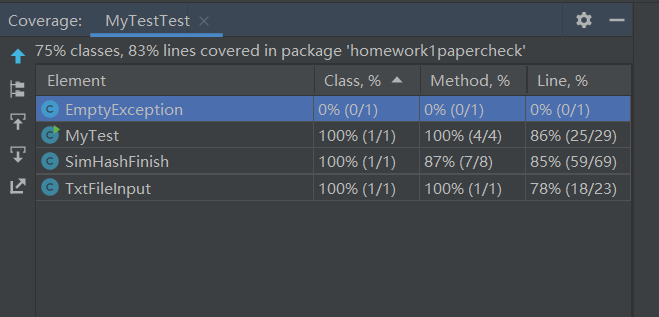
5.1.3 代码覆盖率
6.计算模块部分异常处理说明
(1)FileNotFoundException:对于不存在的文件,在文件读取时出现异常,并提示文件不存在
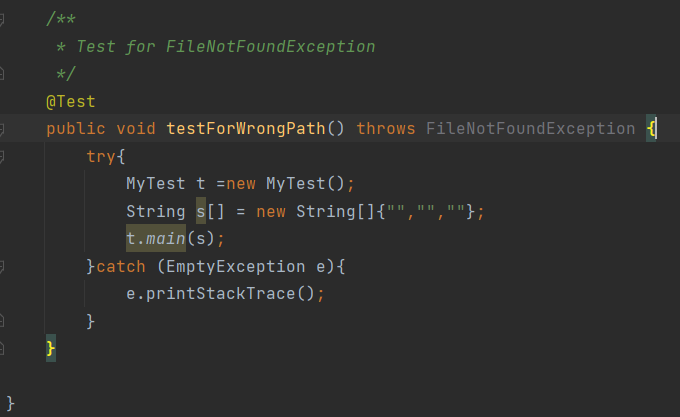
运行结果:

(2)EmptyException:对于内容为空的文件,提示内容为空异常
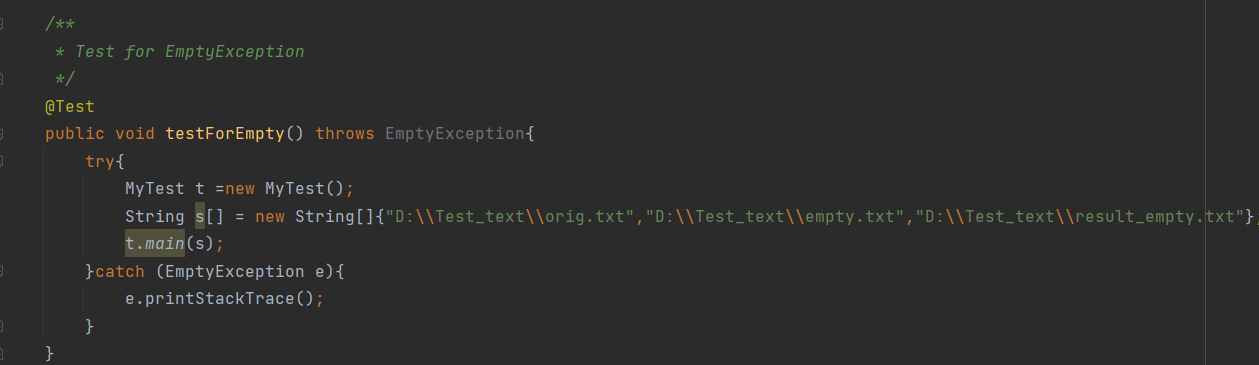
运行结果:

7.总结
1.个人感受:第一次个人作业,独立实现一个小项目,时间主要花在了算法理解与实现、新技术的学习上。总体上体验了软件工程设计的整体流程与方法,希望以后能做得更好更熟练。
2.所学所得:
(1)PSP表格的学习与应用。
(2)如何使用GitHub来进行代码的有效管理。
(3)性能分析工具(JProfiler)、单元测试(JUnit)以及代码覆盖率(Coverage)的学习与使用。
(4)较为完整的软件开发流程学习。
(5)个人独立解决问题的能力提高了。
8.PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 60 |
| Estimate | 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 90 | 120 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 20 | 25 |
| Design Review | 设计复审 | 15 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 22 |
| Design | 具体设计 | 25 | 30 |
| Coding | 具体编码 | 60 | 73 |
| Code Review | 代码复审 | 10 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 40 | 50 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 495 | 675 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号