读Kafka Consumer源码
最近一直在关注阿里的一个开源项目:OpenMessaging
OpenMessaging, which includes the establishment of industry guidelines and messaging, streaming specifications to provide a common framework for finance, e-commerce, IoT and big-data area. The design principles are the cloud-oriented, simplicity, flexibility, and language independent in distributed heterogeneous environments. Conformance to these specifications will make it possible to develop a heterogeneous messaging applications across all major platforms and operating systems.
这是OpenMessaging-Java项目GitHub上的一段介绍,大致是说OpenMessaging项目致力于建立MQ领域的标准。
看了OpenMessaging-Java项目的源码,定义了:
- Message接口
- Producer接口
- Consumer接口
- 消费方式:Pull、Push
- 各种异常
确实是在朝着建立一套MQ的接口标准。
这引发了我的一个思考:MQ目前确实没有一套标准的接口,如果我们尝试从更高的层次看自己的项目,即我们希望它成为行业标准,那么现在项目中接口的定义合适吗?是否够通用、简洁、易用、合理?
带着这样的疑问,最近把Kafka Consumer部分的源码读了一遍,因为:
- Kafka应该是业界最著名的一个开源MQ了(RocketMQ最初也是参考了Kafka去实现的)
- 希望通过读Kafka源码能找到一些定义MQ接口的想法
但是在读完Kafka Consumer部分的源码后稍稍有一些失望,因为它并没有给我代码我想要的,反而在读完后觉得接口设计和源码实现上相对于Kafka的盛名有一些名不副实的感觉。
接口定义
Kafka在消费部分只提供了一个接口,即Consumer接口。
Consumer接口如下:
- Set<TopicPartition> assignment();
- Set<String> subscription();
- void subscribe(Collection<String> topics);
- void subscribe(Collection<String> topics, ConsumerRebalanceListener callback);
- void assign(Collection<TopicPartition> partitions);
- void subscribe(Pattern pattern, ConsumerRebalanceListener callback);
- void subscribe(Pattern pattern);
- void unsubscribe();
- ConsumerRecords<k, v=""> poll(long timeout);
- void commitSync();
- void commitSync(Map<TopicPartition, OffsetAndMetadata> offsets);
- void commitAsync();
- void commitAsync(OffsetCommitCallback callback);
- void commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback);
- void seek(TopicPartition partition, long offset);
- void seekToBeginning(Collection<TopicPartition> partitions);
- void seekToEnd(Collection<TopicPartition> partitions);
- long position(TopicPartition partition);
- OffsetAndMetadata committed(TopicPartition partition);
- Map<MetricName, ? extends Metric> metrics();
- List<PartitionInfo> partitionsFor(String topic);
- Map<String, List> listTopics();
- Set<TopicPartition> paused();
- void pause(Collection<TopicPartition> partitions);
- void resume(Collection<TopicPartition> partitions);
- Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch);
- Map<TopicPartition, Long> beginningOffsets(Collection partitions);
- Map<TopicPartition, Long> endOffsets(Collection partitions);
- ...
(读源码时光看完这部分接口我就已经晕了)
上面的方法大致可以分为四类:
- 订阅相关:subscribe、unsubscribe
- 消费相关:assign、poll、commit
- 元数据相关:搜索、设置、获取offset信息;partition信息
- 生命周期相关:pause、resume、close等
看完这个接口的第一个感觉就是灵活有余易用不足。
Kafka几乎暴露了所有的操作API,这样的好处是足够灵活,但是带来的问题就是易用性下降,哪怕用户只是希望简单的获取消息并处理也需要关心offset的提交和管理以及commit等等。
另外功能上也并没有提供用户更多的选择,比如只提供了poll模式去获取消息,而没有提供类似push的模式。
线程模型部分
看完接口之后,第二步看了Kafka Consumer部分的线程模型,即尝试将Consumer部分的线程模型梳理清楚:Consumer部分有哪些线程,线程间的交互等。
Consumer部分包含以下几个模块:
- Consuming
- Consumer、ConsumerConfig、ConsumerProtocol
- Fetcher
- 分布式协调
- AbstractCoordinator、ConsumerCoordinator
- 分区分配和负载均衡
- Assignor
- ReblanceListener
- 网络组件
- NetClient
- Future
- FutureListener
- 异常
- NoAvailableBrokersException、CommitFailedExceptin、...
- 元数据和数据
- ConsumerRecord、ConsumerRecords
- TopicPartition
- 统计及其他
通过分布式系统组件及分区分配策略,每个Consumer可以拿到自己消费的分区。之后通过Fetcher来执行获取消息的操作,而底层通过网络组件NetworkClient和Broker完成交互。
通过阅读源码和注释发现,Kafka Consumer并没有去管理线程,而是所有的操作都在用户线程中完成。
所以线程模型就非常简单,Consumer非线程安全,同时只能有一个线程执行操作,且所有的操作都在用户的线程中执行。
Consumer通过一个AtomicLong的CAS操作来保证只能有一个线程操作(多线程的情况下会报出异常)
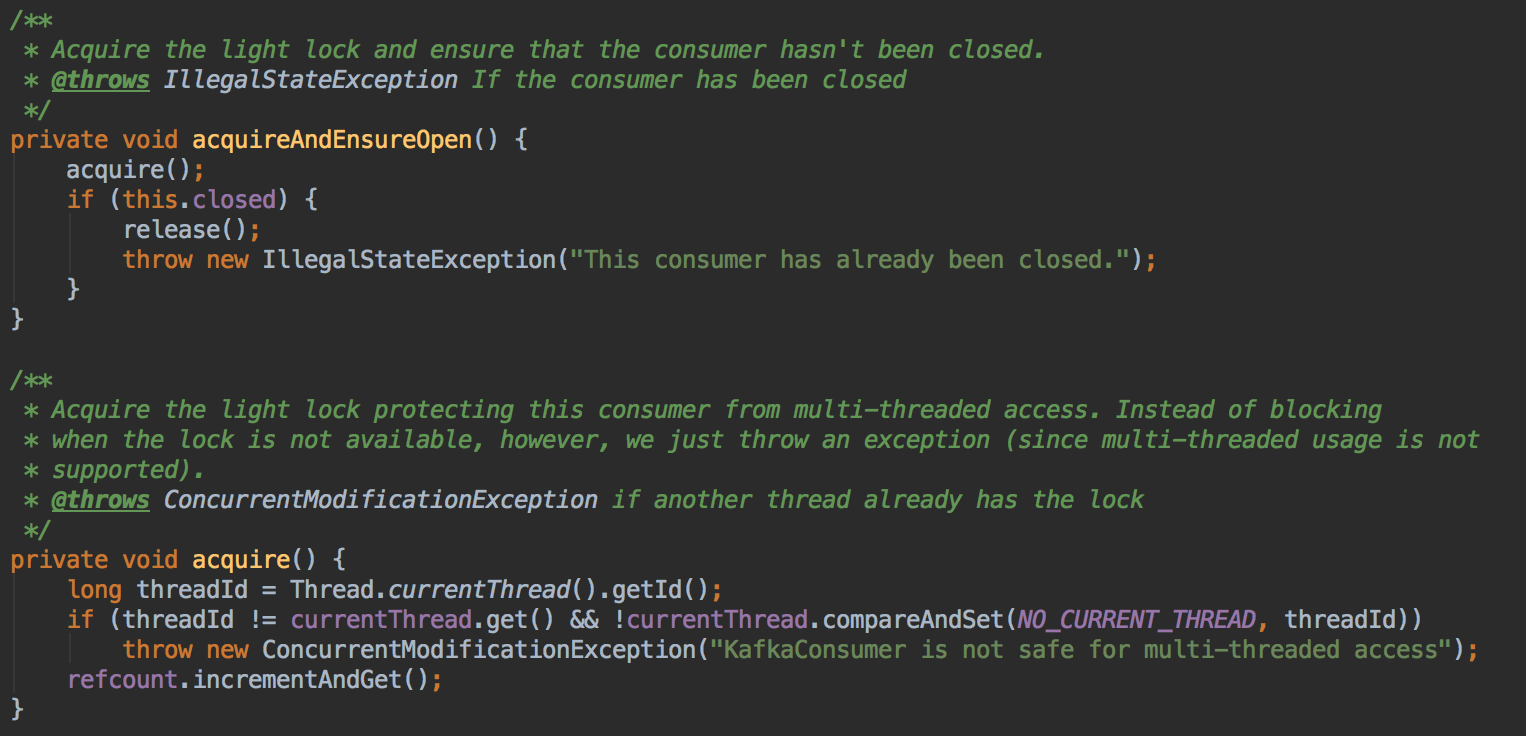
部分代码实现解读
ConsumerRecords<k, v=""> poll(long timeout)
poll应该是Consumer的核心接口了,因为到这里才真正执行了和获取消息相关的逻辑。
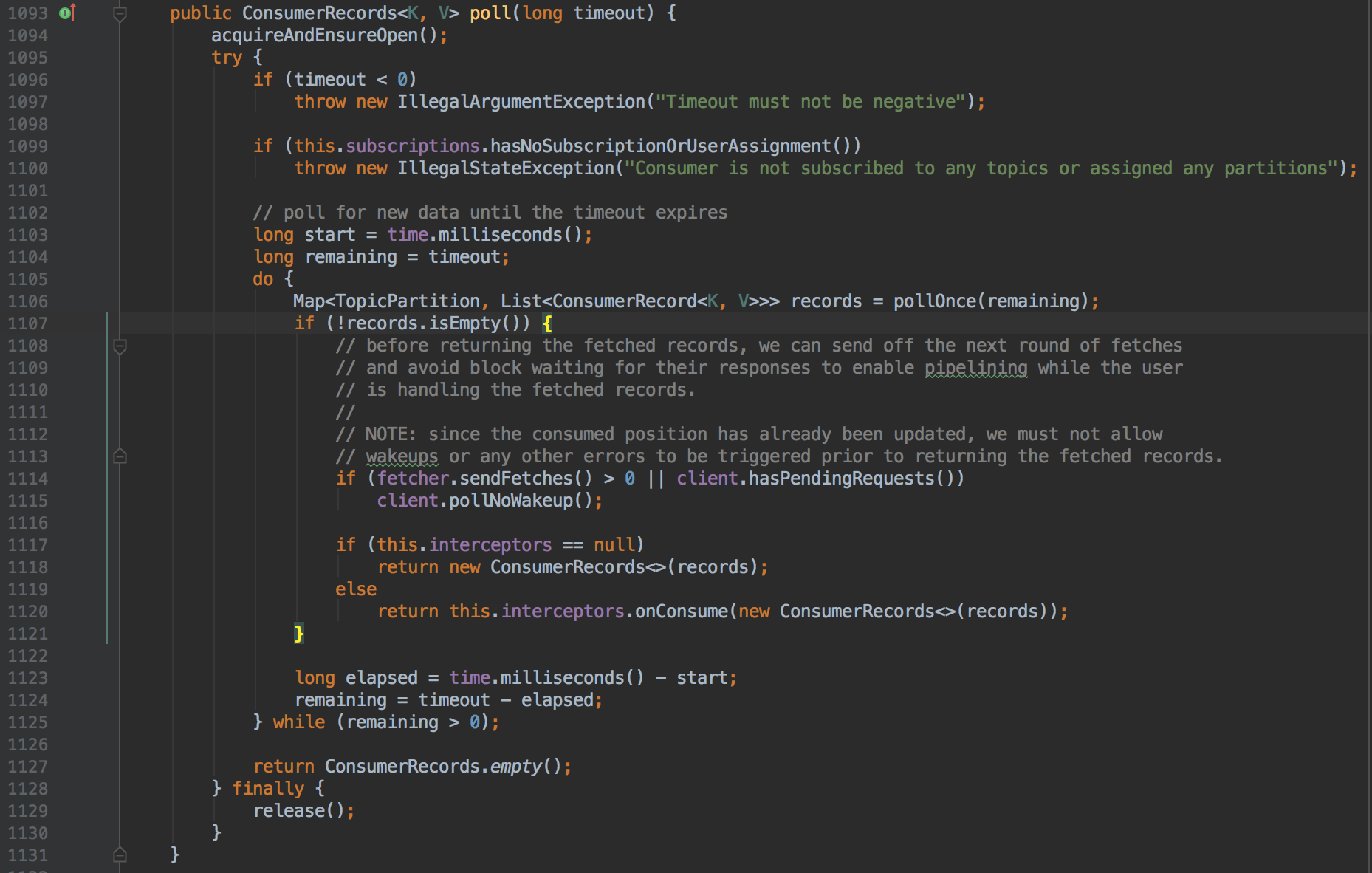
首先是校验逻辑,在poll之前如果没有进行topic的订阅或分区的分配,poll操作将抛出异常。
接着是poll的核心逻辑:
- 在一个循环体中执行获取数据的逻辑,跳出循环的条件是超时或者获取到数据
从代码中可以看出pollOnce应该是真正的执行一次获取消息的操作。而代码中注释的部分是poll的核心:
- fetcher#sendFetches方法给有需要的Server节点发送获取消息的请求
- 这么做的目的是在用户下一次进行poll操作之前先将获取消息的请求发送出去
- 这样网络操作和就可以和用户处理消息的逻辑并行,降低延迟
- client#hasPendingRequests判断是否还有未从客户端发送出去的请求
- client#pollNoWakeup执行网络真正的网络IO操作
从这段注释和代码中可以看出,poll时如果拿到数据了,会将剩余的请求发送出去来实现pipelining的目的。
所以对应的pollOnce内的逻辑必然有从缓存中(即上一次poll请求中获取的数据)获取数据的操作。

pollOnce对目标分区执行一路poll请求,大致流程如下:
- coordinator#poll确保Consumer在Coordinator的管理之中
- ensure coordinator
- ensure active group(将Consumer加入到group中)
- 发送heartbeat
- 更新positions
- 从fetcher中获取消息,如果已经拿到消息则返回结果,调用结束
- 对分区执行poll请求
- 阻塞等待至少一个fetch操作完成
- 判断是否操作期间元数据进行了变更,如果变更了,丢弃获取的数据
- 返回获取结果
读上面的代码,第一个感觉就是可读性比较差,比较难懂。
比如pollOnce中,fetcher#sendFetches从字面上看会理解成发送fetch请求:
- 如果是同步的,那么应该获取它的结果
- 如果是异步的,应该通过Future获取最终的结果
而实际上fetcher#sendFetches只是去构建了请求,并且将请求保存在NetworkClient中(NetworkClient会有数据结构保存每个Node对应的请求:类似这样的数据结构Map<Node,Queue<Request>>)。
在client#poll中才将通过fetcher构造的请求真正的写出去,并且阻塞的等待fetch的结果,从实现上感觉将代码变的复杂了。
NetworkClient提供了异步的网络操作,且是非线程安全的。
NetworkClient只有poll会真正的去执行IO操作,而其中的send只是将send数据保存在channel上,直到执行poll时将它写到网络中。
总结
在读完Kafka Consumer部分的源码后,稍稍有些失望:
- 只提供了poll模式,没有提供给用户更多的选择,比如push模式
- openmessaging在这块分别提供了PullConsumer和PushConsumer接口
- 而我们自己的项目则是提供了ListenConsumer、StreamConsumer等(Listen模式用户只提供回调接口,我们管理线程,而Stream模式将消费线程交给用户自己管理),继续还会提供基础的PullConsumer等
- Consumer接口的灵活性由于,易用性不足
- 暴露了太多的接口,对于一个指向简单获取消息处理的使用方来说心智负担太重
- 代码的实现上复杂化了,比如提供了Fetcher和NetworkClient的实现非常复杂
总体上Consumer的代码有一些乱,比如下面是Kafka源码中Consumer部分的包组织和我自己读源码使对它的整理:
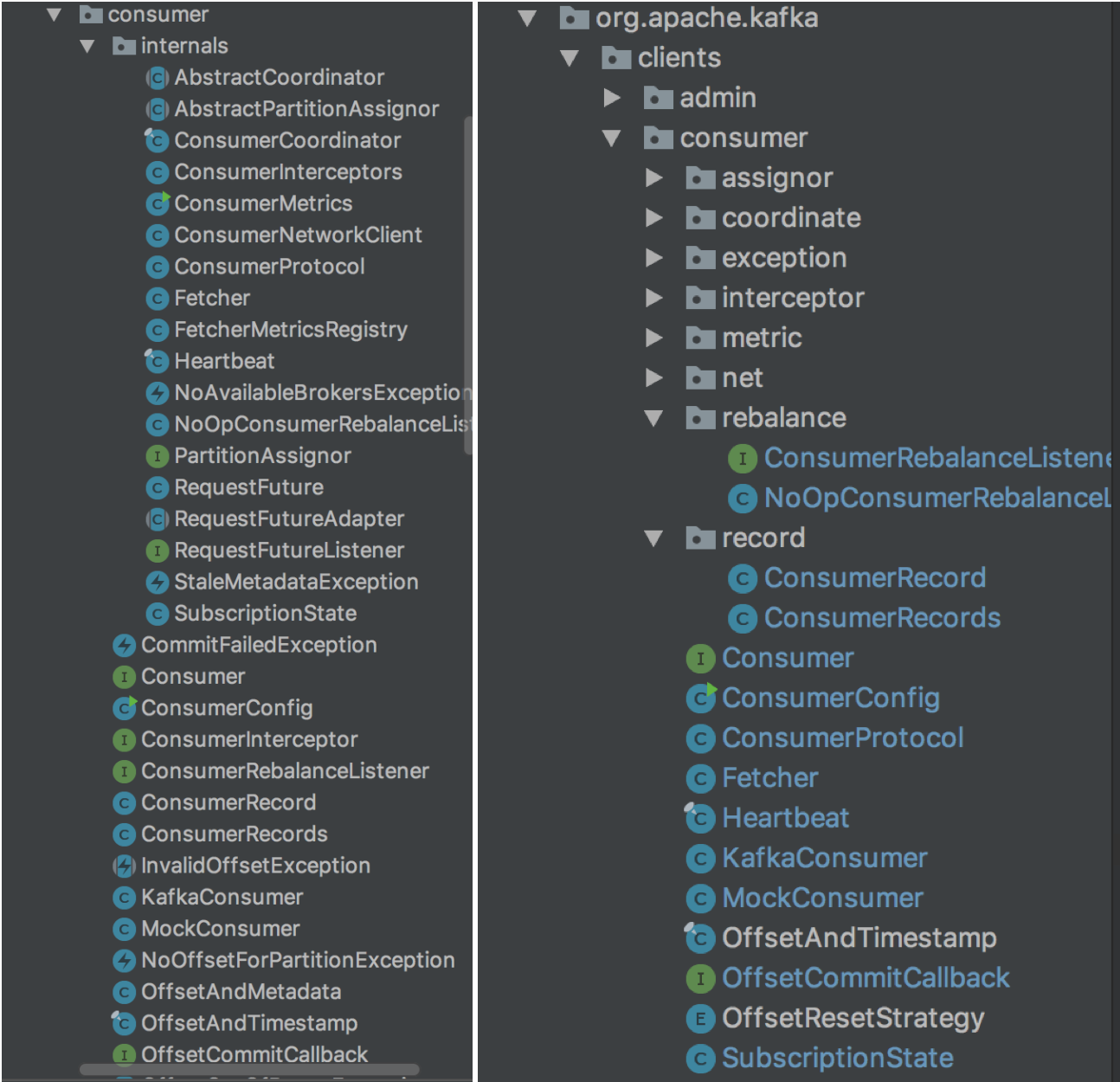
右边是Kafka源码Consumer部分的包结构,所有的类分了两块,内部的在internals中。右边是自己读源码时根据各个模块对Consumer的类进行划分。
私以为将各个类按照不同的模块分开会更加清晰,读起来也会更加舒服。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号