

Pytorch quantize 官方量化_VGG16 + MobileNetV2
Pytorch quantize 官方量化-VGG16 + MobileNetV2
Created by Hanyz@2021/1/27
code:https://github.com/Forggtensky/Quantize_Pytorch_Vgg16AndMobileNet
第一部分,对pytorch的3种量化方式进行梳理,参考文献:https://pytorch.org/docs/stable/quantization.html
第二部分,我会附上采用后两张量化方式(Static and QAT)对VGG-16以及Mobilenet-V2网络的量化压缩。
Part1
Pytorch提供了三种量化模型的方法:
- dynamic quantization 动态量化 (weights quantized with activations read/stored in floating point and quantized for compute.)(使用浮点读取/存储的激活量化权重,并量化以进行计算。)
- static quantization 静态量化 (weights quantized, activations quantized, calibration required post training)(权重量化、激活量化、在得到训练后的模型参数后,需要校准)
- quantization aware training 量化感知训练 (weights quantized, activations quantized, quantization numerics modeled during training)(权重量化、激活量化、训练过程中建模的量化)
1、动态量化
这是应用量化形式的最简单方法,其中权重提前量化,但激活在推理过程中动态量化。
This is used for situations where the model execution time is dominated by loading weights from memory rather than computing the matrix multiplications. This is true for for LSTM and Transformer type models with small batch size.
可以看到,这里适用的场景,是计算瓶颈在加载权重的部分,而并非矩阵乘法的计算。
!!!经过测试,Pytorch动态量化,只能量化全连接层和RNN的结构,无法量化CNN。
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# dynamically quantized model
# linear and conv weights are in int8
previous_layer_fp32 -- linear_int8_w_fp32_inp -- activation_fp32 -- next_layer_fp32
/
linear_weight_int8
API example from official:
import torch
# define a floating point model
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
self.fc = torch.nn.Linear(4, 4)
def forward(self, x):
x = self.fc(x)
return x
# create a model instance
model_fp32 = M()
# create a quantized model instance
model_int8 = torch.quantization.quantize_dynamic(
model_fp32, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8) # the target dtype for quantized weights
# run the model
input_fp32 = torch.randn(4, 4, 4, 4)
res = model_int8(input_fp32)
More Information:
The key idea with dynamic quantization as described here is that we are going to determine the scale factor for activations dynamically based on the data range observed at runtime. This ensures that the scale factor is “tuned” so that as much signal as possible about each observed dataset is preserved.
Arithmetic in the quantized model is done using vectorized INT8 instructions. Accumulation is typically done with INT16 or INT32 to avoid overflow. This higher precision value is scaled back to INT8 if the next layer is quantized or converted to FP32 for output.
计数函数补充:(仅可在jupyter notebook环境下使用)
%time 可以测量一行代码执行的时间
%timeit 可以测量一行代码多次执行的时间
2、静态量化
Static quantization quantizes the weights and activations of the model. It fuses activations into preceding layers where possible. It requires calibration with a representative dataset to determine optimal quantization parameters for activations.
Post Training Quantization is typically used when both memory bandwidth and compute savings are important with CNNs being a typical use case. Static quantization is also known as Post Training Quantization or PTQ.
由上述介绍,静态量化适用权重的加载和相关卷积计算,能用于CNN。
结构:可以看到,包括激活与权重均量化为了8bit的int型
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# statically quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
API Example:
import torch
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
# manually specify where tensors will be converted from floating
# point to quantized in the quantized model
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
# manually specify where tensors will be converted from quantized
# to floating point in the quantized model
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval mode for static quantization logic to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'fbgemm' for server inference and
# 'qnnpack' for mobile inference. Other quantization configurations such
# as selecting symmetric or assymetric quantization and MinMax or L2Norm
# calibration techniques can be specified here.
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
# Fuse the activations to preceding layers, where applicable.
# This needs to be done manually depending on the model architecture.
# Common fusions include `conv + relu` and `conv + batchnorm + relu`
model_fp32_fused = torch.quantization.fuse_modules(model_fp32, [['conv', 'relu']])
# Prepare the model for static quantization. This inserts observers in
# the model that will observe activation tensors during calibration.
model_fp32_prepared = torch.quantization.prepare(model_fp32_fused)
# calibrate the prepared model to determine quantization parameters for activations
# in a real world setting, the calibration would be done with a representative dataset
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, and replaces key operators with quantized
# implementations.
model_int8 = torch.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
打印的model结构:
M(
(quant): QuantStub()
(conv): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
(dequant): DeQuantStub()
)
经过融合后的model_int结构:可以看到,conv和relu在量化后合并在了一起
<bound method Module.named_children of M(
(quant): Quantize(scale=tensor([0.0418]), zero_point=tensor([53]), dtype=torch.quint8)
(conv): QuantizedConvReLU2d(1, 1, kernel_size=(1, 1), stride=(1, 1), scale=0.007825895212590694, zero_point=0)
(relu): Identity()
(dequant): DeQuantize()
)>
处理时间对比(data:torch.randn(128, 3, 416, 416)):
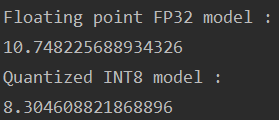
在CPU上运行,提升的不是很明显。
2.1 静态量化详细方案-MobilenetV2
该部分量化必须在CPU上实现,且在量化前具有校准的环节。
1、模型中的结构改动
- Replacing addition with
nn.quantized.FloatFunctional - Insert
QuantStubandDeQuantStubat the beginning and end of the network. - Replace ReLU6 with ReLU
MergeBN的原理:为了在前向推理时减少bn层带来的开销,在模型训练完毕后,可以将BN与卷积层直接融合(即将BN与CONV权重进行merge)
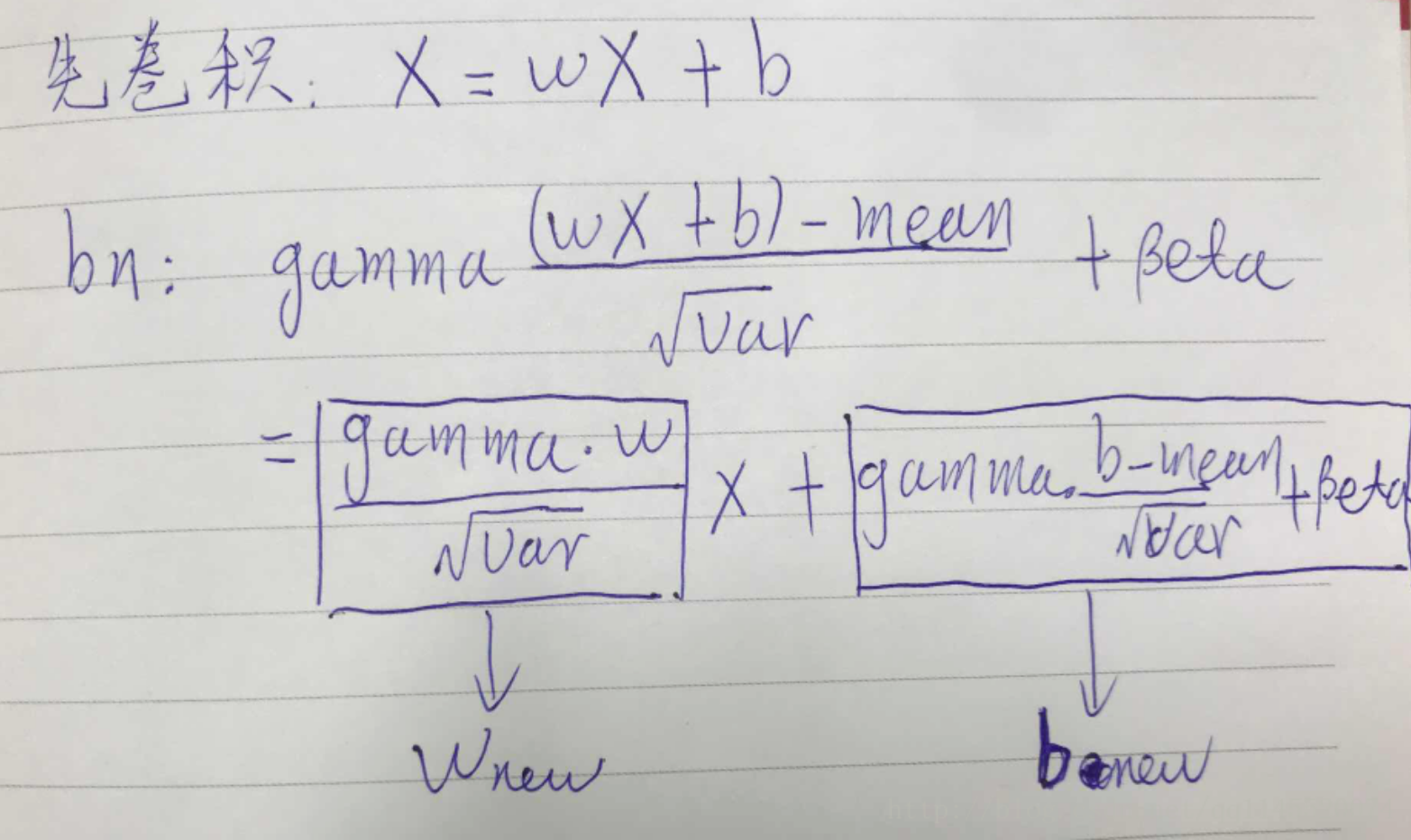
相关代码:
在Mobilener网络结构中:
# Fuse Conv+BN and Conv+BN+Relu modules prior to quantization
def fuse_model(self):
for m in self.modules():
if type(m) == ConvBNReLU:
torch.quantization.fuse_modules(m, ['0', '1', '2'], inplace=True)
if type(m) == InvertedResidual:
for idx in range(len(m.conv)):
if type(m.conv[idx]) == nn.Conv2d:
torch.quantization.fuse_modules(m.conv, [str(idx), str(idx + 1)], inplace=True)
在外面调用网络结构:
def load_model(model_file):
model = MobileNetV2()
state_dict = torch.load(model_file)
model.load_state_dict(state_dict)
model.to('cpu')
return model
float_model = load_model(saved_model_dir + float_model_file).to('cpu')
print('\n Inverted Residual Block: Before fusion \n\n', float_model.features[1].conv)
float_model.eval()
# Fuses modules
float_model.fuse_model()
print('\n Inverted Residual Block: After fusion\n\n',float_model.features[1].conv)
打印结果:
Inverted Residual Block: Before fusion
Sequential(
(0): ConvBNReLU(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
Inverted Residual Block: After fusion
Sequential(
(0): ConvBNReLU(
(0): ConvReLU2d(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(1): ReLU()
)
(1): Identity()
(2): Identity()
)
(1): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1))
(2): Identity()
)
可以看到:原本的conv+bn+relu融合为了ConvReLU2d( Conv2d + ReLU ),原本的conv+bn融合为了Conv2d
2、具体量化部分
Post-training static quantization involves not just converting the weights from float to int, as in dynamic quantization, but also performing the additional step of first feeding batches of data through the network and computing the resulting distributions of the different activations (specifically, this is done by inserting observer modules at different points that record this data). These distributions are then used to determine how the specifically the different activations should be quantized at inference time (a simple technique would be to simply divide the entire range of activations into 256 levels, but we support more sophisticated methods as well). Importantly, this additional step allows us to pass quantized values between operations instead of converting these values to floats - and then back to ints - between every operation, resulting in a significant speed-up.
num_calibration_batches = 10
myModel = load_model(saved_model_dir + float_model_file).to('cpu')
myModel.eval()
# Fuse Conv, bn and relu
myModel.fuse_model()
# Specify quantization configuration
# Start with simple min/max range estimation and per-tensor quantization of weights
myModel.qconfig = torch.quantization.default_qconfig
print(myModel.qconfig)
torch.quantization.prepare(myModel, inplace=True)
# Calibrate first
print('Post Training Quantization Prepare: Inserting Observers')
print('\n Inverted Residual Block:After observer insertion \n\n', myModel.features[1].conv)
# Calibrate with the training set
evaluate(myModel, criterion, data_loader, neval_batches=num_calibration_batches)
print('Post Training Quantization: Calibration done')
'''===================================================================
Note: before the convert, the model in evaluate will change the quantize paras
===================================================================
'''
# Convert to quantized model
torch.quantization.convert(myModel, inplace=True)
print('Post Training Quantization: Convert done')
print('\n Inverted Residual Block: After fusion and quantization, note fused modules: \n\n',myModel.features[1].conv)
print("Size of model after quantization")
print_size_of_model(myModel)
top1, top5 = evaluate(myModel, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
打印结果:
QConfig(activation=functools.partial(<class 'torch.quantization.observer.MinMaxObserver'>, reduce_range=True), weight=functools.partial(<class 'torch.quantization.observer.MinMaxObserver'>, dtype=torch.qint8, qscheme=torch.per_tensor_symmetric))
Post Training Quantization Prepare: Inserting Observers
Size of baseline model:
Size (MB): 13.999657
..........Evaluation accuracy on 300 images, 77.67
Size of model after quantization:
Size (MB): 3.631847
..........Evaluation accuracy on 300 images, 66.67
For this quantized model, we see a significantly lower accuracy of just ~66% on these same 300 images. Nevertheless, we did reduce the size of our model down to just under 3.6 MB, almost a 4x decrease.
3、继续优化量化方案
In addition, we can significantly improve on the accuracy simply by using a different quantization configuration. We repeat the same exercise with the recommended configuration for quantizing for x86 architectures. This configuration does the following:
- Quantizes weights on a per-channel basis
- Uses a histogram observer that collects a histogram of activations and then picks quantization parameters in an optimal manner.
由原来的逐tensor改为逐channel的量化:
per_channel_quantized_model = load_model(saved_model_dir + float_model_file)
per_channel_quantized_model.eval()
per_channel_quantized_model.fuse_model()
# 确定量化的设置
per_channel_quantized_model.qconfig = torch.quantization.get_default_qconfig('fbgemm') # 区别的重点就在这一行
print(per_channel_quantized_model.qconfig)
torch.quantization.prepare(per_channel_quantized_model, inplace=True)
# 这是在进行校准,决定采用的量化参数
evaluate(per_channel_quantized_model,criterion, data_loader, num_calibration_batches)
torch.quantization.convert(per_channel_quantized_model, inplace=True)
# 测试量化的准确率
top1, top5 = evaluate(per_channel_quantized_model, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(per_channel_quantized_model), saved_model_dir + scripted_quantized_model_file) # 保存量化后的模型
3 感知训练量化(QAT)
Quantization-aware training (QAT) is the quantization method that typically results in the highest accuracy. With QAT, all weights and activations are “fake quantized” during both the forward and backward passes of training: that is, float values are rounded to mimic int8 values, but all computations are still done with floating point numbers. Thus, all the weight adjustments during training are made while “aware” of the fact that the model will ultimately be quantized; after quantizing, therefore, this method will usually yield higher accuracy than either dynamic quantization or post-training static quantization.
所有的权值和激活在向前和向后的训练过程中都是“假量化”的
- We can use the same model as before: there is no additional preparation needed for quantization-aware training.
- We need to use a
qconfigspecifying what kind of fake-quantization is to be inserted after weights and activations, instead of specifying observers
过程示意:也就是训练过程中仍然是fp32型
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# model with fake_quants for modeling quantization numerics during training
previous_layer_fp32 -- fq -- linear_fp32 -- activation_fp32 -- fq -- next_layer_fp32
/
linear_weight_fp32 -- fq
# quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
API Example:
import torch
# define a floating point model where some layers could benefit from QAT
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.bn = torch.nn.BatchNorm2d(1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to train mode for QAT logic to work
model_fp32.train()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'fbgemm' for server inference and
# 'qnnpack' for mobile inference. Other quantization configurations such
# as selecting symmetric or assymetric quantization and MinMax or L2Norm
# calibration techniques can be specified here.
model_fp32.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
# fuse the activations to preceding layers, where applicable
# this needs to be done manually depending on the model architecture
model_fp32_fused = torch.quantization.fuse_modules(model_fp32,
[['conv', 'bn', 'relu']])
# Prepare the model for QAT. This inserts observers and fake_quants in
# the model that will observe weight and activation tensors during calibration.
model_fp32_prepared = torch.quantization.prepare_qat(model_fp32_fused)
# run the training loop (not shown)
training_loop(model_fp32_prepared)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, fuses modules where appropriate,
# and replaces key operators with quantized implementations.
model_fp32_prepared.eval()
model_int8 = torch.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
需要注意的是,fuse_modules在网络内和网络外有一些差异
在函数内,一般是针对封装的模块,采用遍历:
def fuse_model(self):
for m in self.modules():
if type(m) == ConvBNReLU:
torch.quantization.fuse_modules(m, ['0', '1', '2'], inplace=True)
fuse_modules函数内是数字序号的方式,最后在外部调用net.fuse_mode().
在函数外,就采用之前的方法,函数内传入模型,用[[]]的双重括号方式:
model_fp32_fused = torch.quantization.fuse_modules(model_fp32,
[['conv', 'bn', 'relu']])
3.1 感知量化训练详细示例-MobilenetV2:
Training a quantized model with high accuracy requires accurate modeling of numerics at inference. For quantization aware training, therefore, we modify the training loop by:
- Switch batch norm to use running mean and variance towards the end of training to better match inference numerics.
- We also freeze the quantizer parameters (scale and zero-point) and fine tune the weights.
- 优化1:训练一定epoch后,冻结batch norm
- 优化2:训练一定epoch后,冻结量化参数,来微调权重
相关代码:
qat_model = load_model(saved_model_dir + float_model_file)
qat_model.fuse_model()
qat_model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
torch.quantization.prepare_qat(qat_model, inplace=True)
print('Inverted Residual Block: After preparation for QAT, note fake-quantization modules \n',qat_model.features[1].conv)
打印结果:
Inverted Residual Block: After preparation for QAT, note fake-quantization modules
Sequential(
(0): ConvBNReLU(
(0): ConvBnReLU2d(
32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=torch.qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=inf, max_val=-inf)
)
)
(1): Identity()
(2): Identity()
)
(1): ConvBn2d(
32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=torch.qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=inf, max_val=-inf)
)
)
(2): Identity()
)
训练+量化代码:
optimizer = torch.optim.SGD(qat_model.parameters(), lr = 0.0001)
num_train_batches = 20
num_epochs = 8
# Train and check accuracy after each epoch
for nepoch in range(num_epochs):
train_one_epoch(qat_model, criterion, optimizer, data_loader, torch.device('cpu'), num_train_batches)
if nepoch > 3:
# Freeze quantizer parameters
qat_model.apply(torch.quantization.disable_observer)
if nepoch > 2:
# Freeze batch norm mean and variance estimates
qat_model.apply(torch.nn.intrinsic.qat.freeze_bn_stats)
# Check the accuracy after each epoch
quantized_model = torch.quantization.convert(qat_model.eval(), inplace=False)
quantized_model.eval()
top1, top5 = evaluate(quantized_model,criterion, data_loader_test, neval_batches=num_eval_batches)
print('Epoch %d :Evaluation accuracy on %d images, %2.2f'%(nepoch, num_eval_batches * eval_batch_size, top1.avg))
代码的小细节:这里感知训练量化,相较静态量化没有校准步骤,而是用完整的训练代替,因此两者的quantization.convert位置会有所不同。
最后是在测试集上的性能测试:
def run_benchmark(model_file, img_loader):
elapsed = 0
model = torch.jit.load(model_file)
model.eval()
num_batches = 5
# Run the scripted model on a few batches of images
for i, (images, target) in enumerate(img_loader):
if i < num_batches:
start = time.time()
output = model(images)
end = time.time()
elapsed = elapsed + (end-start)
else:
break
num_images = images.size()[0] * num_batches
print('Elapsed time: %3.0f ms' % (elapsed/num_images*1000))
return elapsed
run_benchmark(saved_model_dir + scripted_float_model_file, data_loader_test)
run_benchmark(saved_model_dir + scripted_quantized_model_file, data_loader_test)
最终模型推理时间对比:
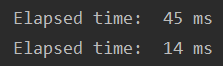
Running this locally on a MacBook pro yielded 61 ms for the regular model, and just 20 ms for the quantized model, illustrating the typical 2-4x speedup we see for quantized models compared to floating point ones。
备注:采用数据集为imagenet_1k,训练集和测试集均为1000张
dataset_train : 1000
dataset_test : 1000
补充:More on quantization-aware training(暂时未碰到下述需求)
- QAT is a super-set of post training quant techniques that allows for more debugging. For example, we can analyze if the accuracy of the model is limited by weight or activation quantization.
- We can also simulate the accuracy of a quantized model in floating point since we are using fake-quantization to model the numerics of actual quantized arithmetic.
- We can mimic post training quantization easily too.
Part2
Static Quantize to VGG-16
Note:VGG-16中没有BN层,所以相较官方教程,去掉了fuse_model的融合部分
项目目录结构:
----Quantize_Pytorch:总项目文件夹
--------data:文件夹,存储的imagenet_1k数据集
--------model:文件夹,存储的VGG-16以及MobieNet的pretrained_model预训练float型模型
--------MobileNetV2-quantize_all.py:Static Quantize 和 QAT 两种方式
--------vgg16-static_quantize.py:Static Quantize to Vgg-16
--------vgg16-aware_train_quantize.py:QAT Quantize to Vgg-16
数据集与预训练模型下载:链接:https://pan.baidu.com/s/1-Rkrcg0R5DbNdjQ4umXBtQ ;提取码:p2um
Code:https://github.com/Forggtensky/Quantize_Pytorch_Vgg16AndMobileNet;
"""
==========================
Style: static quantize
Model: VGG-16
Create by: Han_yz @ 2020/1/29
Email: 20125169@bjtu.edu.cn
Github: https://github.com/Forggtensky
==========================
"""
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.transforms as transforms
import os
import time
import sys
import torch.quantization
"""
------------------------------
1、Model architecture
------------------------------
"""
class VGG(nn.Module):
def __init__(self,features,num_classes=1000,init_weights=False):
super(VGG,self).__init__()
self.features = features # 提取特征部分的网络,也为Sequential格式
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential( # 分类部分的网络
nn.Linear(512*7*7,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,num_classes)
)
# add the quantize part
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
if init_weights:
self._initialize_weights()
def forward(self,x):
x = self.quant(x)
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x,start_dim=1)
# x = x.mean([2, 3])
x = self.classifier(x)
x = self.dequant(x)
return x
def _initialize_weights(self):
for module in self.modules():
if isinstance(module,nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias,0)
elif isinstance(module,nn.Linear):
nn.init.xavier_uniform_(module.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(module.bias,0)
cfgs = {
'vgg11':[64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M'],
'vgg13':[64,64,'M',128,128,'M',256,256,'M',512,512,'M',512,512,'M'],
'vgg16':[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M'],
'vgg19':[64,64,'M',128,128,'M',256,256,256,256,'M',512,512,512,512,'M',512,512,512,512,'M'],
}
def make_features(cfg:list):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2,stride=2)] #vgg采用的池化层均为2,2参数
else:
conv2d = nn.Conv2d(in_channels,v,kernel_size=3,padding=1) #vgg卷积层采用的卷积核均为3,1参数
layers += [conv2d,nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers) #非关键字的形式输入网络的参数
def vgg(model_name='vgg16',**kwargs):
try:
cfg = cfgs[model_name]
except:
print("Warning: model number {} not in cfgs dict!".format(model_name))
exit(-1)
model = VGG(make_features(cfg),**kwargs) # **kwargs为可变长度字典,保存多个输入参数
return model
"""
------------------------------
2、Helper functions
------------------------------
"""
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f'):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def evaluate(model, criterion, data_loader, neval_batches):
model.eval()
top1 = AverageMeter('Acc@1', ':6.2f')
top5 = AverageMeter('Acc@5', ':6.2f')
cnt = 0
with torch.no_grad():
for image, target in data_loader:
output = model(image)
loss = criterion(output, target)
cnt += 1
acc1, acc5 = accuracy(output, target, topk=(1, 5))
print('.', end = '')
top1.update(acc1[0], image.size(0))
top5.update(acc5[0], image.size(0))
if cnt >= neval_batches:
return top1, top5
return top1, top5
def run_benchmark(model_file, img_loader):
elapsed = 0
model = torch.jit.load(model_file)
model.eval()
num_batches = 5
# Run the scripted model on a few batches of images
for i, (images, target) in enumerate(img_loader):
if i < num_batches:
start = time.time()
output = model(images)
end = time.time()
elapsed = elapsed + (end-start)
else:
break
num_images = images.size()[0] * num_batches
print('Elapsed time: %3.0f ms' % (elapsed/num_images*1000))
return elapsed
def load_model(model_file):
model_name = "vgg16"
model = vgg(model_name=model_name,num_classes=1000,init_weights=False)
state_dict = torch.load(model_file)
model.load_state_dict(state_dict)
model.to('cpu')
return model
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
"""
------------------------------
3. Define dataset and data loaders
------------------------------
"""
def prepare_data_loaders(data_path):
traindir = os.path.join(data_path, 'train')
valdir = os.path.join(data_path, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
dataset = torchvision.datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
print("dataset_train : %d" % (len(dataset)))
dataset_test = torchvision.datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
print("dataset_test : %d" % (len(dataset_test)))
train_sampler = torch.utils.data.RandomSampler(dataset)
test_sampler = torch.utils.data.SequentialSampler(dataset_test)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=train_batch_size,
sampler=train_sampler)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=eval_batch_size,
sampler=test_sampler)
return data_loader, data_loader_test
# Specify random seed for repeatable results
torch.manual_seed(191009)
data_path = 'data/imagenet_1k'
saved_model_dir = 'model/'
float_model_file = 'vgg16_pretrained_float.pth'
scripted_float_model_file = 'vgg16_quantization_scripted.pth'
scripted_default_quantized_model_file = 'vgg16_quantization_scripted_default_quantized.pth'
scripted_optimal_quantized_model_file = 'vgg16_quantization_scripted_optimal_quantized.pth'
train_batch_size = 30
eval_batch_size = 30
data_loader, data_loader_test = prepare_data_loaders(data_path)
criterion = nn.CrossEntropyLoss()
float_model = load_model(saved_model_dir + float_model_file).to('cpu')
print('\n Before quantization: \n',float_model)
float_model.eval()
# Note: vgg-16 has no BN layer so that not need to fuse model
num_eval_batches = 10
print("Size of baseline model")
print_size_of_model(float_model)
# to get a “baseline” accuracy, see the accuracy of our un-quantized model
top1, top5 = evaluate(float_model, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(float_model), saved_model_dir + scripted_float_model_file) # save un_quantized model
"""
------------------------------
4. Post-training static quantization
------------------------------
"""
num_calibration_batches = 10
myModel = load_model(saved_model_dir + float_model_file).to('cpu')
myModel.eval()
# Specify quantization configuration
# Start with simple min/max range estimation and per-tensor quantization of weights
myModel.qconfig = torch.quantization.default_qconfig
print(myModel.qconfig)
torch.quantization.prepare(myModel, inplace=True)
# Calibrate with the training set
print('\nPost Training Quantization Prepare: Inserting Observers by Calibrate')
evaluate(myModel, criterion, data_loader, neval_batches=num_calibration_batches)
print("Calibrate done")
# Convert to quantized model
torch.quantization.convert(myModel, inplace=True)
print('Post Training Quantization: Convert done')
print('\n After quantization: \n',myModel)
print("Size of model after quantization")
print_size_of_model(myModel)
top1, top5 = evaluate(myModel, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(myModel), saved_model_dir + scripted_default_quantized_model_file) # save default_quantized model
"""
------------------------------
5. optimal
·Quantizes weights on a per-channel basis
·Uses a histogram observer that collects a histogram of activations and then picks quantization parameters
in an optimal manner.
------------------------------
"""
per_channel_quantized_model = load_model(saved_model_dir + float_model_file)
per_channel_quantized_model.eval()
# per_channel_quantized_model.fuse_model() # VGG dont need fuse
per_channel_quantized_model.qconfig = torch.quantization.get_default_qconfig('fbgemm') # set the quantize config
print('\n optimal quantize config: ')
print(per_channel_quantized_model.qconfig)
torch.quantization.prepare(per_channel_quantized_model, inplace=True) # execute the quantize config
evaluate(per_channel_quantized_model,criterion, data_loader, num_calibration_batches) # calibrate
print("Calibrate done")
torch.quantization.convert(per_channel_quantized_model, inplace=True) # convert to quantize model
print('Post Training Optimal Quantization: Convert done')
print("Size of model after optimal quantization")
print_size_of_model(per_channel_quantized_model)
top1, top5 = evaluate(per_channel_quantized_model, criterion, data_loader_test, neval_batches=num_eval_batches) # test acc
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(per_channel_quantized_model), saved_model_dir + scripted_optimal_quantized_model_file) # save quantized model
"""
------------------------------
6. compare performance
------------------------------
"""
print("\nInference time compare: ")
run_benchmark(saved_model_dir + scripted_float_model_file, data_loader_test)
run_benchmark(saved_model_dir + scripted_default_quantized_model_file, data_loader_test)
run_benchmark(saved_model_dir + scripted_optimal_quantized_model_file, data_loader_test)
""" you can compare the model's size/accuracy/inference time.
----------------------------------------------------------------------------------------
| origin model | default quantized model | optimal quantized model
model size: | 553 MB | 138 MB | 138 MB
test accuracy: | 79.33 | 76.67 | 78.67
inference time: | 317 ms | 254 ms | 257 ms
---------------------------------------------------------------------------------------
"""
QAT Quantize
代码见github:https://github.com/Forggtensky/Quantize_Pytorch_Vgg16AndMobileNet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号