

李宏毅2022机器学习HW4 Speaker Identification下
Task
Sample Baseline模型介绍
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# transformer
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
self.encoder = self.encoder_layer
self.pred_layer = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
模型开始对特征进行了升维以增强表示能力,随后通过transformer的encoder对数据进一步编码(未使用decoder),到这一步就包含了原来没有包含的注意力信息,以英文Sequence为例,如果原来的Sequence中每个单词是独立编码的是没有任何关联的,那么经过这一步之后,每一个单词的编码都是由其他单词编码的叠加而成。最后通过pred_layer进行预测(当然在此之前进行了一个mean pooling,这个下面会讲)。
在模型的前向传播时,模型基本是安装前面定义的各层进行计算的,我们注意到在给encoder的输入时,维度的顺序为(length,batch_size, d_model),而不是(batch_size, length, d_model),实际上这是为了并行计算?
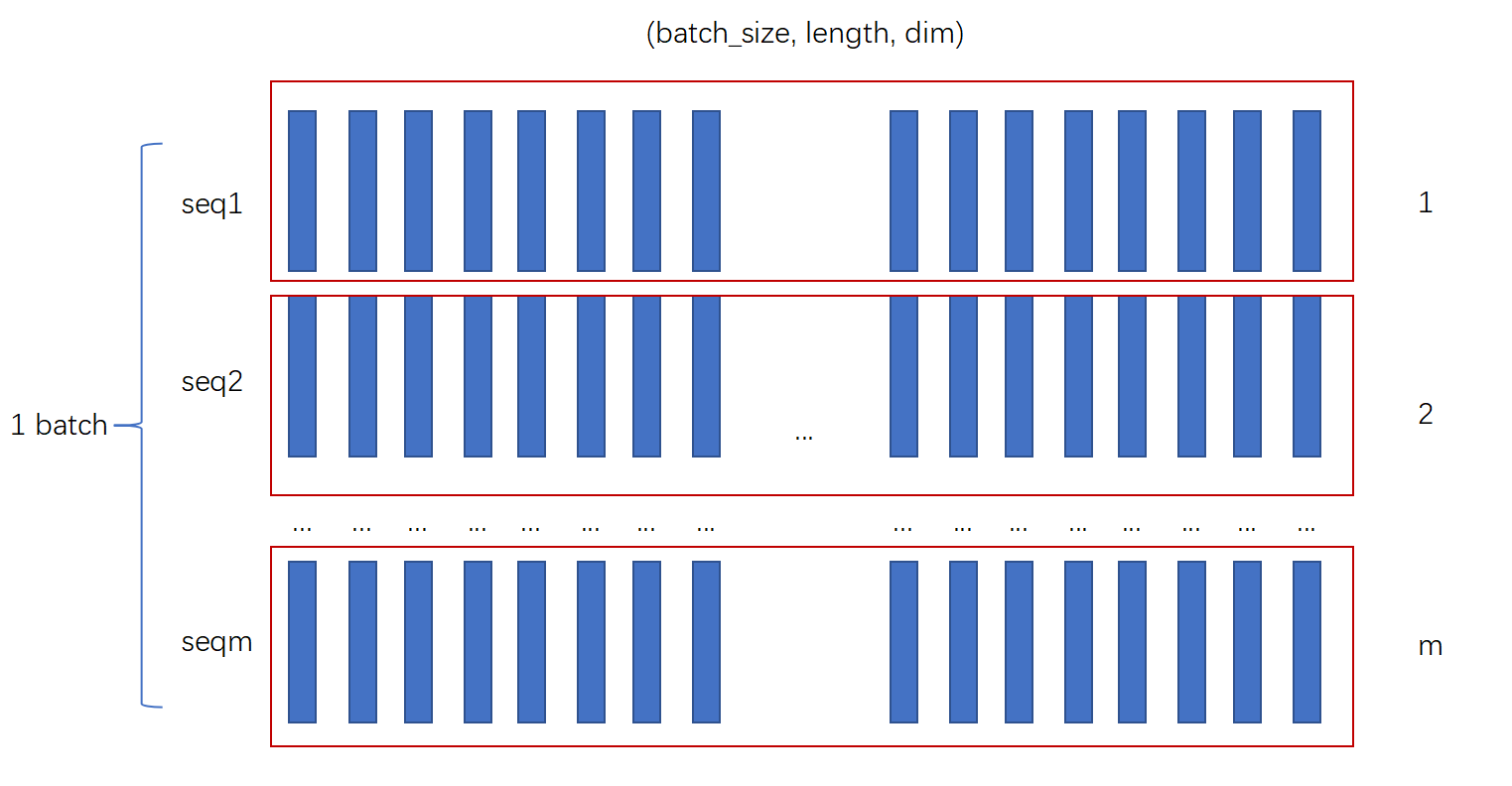
下图是batch_first时所对应的存储顺序
下图时length_first时所对应的存储顺序
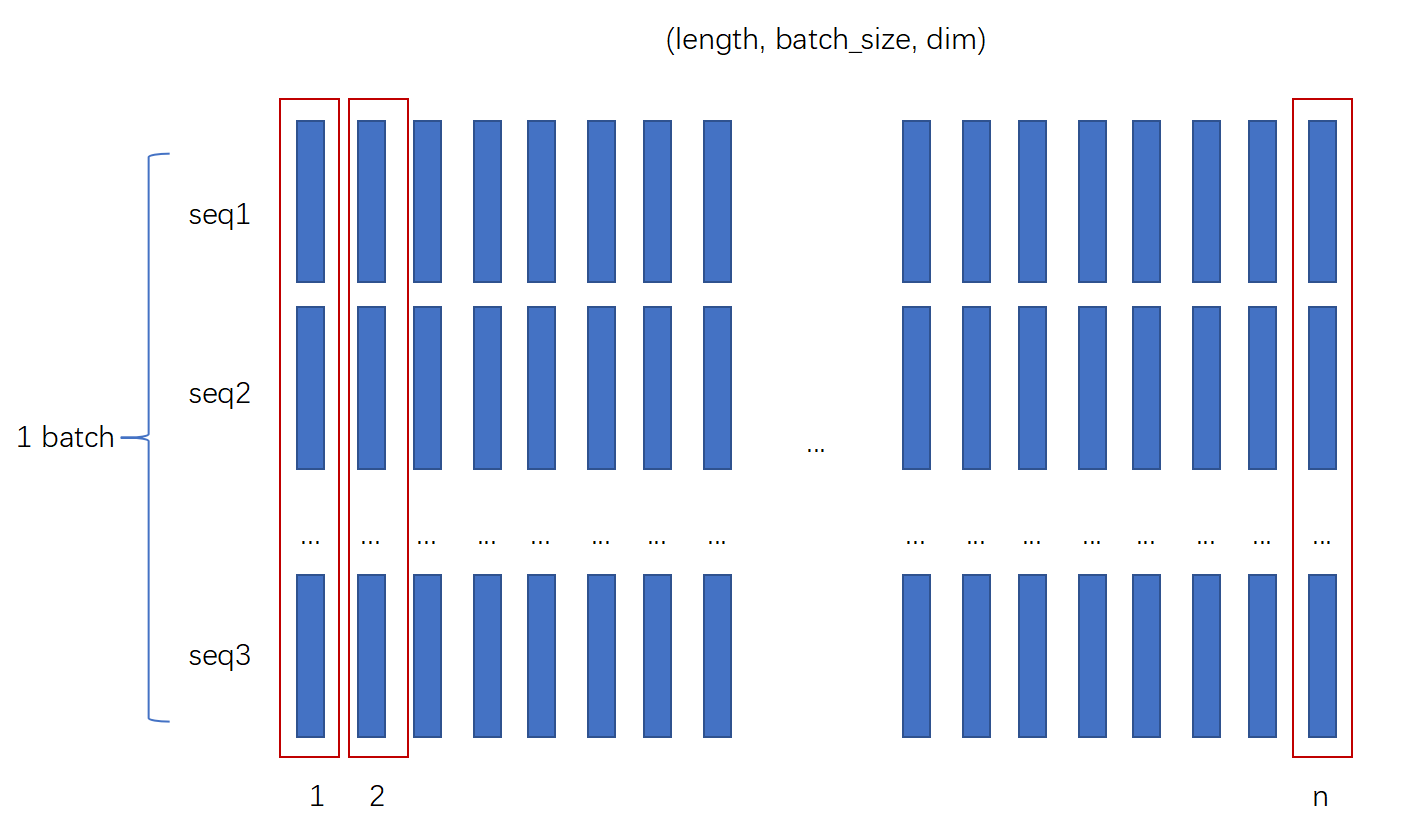
在其他时序模型中,由于需要按序输入,因此直接拿到一个sequence没啥用,不如直接得到一批batch中的所有sequence中的第一个语音序列或单词,但是在transformer中应该不需要这样吧?
另外一个小细节是进行mean pooling
stats = out.mean(dim=1)
这一步是不必可少的,不然没法输入pred_layer,这里做mean的意思是把每个sequence的所有frame通过平均合并为一个frame,如下图所示
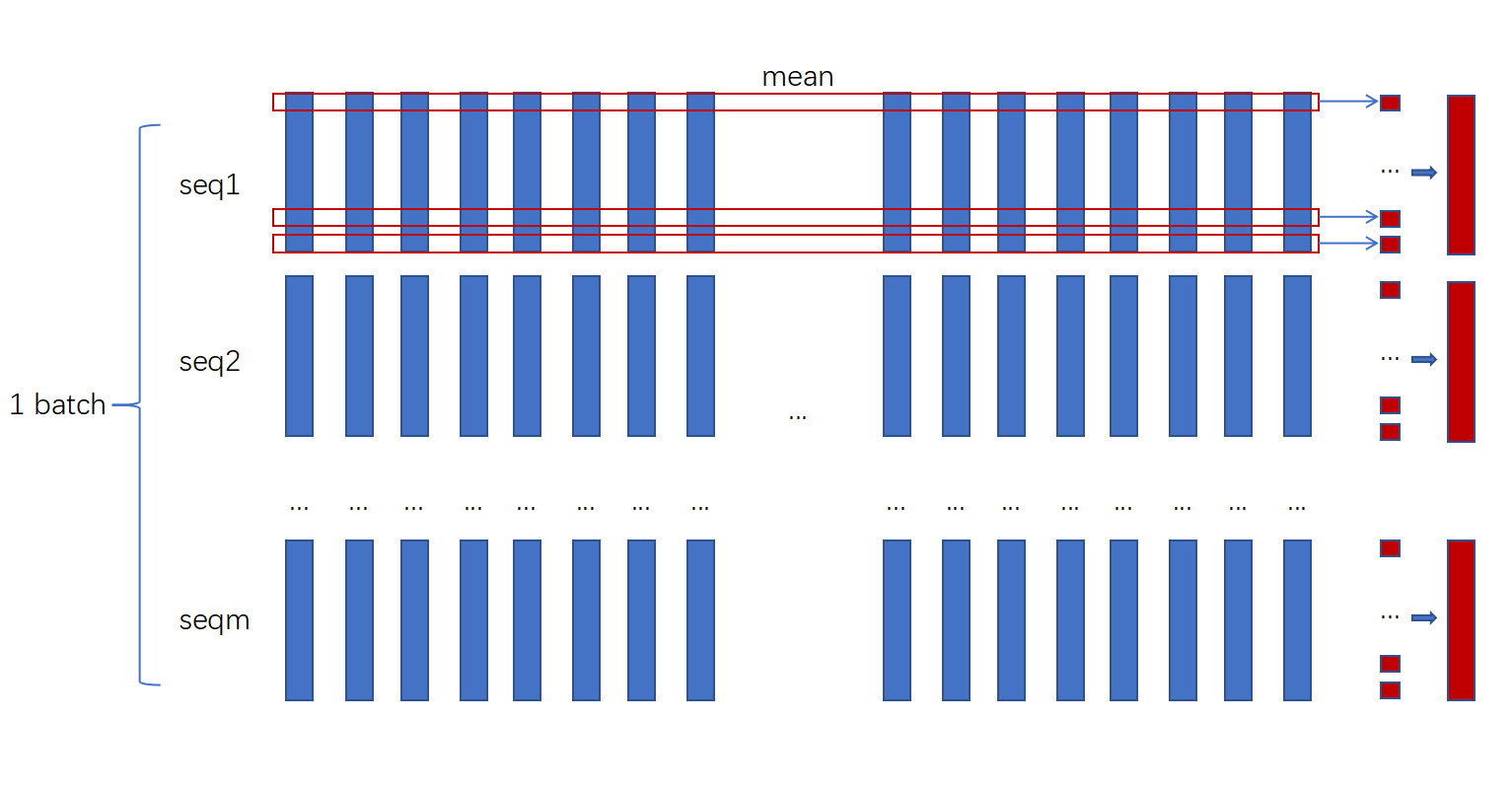
维度由batch_size\(\times\)length\(\times\)d_model变成了batch_size\(\times\)d_model
Medium Baseline
对于medium baseline,只需要调节视频中提示的地方进行修改即可,我的得分如下:

相关参数如下
d_model=120
4个encoder_layer的nhead=4
Strong Baseline
对于strong baseline,需要引入conformer架构,我的得分如下:

而conformer的引入需要注意以下几点:
引入(当然你也可以使用pip进行单独安装)
from torchaudio.models.conformer import Conformer
由于torchaudio中实现的conformer默认是batch_first,因此在代码中我们需要去掉下面两行
out = out.permute(1, 0, 2)
out = out.transpose(0, 1)
Boss Baseline
引入self-attention pooling和additive margin softmax后,准确率下降了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号