第一次个人编程作业
(一)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | <个人编程项目,设计论文查重算法> |
| github仓库(master分支) | https://github.com/hypocodeemia/hypocodeemia |
(二)PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| Estimate | 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 480 | 540 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 40 | 50 |
| Design Review | 设计复审 | 20 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| Design | 具体设计 | 60 | 70 |
| Coding | 具体编码 | 180 | 200 |
| Code Review | 代码复审 | 30 | 35 |
| Test | 测试(自我测试,修改代码,提交修改) | 75 | 90 |
| Reporting | 报告 | 90 | 110 |
| Test Repor | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 15 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 45 | 50 |
| 合计 | 600 | 695 |
(三)计算模块接口的设计与实现过程
(1)项目结构
点击查看代码
text_plagiarism_check/
├── src/
│ └── main/
│ │ └── java/
│ │ └── com/linjiajun/text_plagiarism_check/
│ │ └── TextPlagiarismCheckApplication #main
│ │ └── algorithm/
│ │ └── SimHashAlgorithm #SimHash类
│ │ └── service/
│ │ └── TextPlagiarismCheckService #文章查重service接口
│ │ └── impl/
│ │ └── TextPlagiarismCheckServiceImpl#文章查重service实现类
│ │ └── util/
│ │ └── TextUtil #文本处理工具类
│ └── test/
│ └── java/
│ └── com/linjiajun/text_plagiarism_check/
│ └── TextPlagiarismCheckApplicationTests #单元测试类
└── pom.xml #pom
(2)关键函数的调用关系
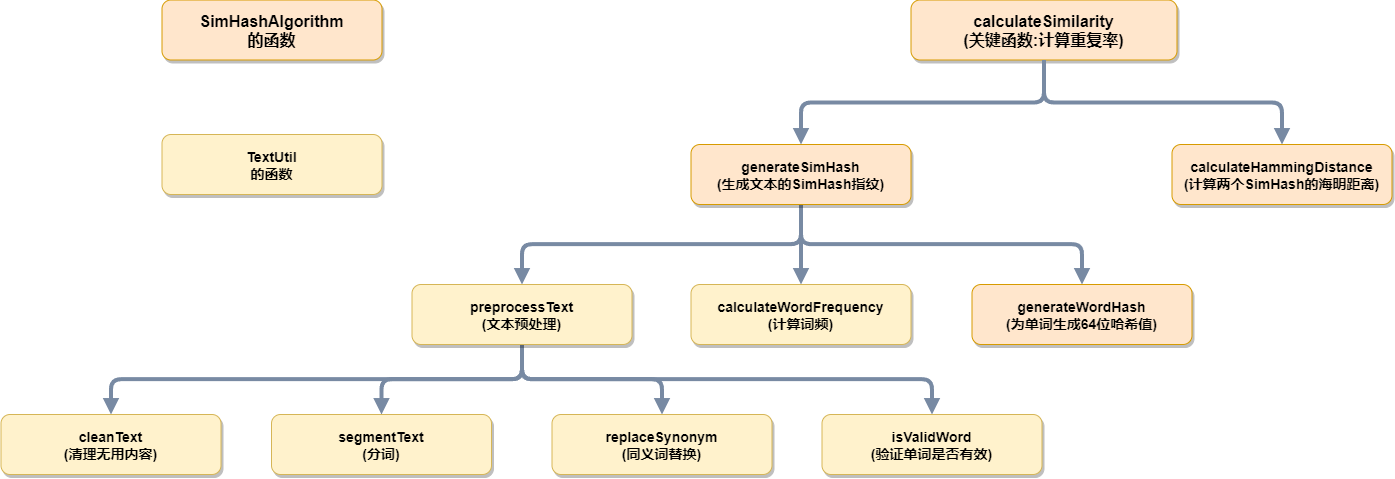
(3)算法原理
核心算法:SimHash算法
其核心思想是在于,相似的文本会产生相似的哈希值,那么我们只需要将目标文件内容进行读取,随后对其进行分词,接着开始同义词的替换,停用词的去除,就能得到用于SimHash的String集合。
单词的权重在词库完善的时候可用词频进行初始化,然后就是生成每个单词的哈希,对他们进行加权合并,再将合并后的向量二值化,以生成SimHash指纹。
生成完两个文章的SimHash指纹后即可计算它们的海明距离(两个等长字符串对应位置不同字符的数量),再用下方公式得到重复率
重复率 = 1 - 海明距离 / 总位数
(4)独到之处
①SimHash的时间复杂度为O(n),计算快,适用于海量数据以及论文这种长文本。
②空间效率极高
③抗噪性强:对同义词、词序变化、局部修改具有鲁棒性
(四)计算模块接口部分的性能改进
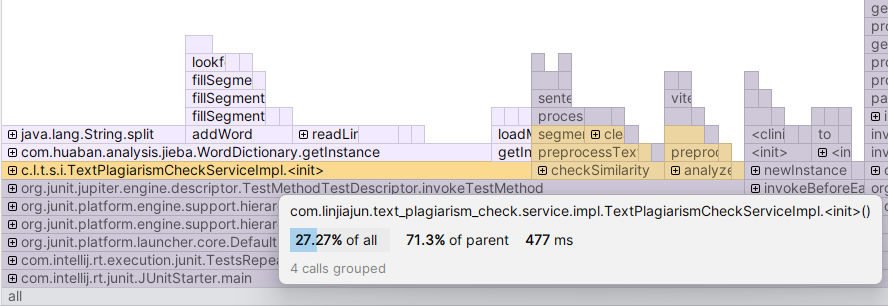

除去junit和spring上下文的启动等
(1)耗时最长,内存占用最多的就是TextPlagiarismCheckServiceImpl的init
具体来说就是TextUtil的init中,jieba分词器JiebaSegmenter的创建
如果要想减少该部分的性能占用,那么可能就需要导入更加轻量级的分词器进行使用,或者自己编写一个较为简易的分词器,但这样的话,会影响分词的质量,这将直接影响到重复率的计算正确性。
(2)耗时第二长,内存占用第二多的的是checkSimilarity→calculateSimilarity→generateSimHash→preprocessText→segmentText
也就是文本的分词,这一点同上方的第一点,认为可以导入更加轻量级的分词器进行使用,或者自己编写一个较为简易的分词器,但这样的话,会影响分词的质量。
(3)综上可知,算法本身计算重复率耗时和占用内存很少,但是文本的预处理耗时长,内存占用多
(五)计算模块部分单元测试展示
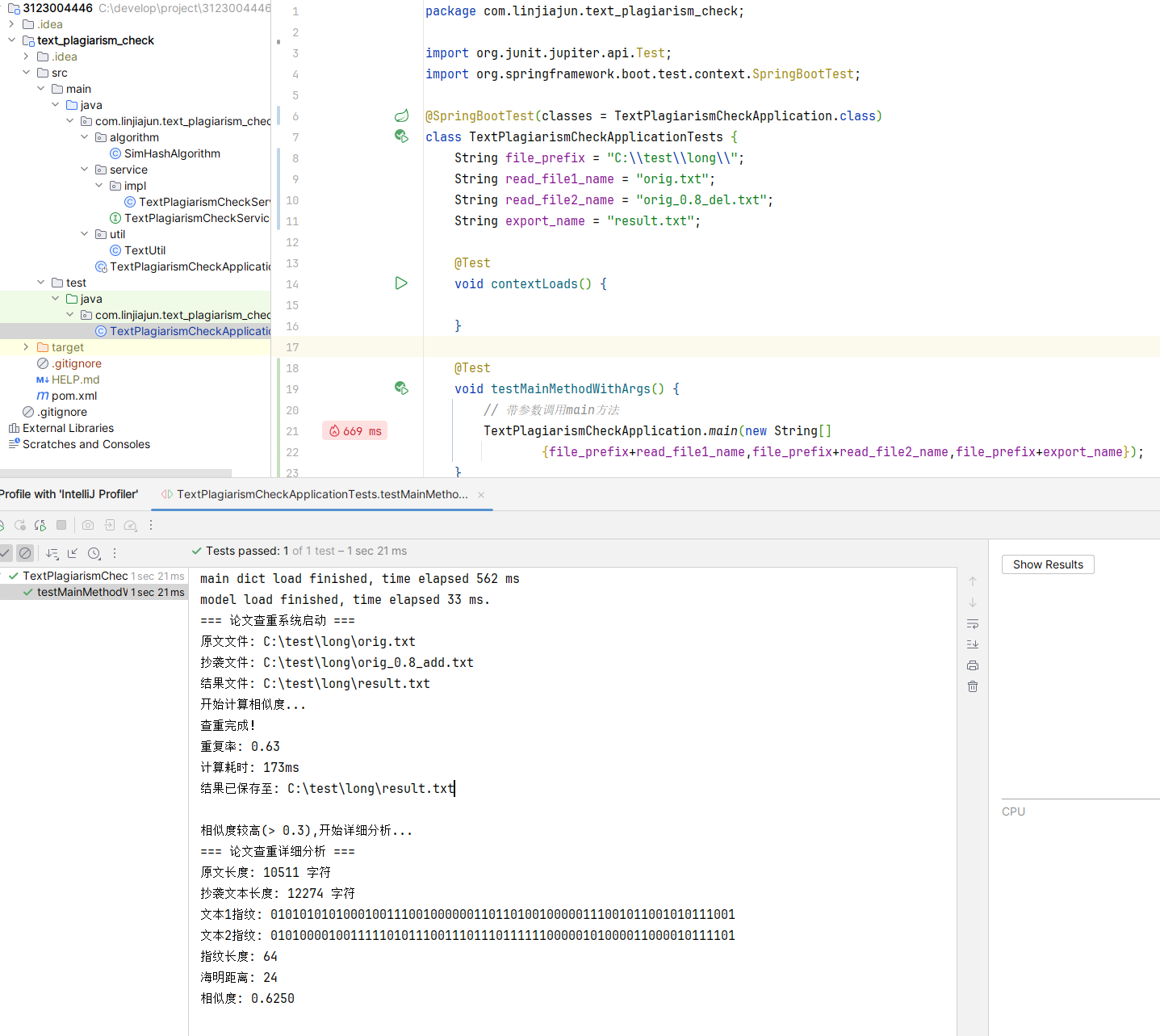


(六)计算模块部分异常处理说明
(1)文件获取,读取异常,属于IOException
单元测试
点击查看代码
@Test
void testMainMethodWithWrongAddress() {
// 带错误地址参数调用main方法
TextPlagiarismCheckApplication.main(new String[]{file_prefix,file_prefix,file_prefix+export_name});
}
处理
点击查看代码
@Override
public String readFileContent(String filePath) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
throw new IOException("文件不存在: " + filePath);
}
if (!file.canRead()) {
throw new IOException("无法读取文件: " + filePath);
}
return FileUtils.readFileToString(file, StandardCharsets.UTF_8);
}
处理策略:输出错误信息并退出程序
(2)main方法参数不足
单元测试
点击查看代码
@Test
void testMainMethodWithOutArgs() {
// 不带参数调用main方法
TextPlagiarismCheckApplication.main(new String[]{});
}
处理
点击查看代码
// 检查命令行参数
if (args.length != 3) {
System.out.println("参数不全,请参考下列说明");
printUsage();
System.exit(1);
}
(七)PSP总结
实际耗时比预估时间多出95分钟,主要是在学习SimHash算法,以及多种算法的选择上多花了时间
(八)项目改进方向
(1)完善同义词库和停用词库
(2)对“论文”进行特殊对待
①将部分的特殊符号,数学公式进行保留
②学术相关单词的权重加大
(3)多维度进行评估:SimHash相似度,局部相似度,结构相似度,最终可以进行一个加权汇总

 浙公网安备 33010602011771号
浙公网安备 33010602011771号