app爬虫之路 xx美食
准备
Fiddler设置
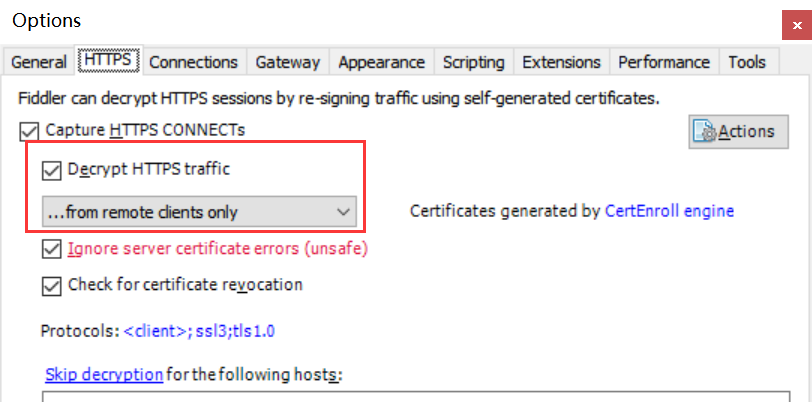
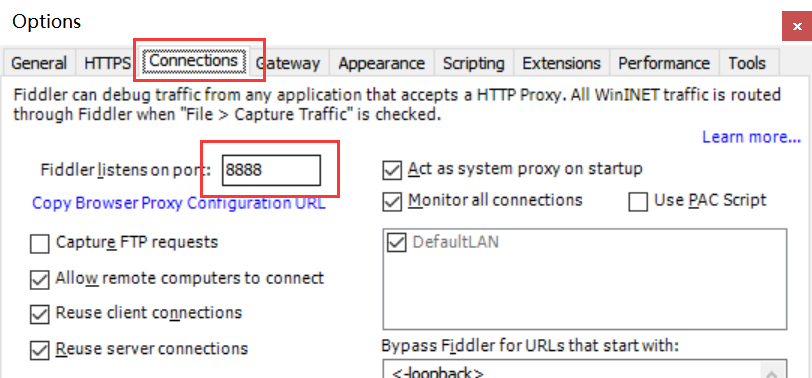
模拟器设置

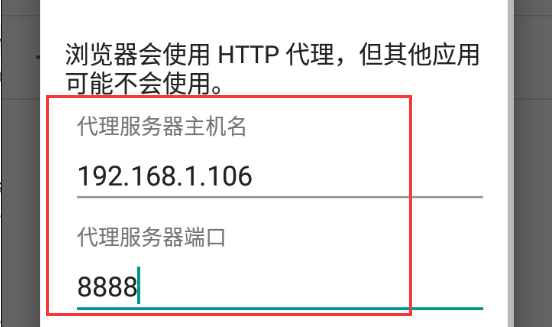
安装证书
点击下载的证书文件
重启模拟器或Fiddler
抓包
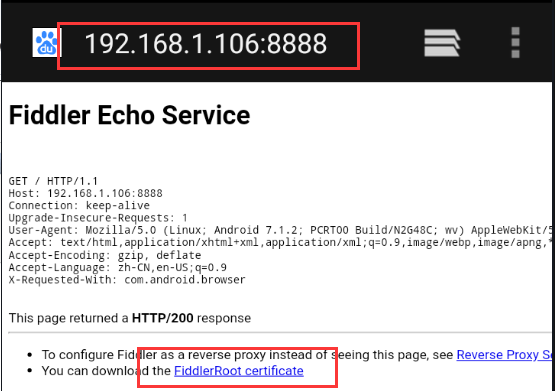
确定Fiddler能抓包
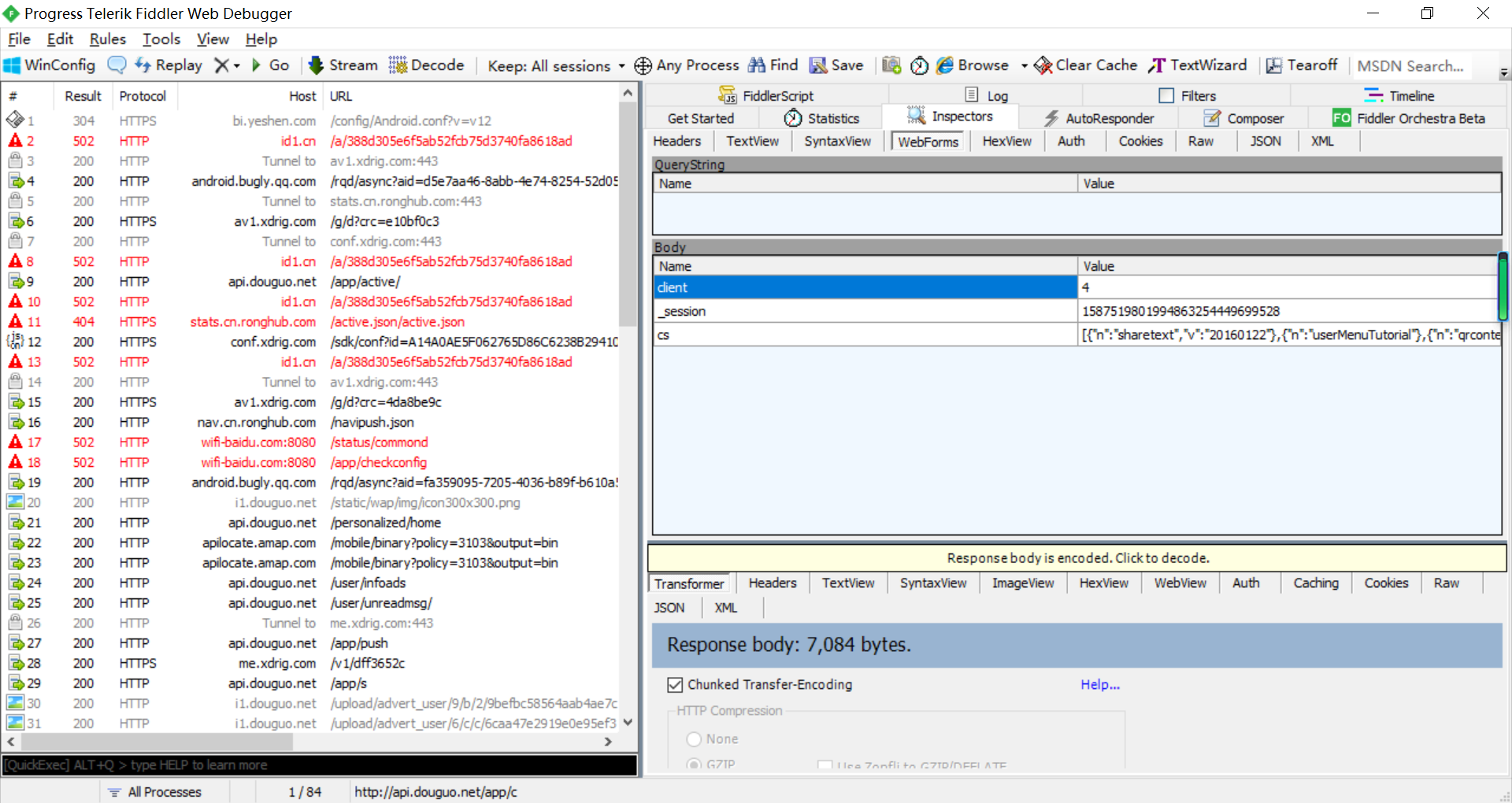
分析Fiddler数据包
过滤
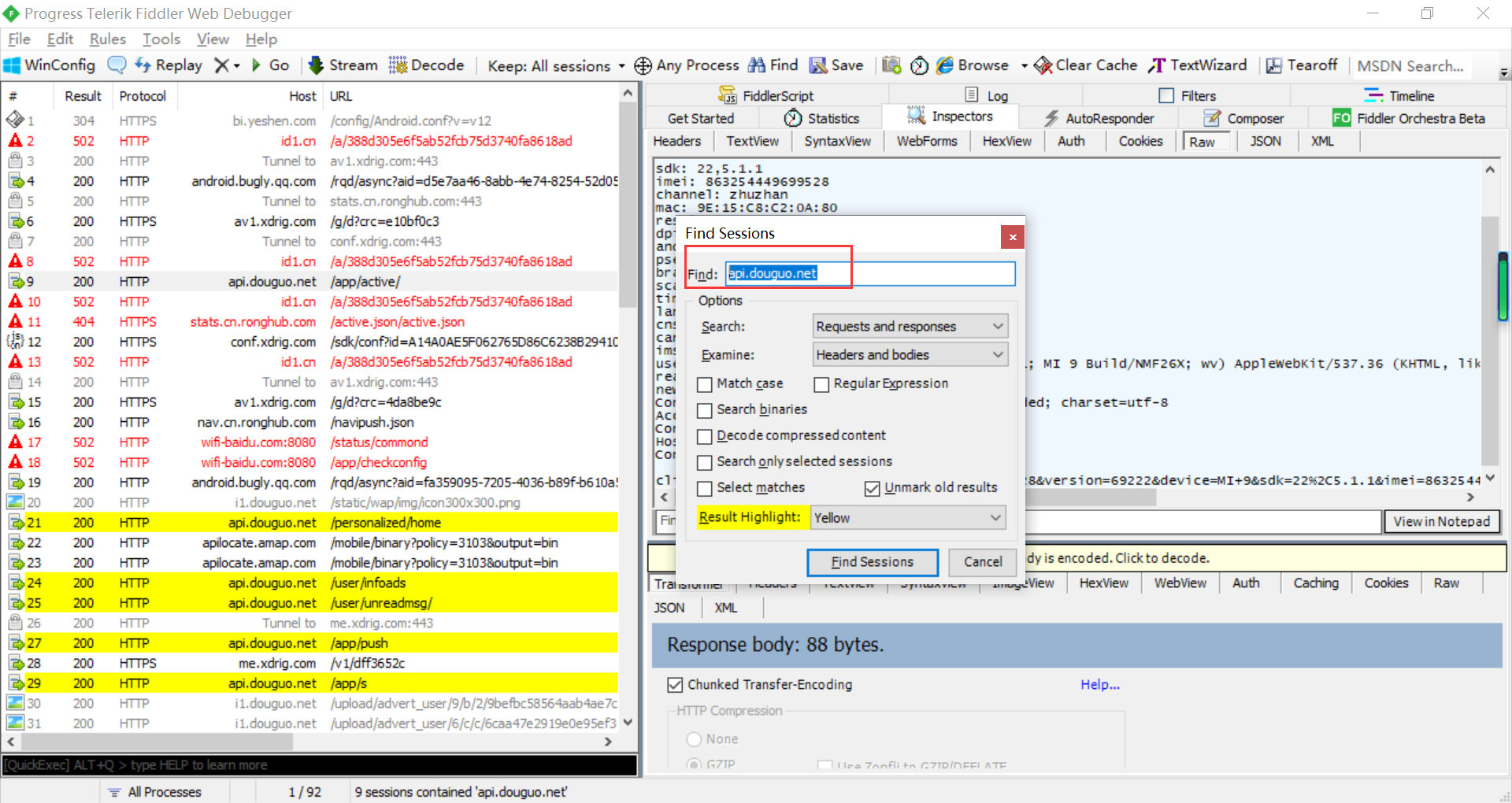
第一个数据包
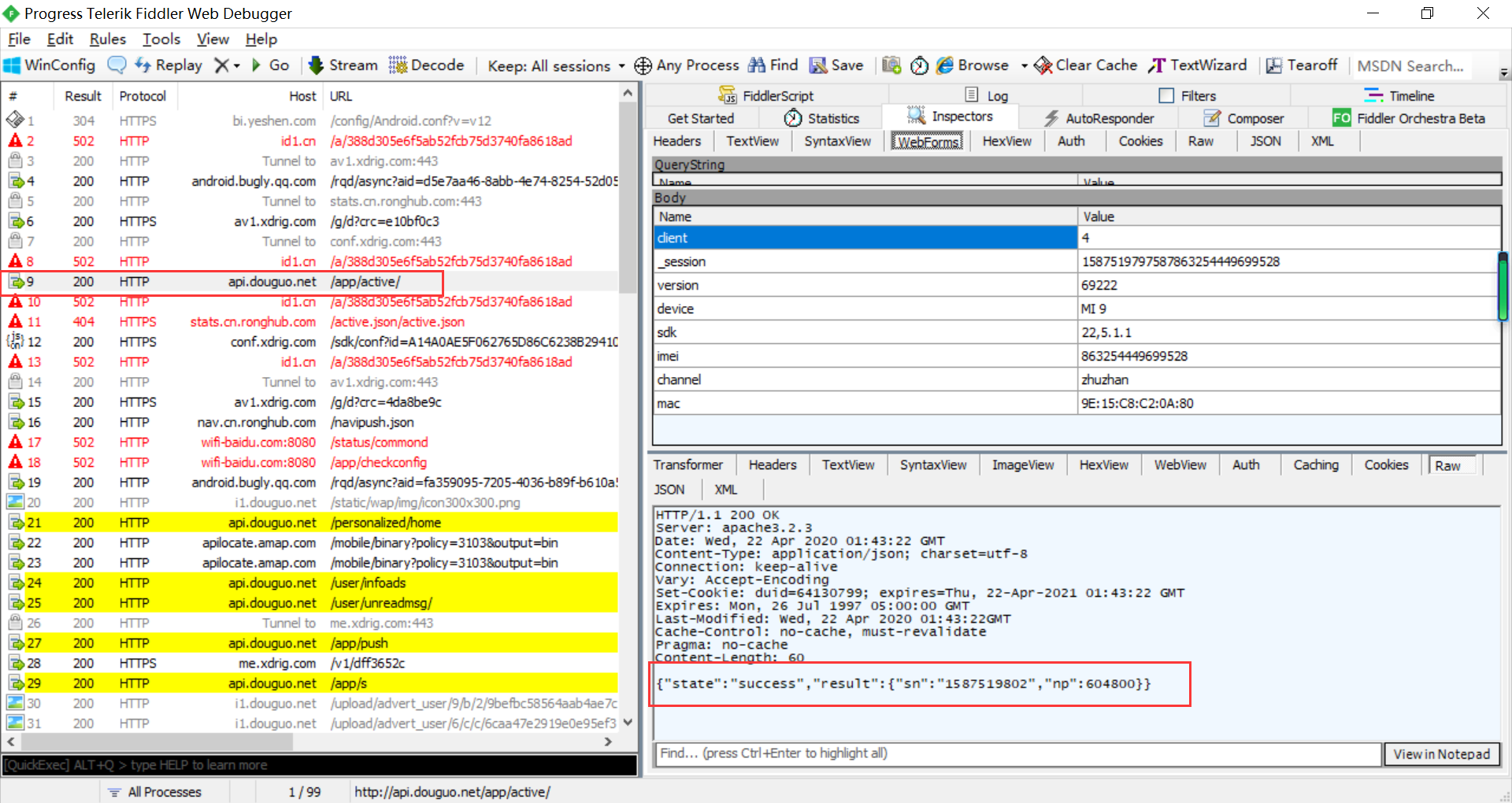
第二个数据包
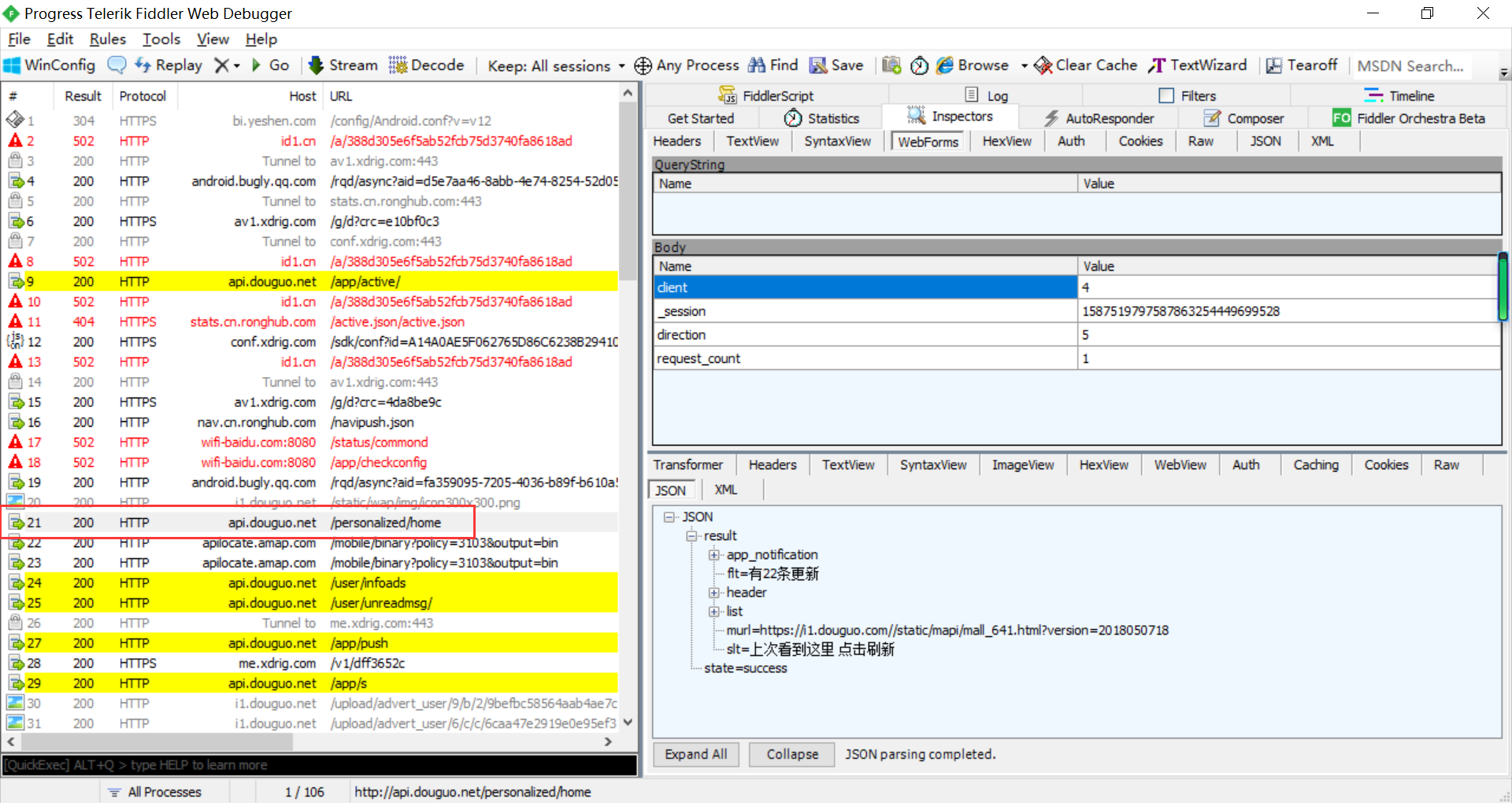
方便查看Json格式
raw->双击 返回数据并复制
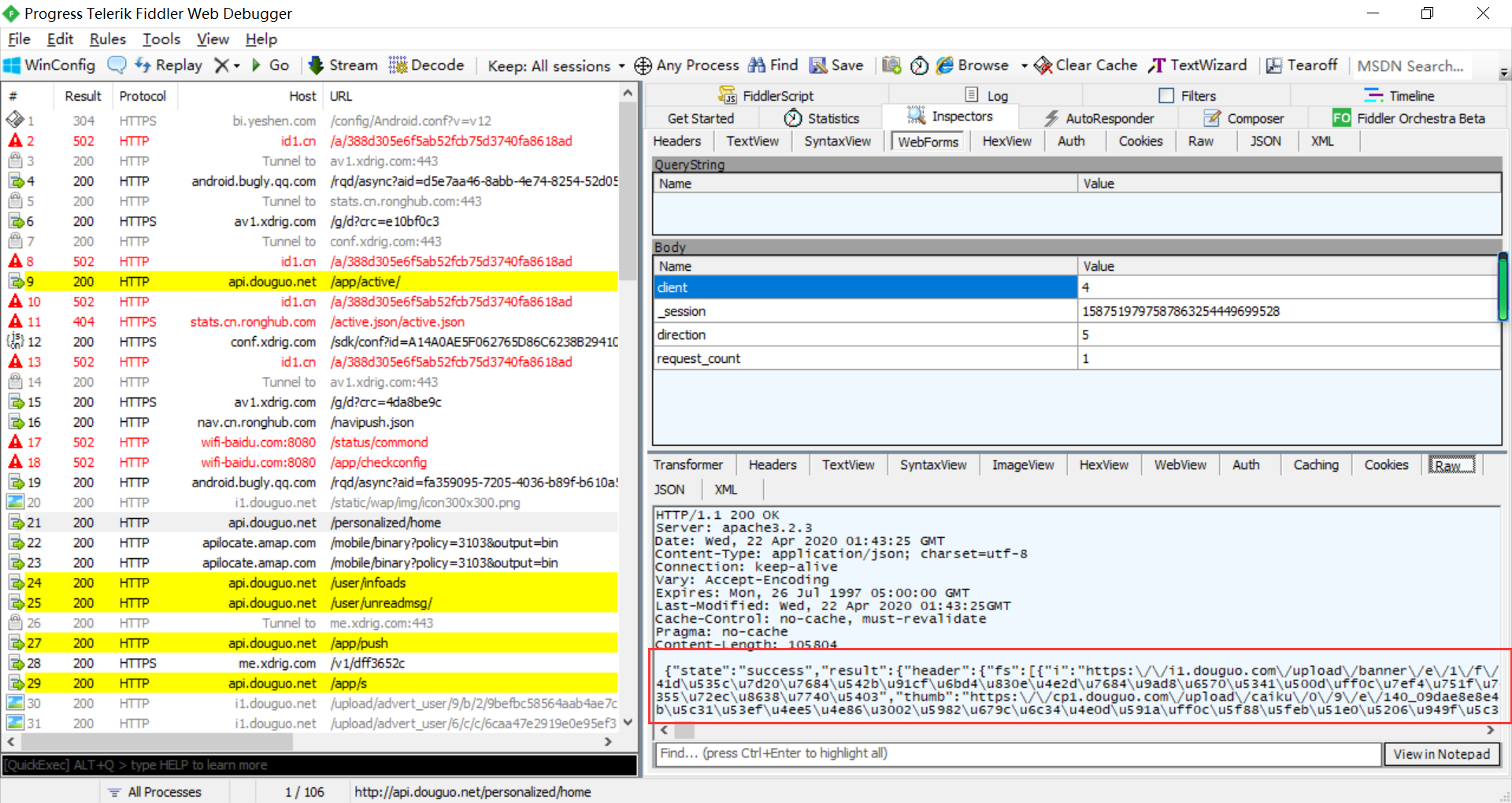
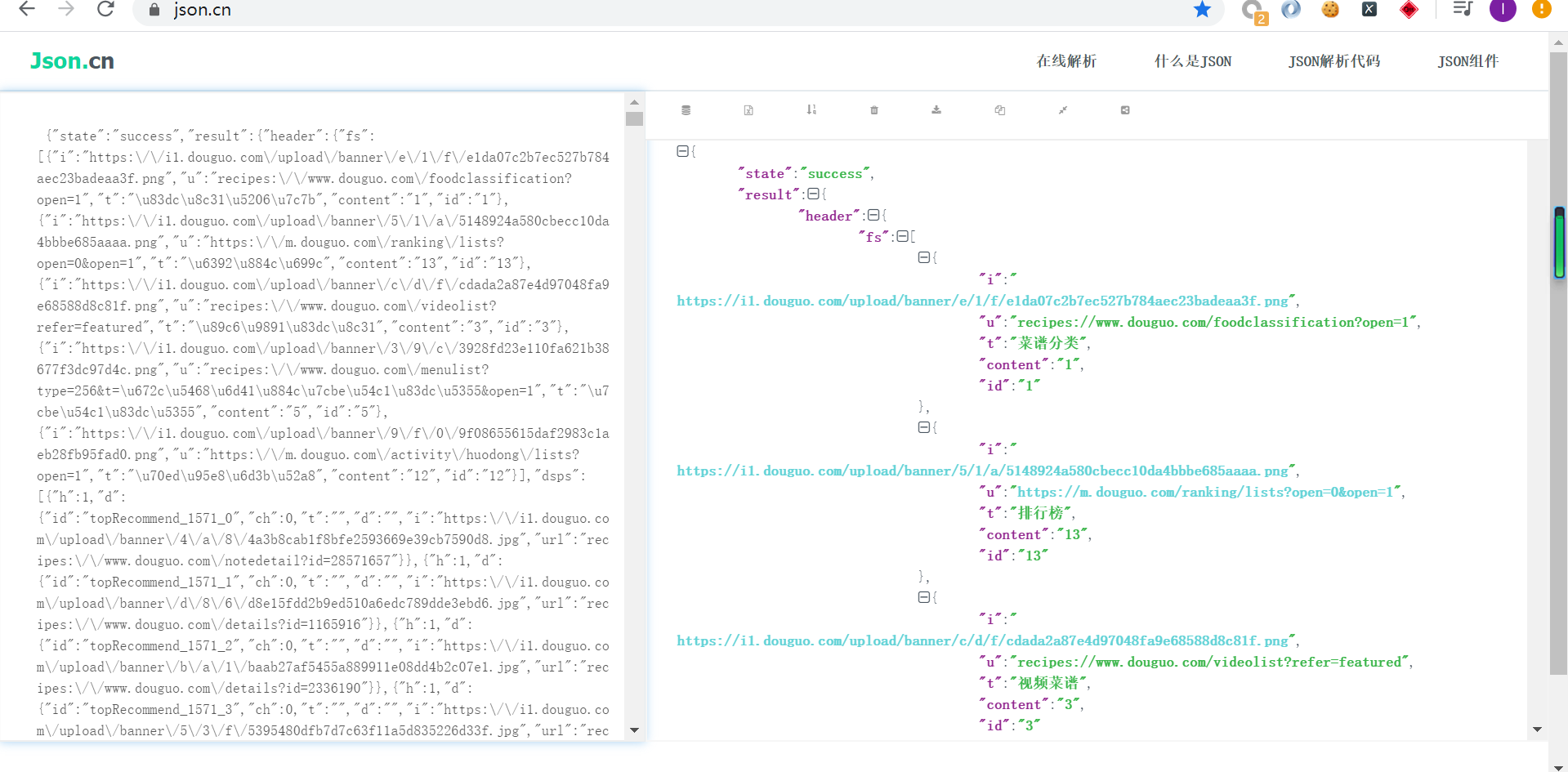
菜谱分类接口分析
菜谱分类界面
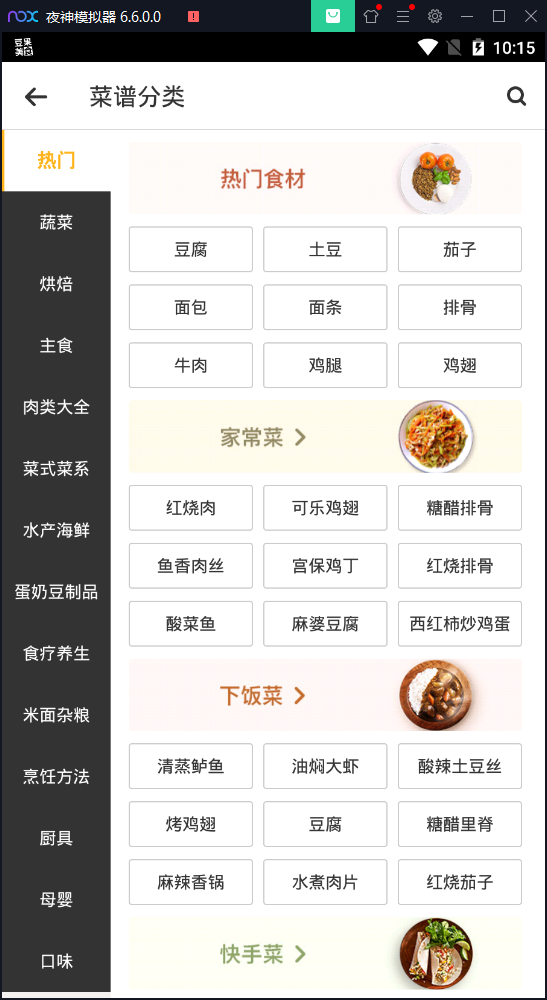
菜谱分类接口
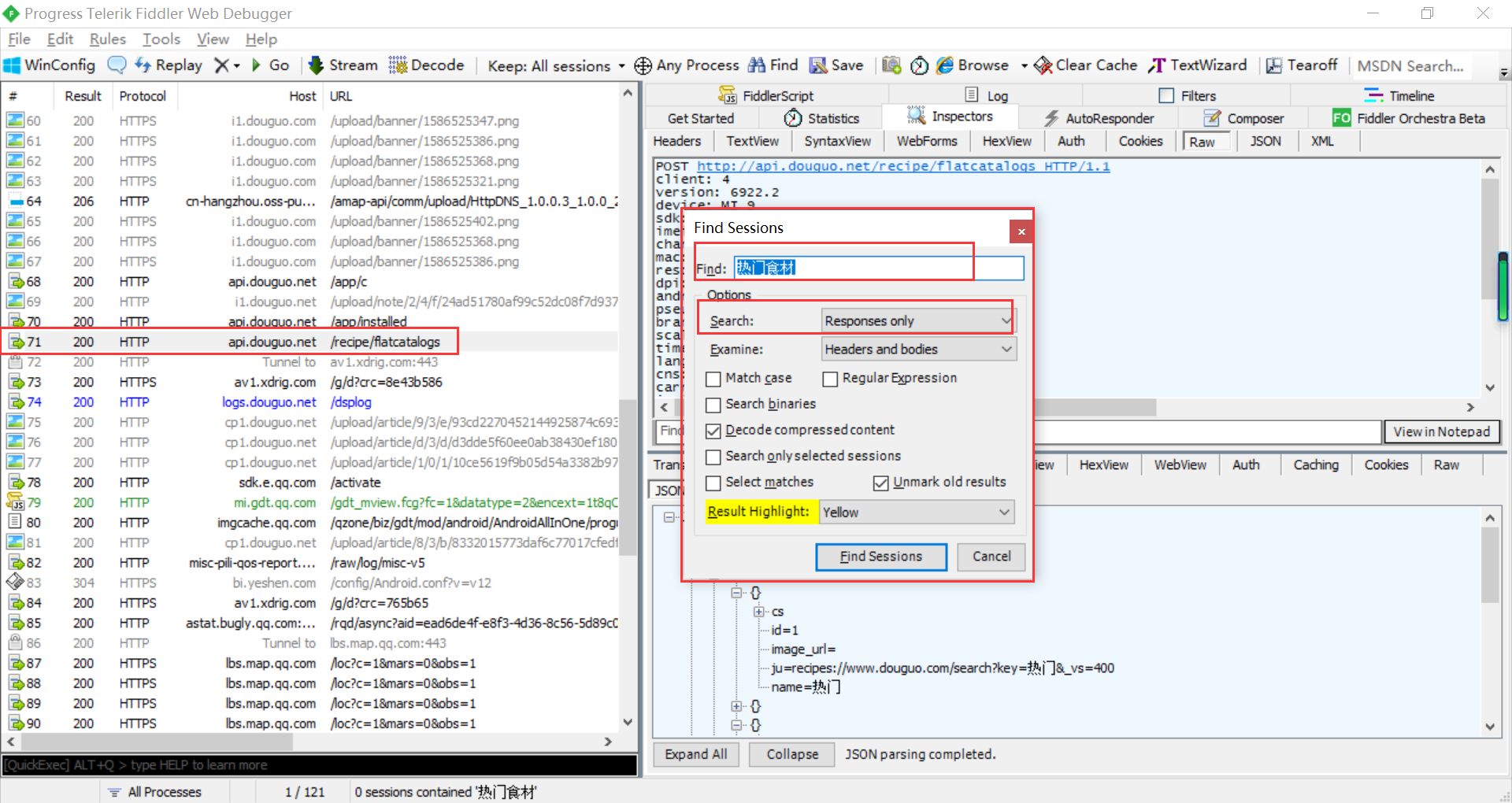
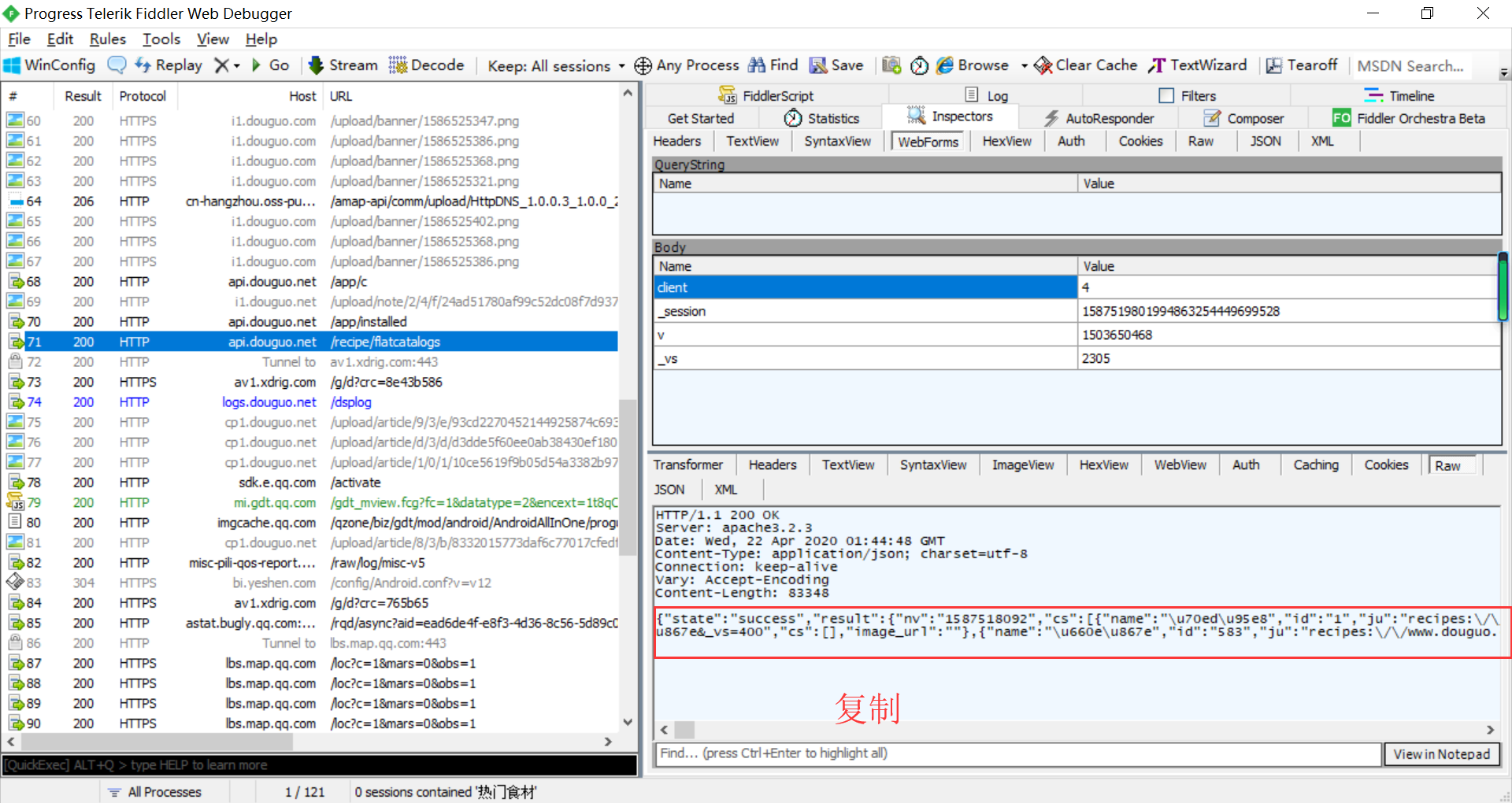
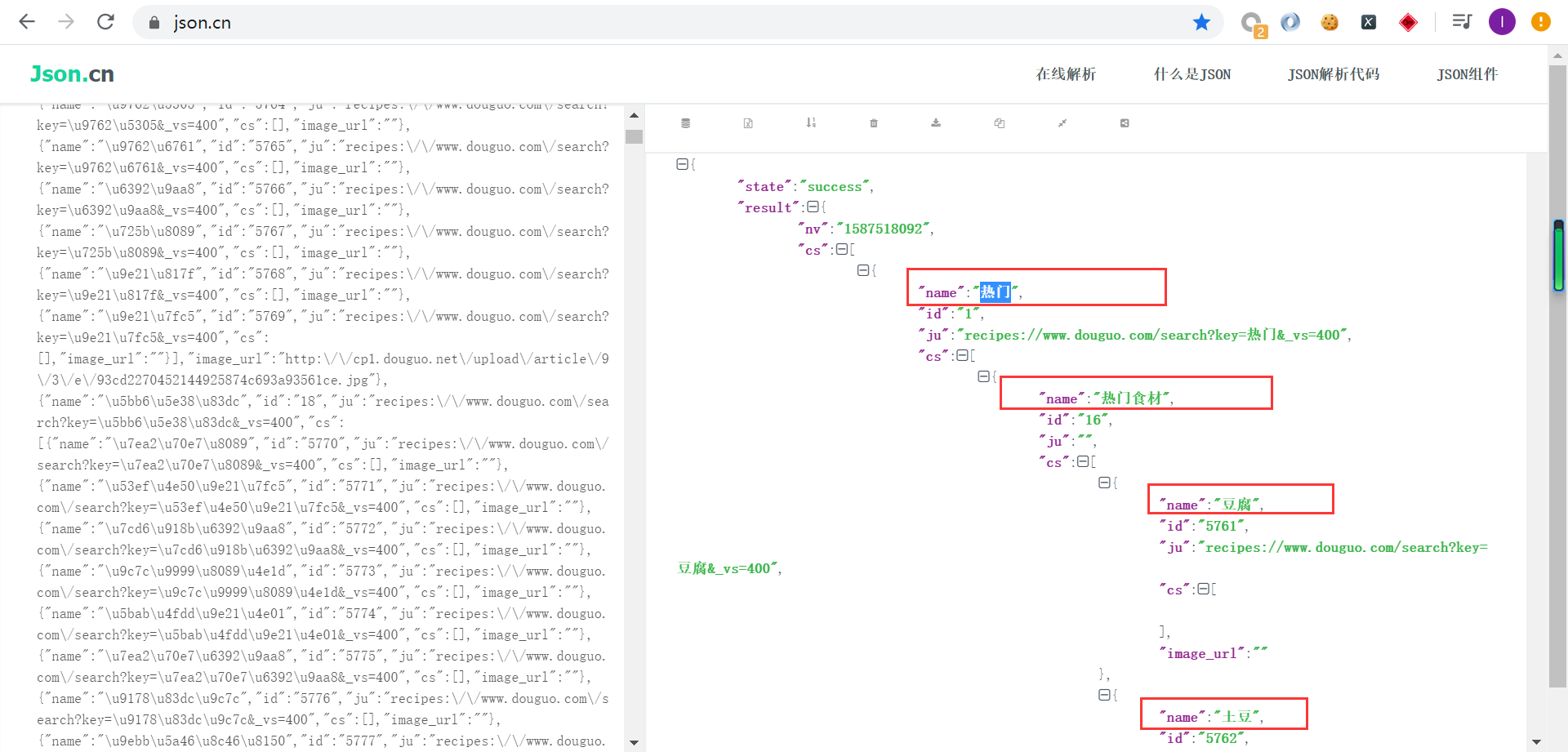

保存数据包,方便下次分析

编码实现
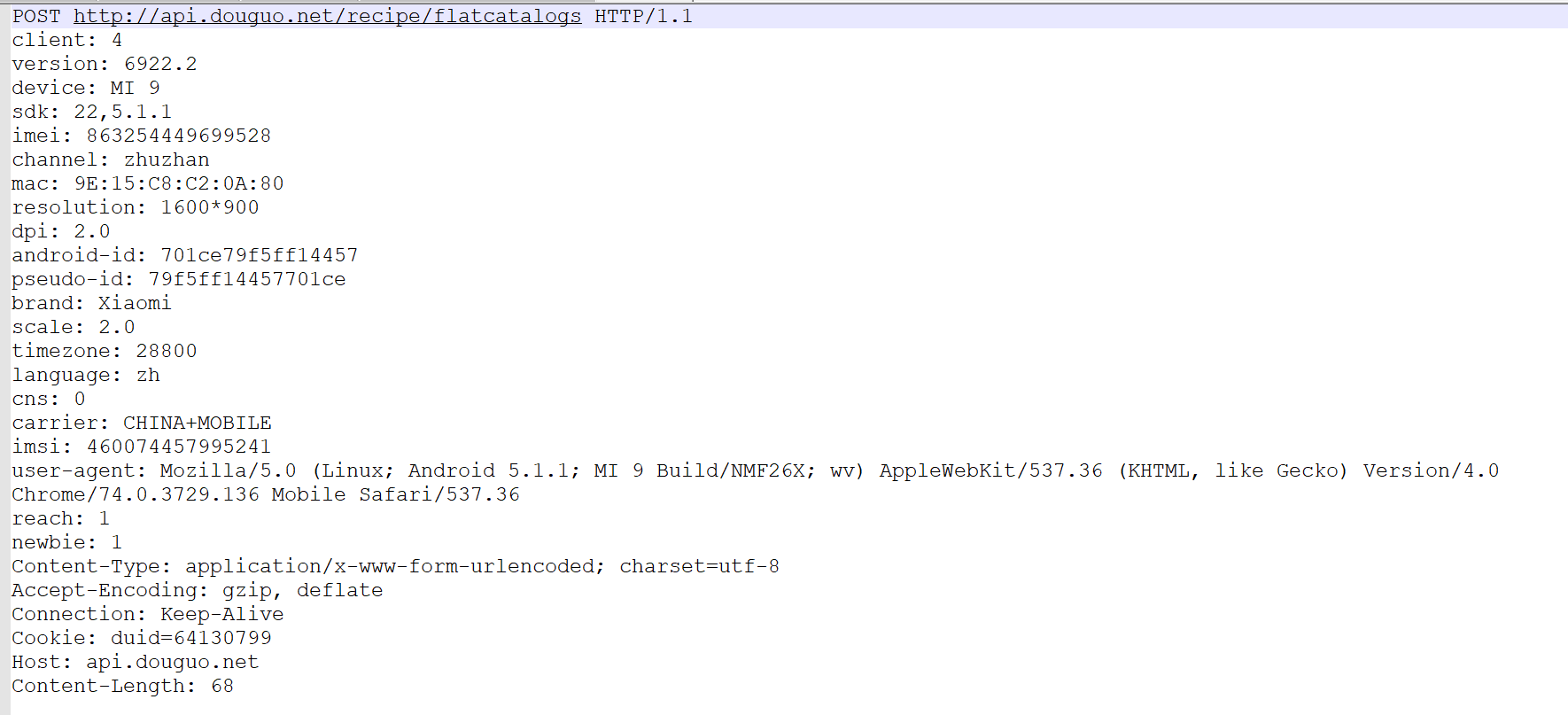
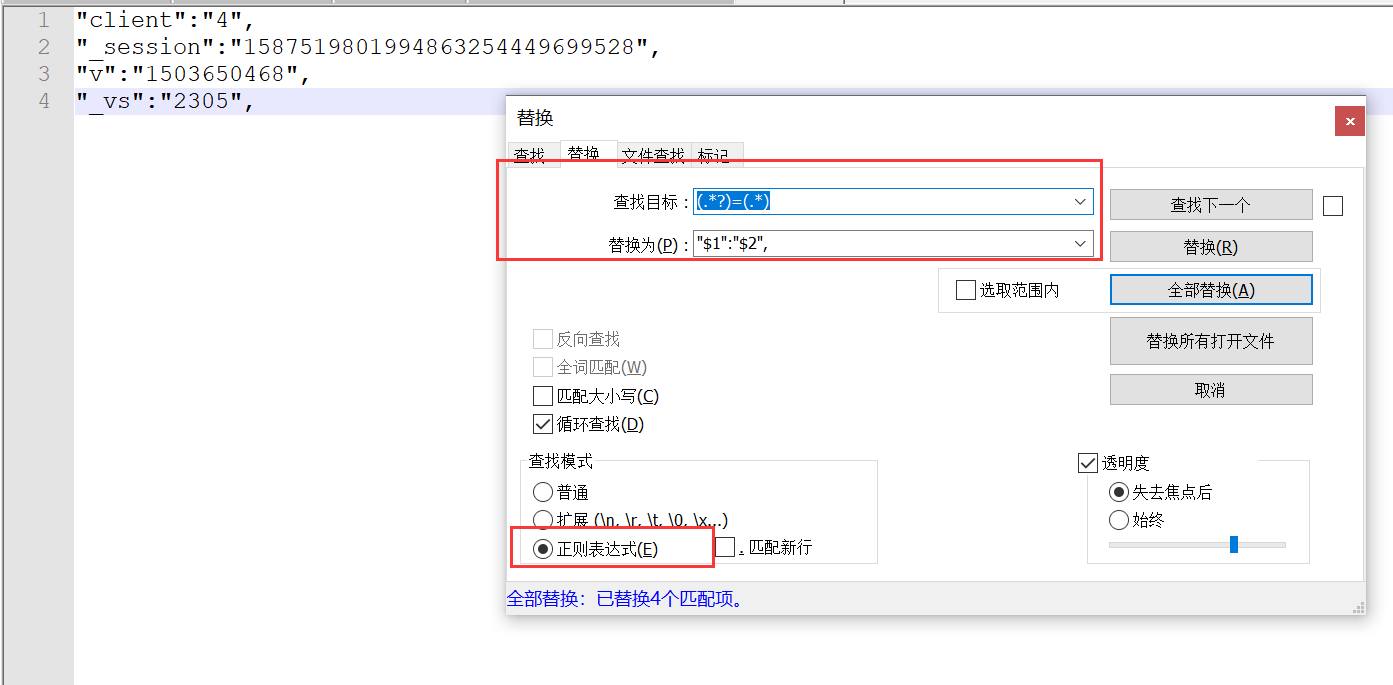
格式请求和响应
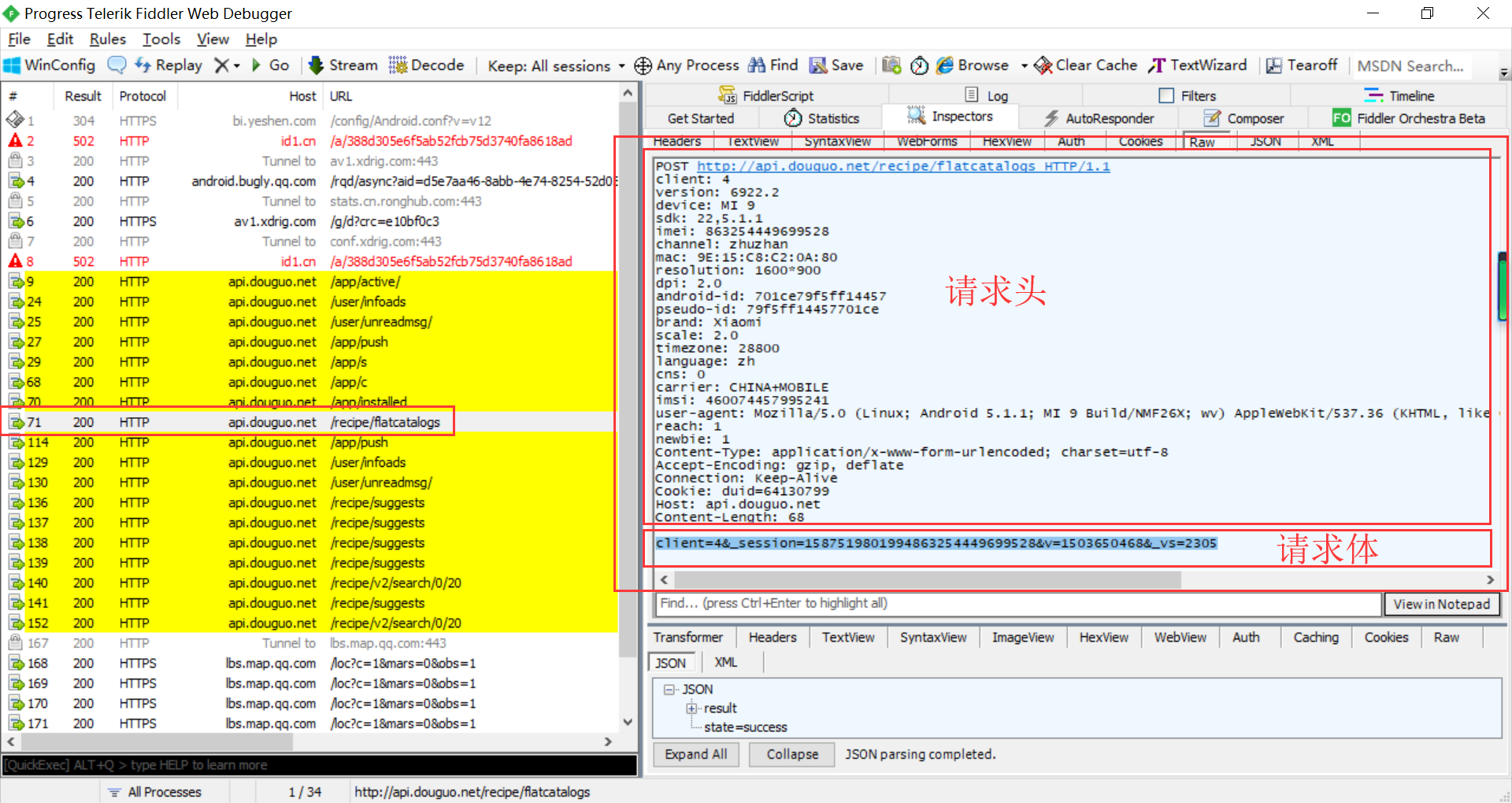
(.*?): (.*) "$1":"$2",
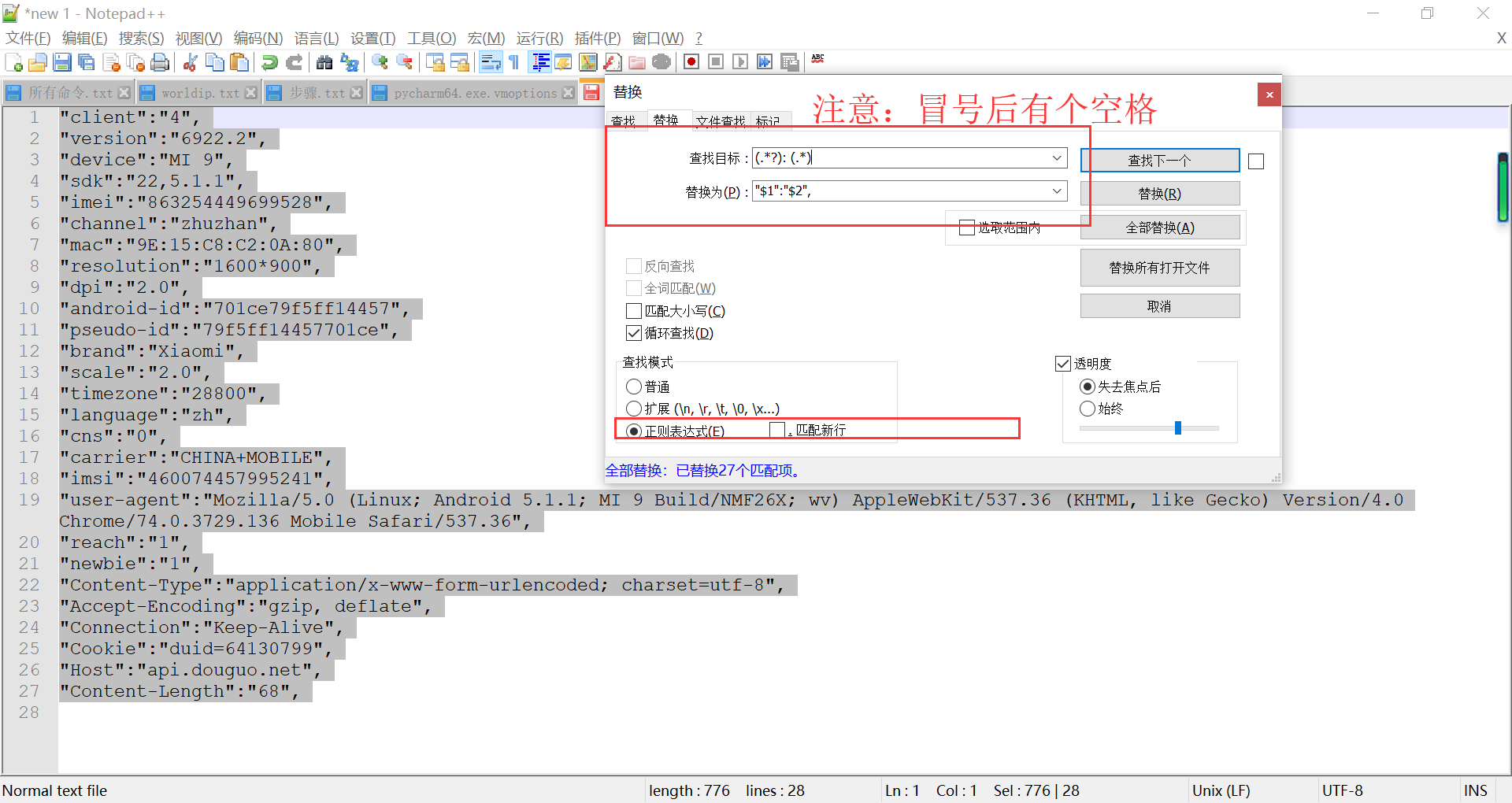
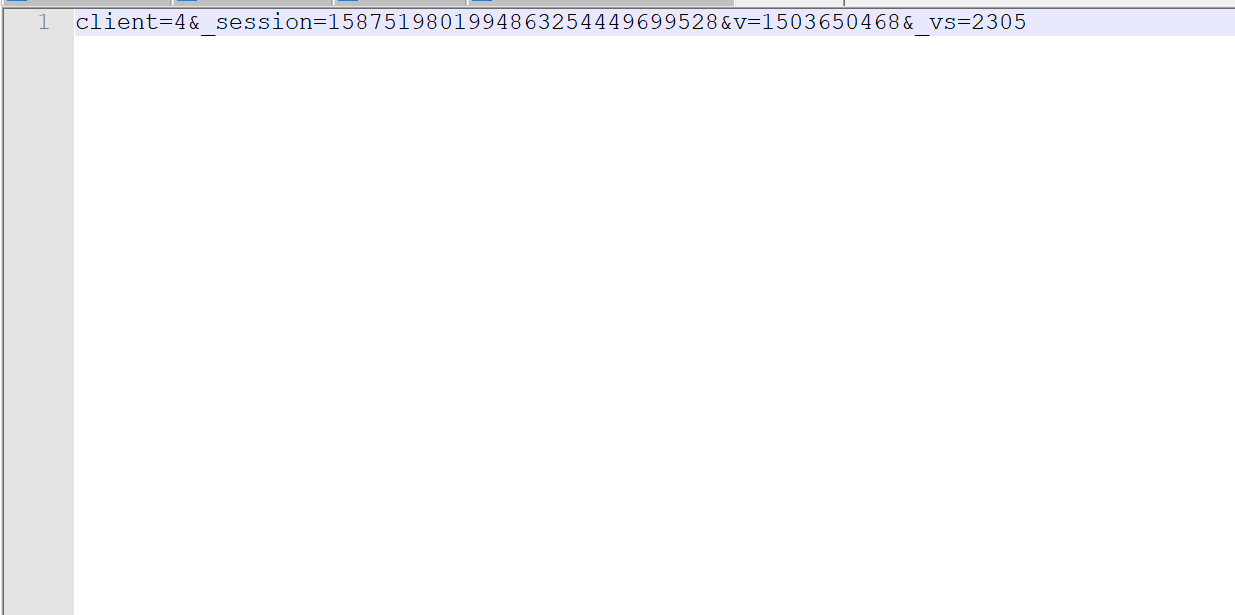
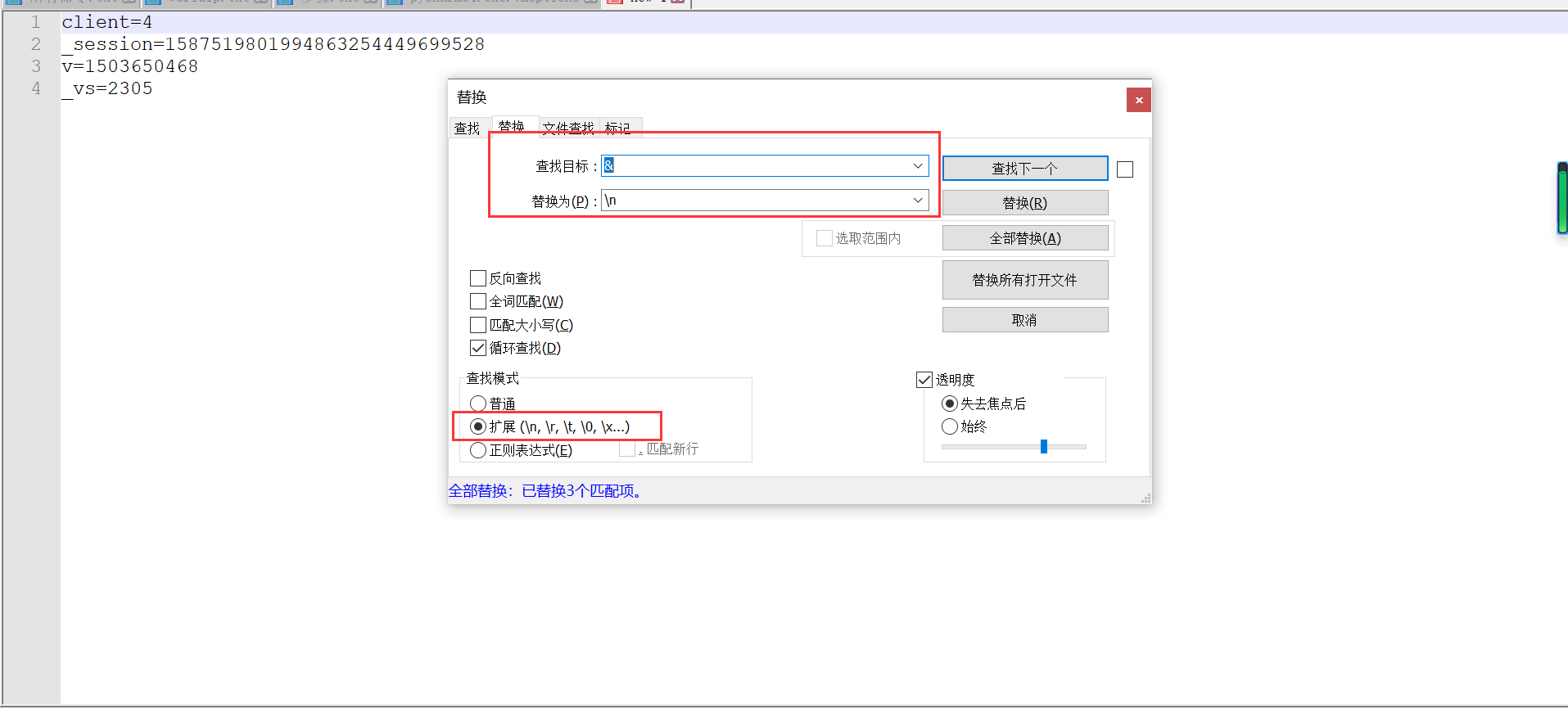
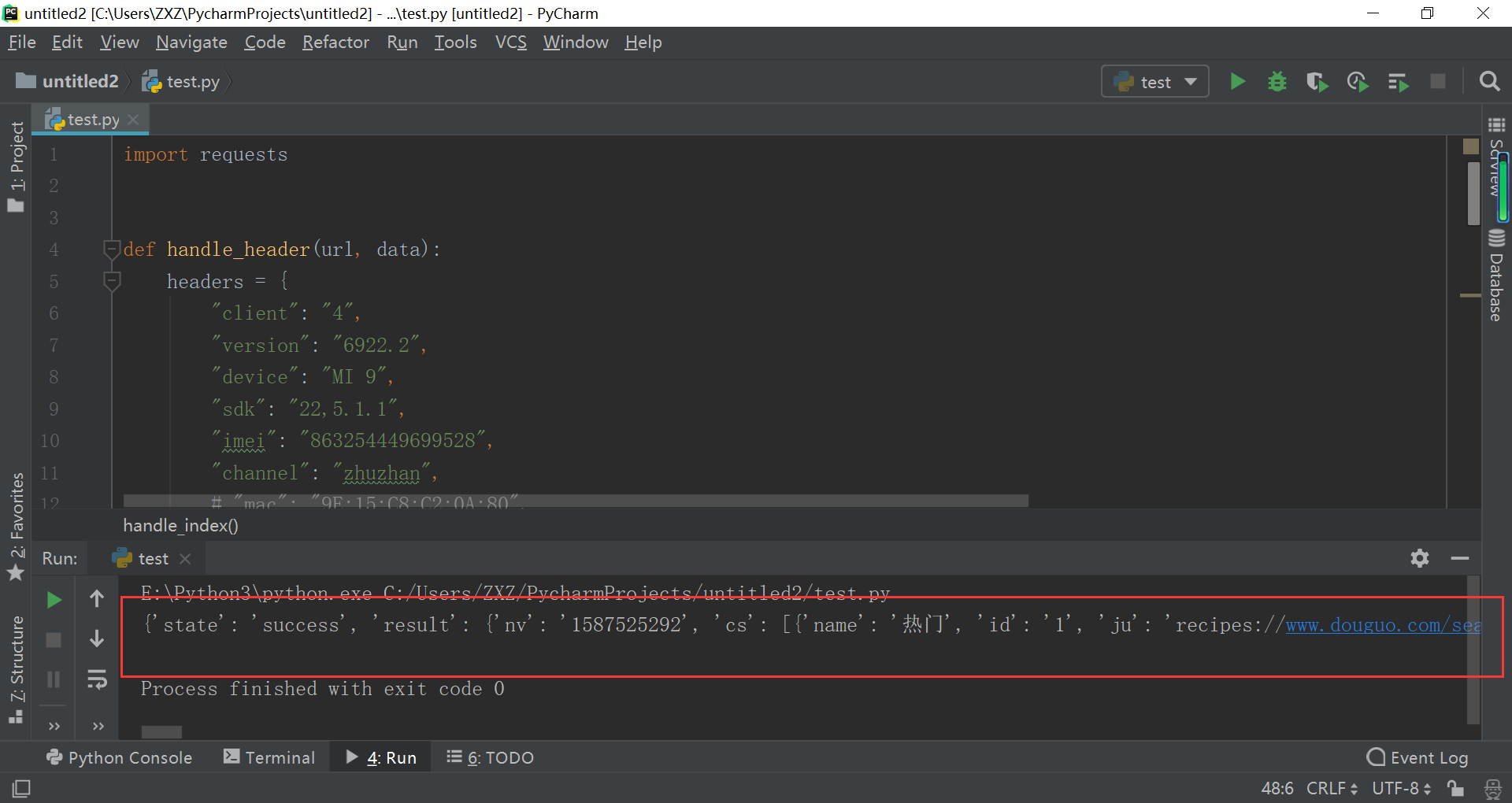
编码


import requests def handle_header(url, data): headers = { "client": "4", "version": "6922.2", "device": "MI 9", "sdk": "22,5.1.1", "imei": "863254449699528", "channel": "zhuzhan", # "mac": "9E:15:C8:C2:0A:80", "resolution": "1600*900", "dpi": "2.0", # "android-id": "701ce79f5ff14457", # "pseudo-id": "79f5ff14457701ce", "brand": "Xiaomi", "scale": "2.0", "timezone": "28800", "language": "zh", "cns": "0", "carrier": "CHINA+MOBILE", # "imsi": "460074457995241", "user-agent": "Mozilla/5.0 (Linux; Android 5.1.1; MI 9 Build/NMF26X; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.136 Mobile Safari/537.36", "reach": "1", "newbie": "1", "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", # "Accept-Encoding": "gzip, deflate", "Connection": "Keep-Alive", # "Cookie": "duid=64130799", "Host": "api.douguo.net", # "Content-Length": "68", } response = requests.post(url=url, headers=headers, data=data) return response def handle_index(): url = 'http://api.douguo.net/recipe/flatcatalogs' data = { "client": "4", # "_session": "1587519801994863254449699528", # "v": "1503650468", "_vs": "2305", } response = handle_header(url, data) print(response.json()) if __name__ == '__main__': handle_index()
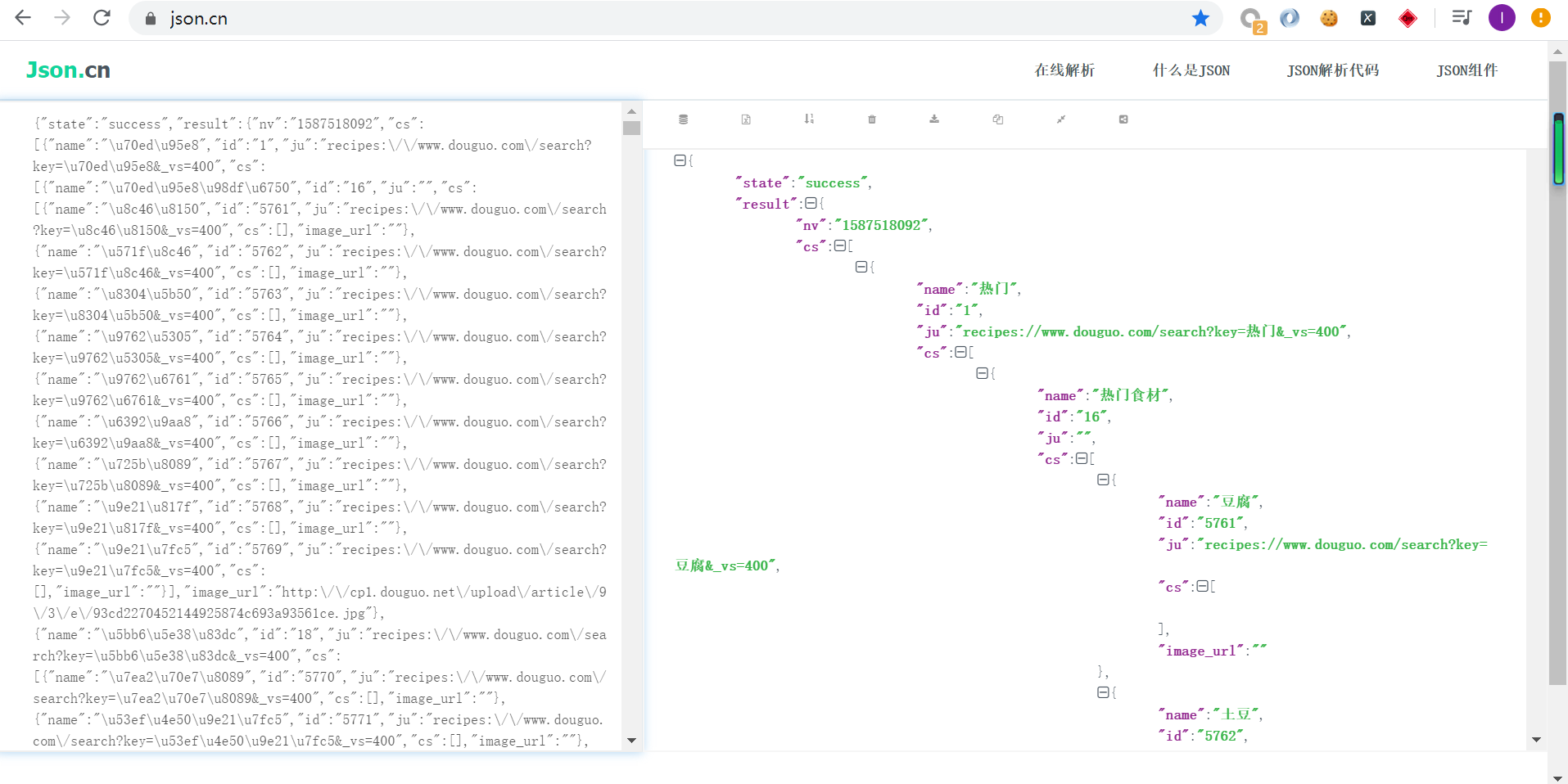
谢谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号