K8S一、理论
Kubernetes的设计架构
Master管理Node,Node管理容器。
Master
Kubernetes集群中的Master节点主要负责管理整个集群,包括集群的健康检查、扩容缩容等。
集群控制节点,所有控制命令都发给Master,Master负责具体的执行过程
- 关键进程:
- API Server:提供HTTP Rest接口的主要组件,是Kubernetes里所有资源的增、删、改、查等操作的唯一入口
- Scheduler:查找尚未绑定到节点的Pod,并将每个Pod分配给合适的节点。
- etcd:保存所有资源对象的数据
- Controller Manager:所有资源对象的自动化控制中心,运行控制器以实现Kubernetes API行为。

Node
除了Master,Kubernetes集群中的其他机器被称为Node
Node主要由3个部分组成,分别是kubelet、kube-proxy和容器运行时(container runtime)。
每个Node都会被Master分配一些工作负载,当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上。
- 关键进程:
- kubelet:确保Pod正在运行,包括其容器。
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制
- Container runtime:负责本节点的容器运行
一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身的情报

Addons
DNS: 用于集群范围的DNS解析。
Web UI(仪表板): 用于通过Web界面进行集群管理。
Container Resource Monitoring: 用于收集和存储容器指标。
Cluster-level Logging: 用于将容器日志保存到中央日志存储区。
组件简的基本交互流程

kubectl命令将转换为对API Server的调用。
API Server验证请求并将其保存到etcd中。
etcd通知API Server。
API Server调用调度器。
调度器决定在哪个节点运行Pod,并将其返回给API Server。
API Server将对应节点保存到etcd中。
etcd通知API Server。
API Server在相应的节点中调用kubelet。
kubelet与容器运行时API发生交互,与容器守护进程通信以创建容器。
kubelet将Pod状态更新到API Server中。
API Server把最新的状态保存到etcd中。
Kubernetes的核心对象

Pod
Pod是由N个容器组成的,每个 Pod 都包含一个特殊的Pause容器
以Pause的状态代表整个容器组的状态
Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume
Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来实现
- 普通pod
- 普通的Pod一旦被创建,就被放入etcd中存储,随后会被Kubernetes Master调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的容器并启动
- 当Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),
- 如果Pod所在的Node宕机,就会将这个Node上的所有Pod重新调度到其他节点上。
- 静态Pod
- 存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动、运行,并且不会被Kubernetes Master管理
在Kubernetes里,一个计算资源进行配额限定时需要设定以下两个参数。
- Requests:该资源的最小申请量,系统必须满足要求。
- Limits:该资源最大允许使用的量,不能被突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes“杀掉”并重启




实现卷共享的最简单的方式就是使两个容器运行在同一个Pod中。这可以确保它们总是运行在同一个节点上,并共享同样的执行环境(包括卷)。
控制组(Control Group, CGroup)用于避免某个容器消耗掉节点上所有可用的CPU、RAM和IOPS。每个容器有其自己的CGroup限额。
通过Pod清单文件部署的Pod是单例的——它没有副本(not replicated),也没有自愈能力(self-healing capabilities)。
正因如此,我们几乎都会基于Deployment和DaemonSet等更高级的对象来部署Pod,因为它们可以在Pod宕掉的时候进行重新调度。
控制器
一般来说,用户不会直接创建Pod,而是创建控制器,让控制器来管理Pod。
控制器中定义了Pod的部署方式,如有多少个副本、需要在哪种Node上运行等。
Replication Controller 和 ReplicaSet
RC可定义Pod模板,并可以设置相应控制参数以实现水平伸缩,以调节正在运行的相同的Pod数。
ReplicaSet逐渐取代RC,但ReplicaSet无法实现滚动更新,无法像RC那样在后端轮流切换到最新版本。
ReplicaSet
● 如果Deployment管理的Pod出现故障,那么它会被替换掉——自愈。
● 如果Deployment管理的Pod承担的负载增加,那么可以轻松地扩展同样的Pod来处理负载——扩容。
-
状态
期望状态是希望达到的状态
当前状态是已经达到的状态
声明式模型用于告诉Kubernetes什么是期望状态 -
命令式和声明式模型
声明式模型只关注最终结果——告诉Kubernetes我们想要的什么。
命令式模型则包含达成最终结果所需的一系列命令——告诉Kubernetes如何来实现,没有声明一个期望状态,因此也就没有自愈功能 -
调谐循环
期望状态能够实现的基础是底层调谐循环
ReplicaSet的底层调谐循环能够定期检查集群中Pod的副本数是否达标。
如果副本数不足,则增加;如果副本数过多,则销毁一些。
滚动升级(rolling update)是指在不停机的情况下,逐步替换旧版本的Pod为新版本。

Kubernetes基于新镜像的Pod创建了一个新的ReplicaSet
一个是包含基于旧版镜像的Pod,一个是新版本的Pod
每次Kubernetes增加新ReplicaSet(新版镜像)中的Pod数量的时候,都会相应地减少旧ReplicaSet(旧版镜像)中的Pod数量。从而,在零宕机的情况下实现了一种平滑的滚动升级。
当使用kubectl apply来执行升级操作时,旧版本的ReplicaSet转为非活跃状态,但它仍存在于集群中,以便执行回滚操作
旧版的ReplicaSet已经暂停并且不再管理任何Pod。然而,仍然保留了所有的配置信息。这使回滚到前一版本成为可能。

Deployment
Deployment控制器以ReplicaSet控制器为基础

一个Deployment对象只能管理一个Pod模板
Deployment使用ReplicaSet来提供自愈和扩缩容能力

Deployment管理ReplicaSet,ReplicaSet管理Pod
StatefulSet
提供了排序和唯一性保证的特殊Pod控制器。
StatefulSet控制器通常与面向数据的应用程序(比如数据库)相关联
分布式存储系统适合使用StatefulSet控制器
Pod转移到其他节点时,StatefulSet控制器会保证Pod的唯一性[稳定的网络标识、持久化存储绑定和有序的生命周期管理。]
当需要重新调度时,可以通过Pod转移持久性数据卷。即使删除了Pod,这些卷也依然存在,以防止数据意外丢失。
Deployment控制器下的每一个Pod都毫无区别地提供服务
StatefulSet控制器下的Pod。虽然各个Pod的定义是一样的,但是因为其数据的不同,所以提供的服务是有差异的。
DaemonSet
DaemonSet控制器是另一种特殊的Pod控制器,它会在集群的各个节点上运行单一的Pod副本。
日志收集和转发、监控以及运行以增加节点本身功能为目的的服务,常设置为DaemonSet控制器
DaemonSet控制器可以越过基于Pod的限制,确保基础服务的运行
Job和CronJob
Job:用于执行一次性任务
CronJob:用于周期性执行任务
服务与存储
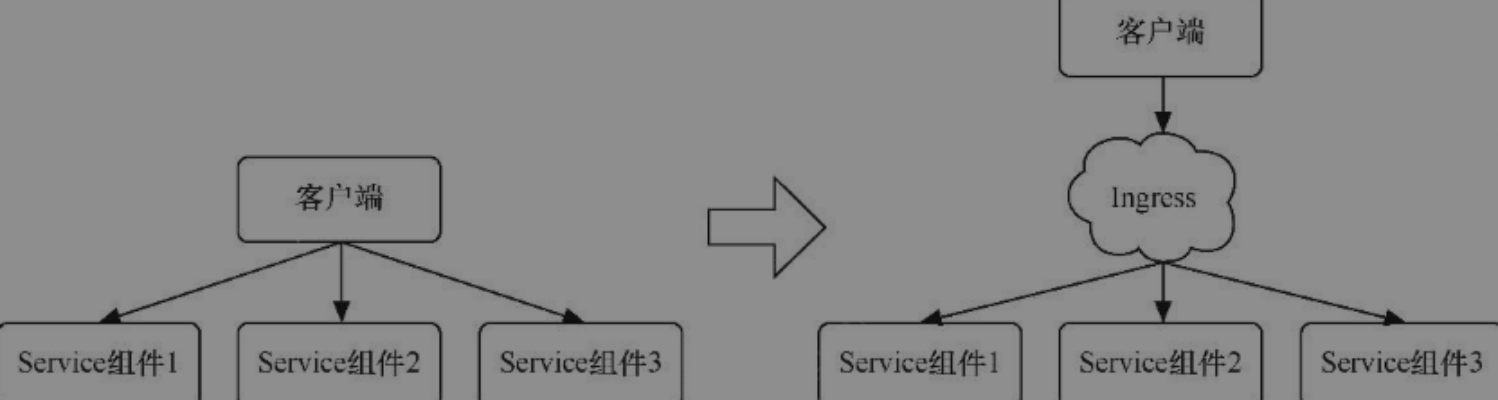
Service组件和Ingress
Pod只是一个运行的应用示例,随时可能在一个节点上停止,并在另一个节点使用新的IP地址启动新的Pod,因此Pod根本无法以固定的IP地址和端口号提供服务。
通过Service组件可以发布服务,可以跟踪并路由到所有指定类型的后端容器。内部使用者只需要知道Service组件提供的稳定端点即可进行访问
Service是内部负载均衡器中的一种组件,会将相同功能的Pod在逻辑上组合到一起,让它们表现得如同一个单一的实体
命令式-->不推荐
声明式
Kubernetes有3个常用的Service类型。
●ClusterIP。这是默认的类型,这种Service面向集群内部有固定的IP地址。但是在集群外是不可访问的。
●NodePort。它在ClusterIP的基础之上增加了一个集群范围的TCP或UDP的端口,从而使Service可以从集群外部访问。
●LoadBalancer。这种Service基于NodePort,并且集成了基于云的负载均衡器。
●ExternalName。将流量直接导入Kubernetes集群外部的服务。
Pod的IP地址是不可靠的。在某个Pod失效之后,它会被一个拥有新的IP的Pod代替。
每一个Service都拥有固定的IP地址、固定的DNS名称,以及固定的端口。
Service利用Label来动态选择将流量转发至哪些Pod。


存储卷和持久卷
允许Pod中的所有容器共享数据

持久性数据可预防节点级的故障
资源划分
命名空间(namespace)的主要作用是对Kubernetes集群资源进行划分。实现多租户的资源隔离。

标签和注解:
标签:键值对
注解:将任意键值信息附加到某一对象中,注解更灵活,可以包含少量结构化数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号