第四篇 文献阅读---基于三维卷积神经网络的时空特征暴力检测
题目:Violence Detection Using Spatiotemporal Features with 3D Convolutional Neural Network

摘要:
智能城市监控摄像头的全球应用使得研究人员能够分析大量数据,以确保自动监控。在智能城市、学校、医院和其他监控领域,必须加强安全系统,以检测暴力或异常活动,避免任何可能造成社会、经济和生态损害的人员伤亡。快速行动的暴力自动检测非常重要,能够有效地帮助相关部门。本文提出了一个三阶段的端到端深度学习暴力检测框架。首先,利用轻量级卷积神经网络(CNN)模型对监控视频流中的人进行检测,以减少和克服无用帧的大量处理。第二,将带有检测到的人的16帧序列传送到3D CNN,在3D CNN中提取这些序列的时空特征并将其馈送到Softmax分类。此外,我们使用Intel开发的开放式视觉推理和神经网络优化工具包对3D CNN模型进行了优化,该工具包将训练后的模型转换为中间表示,并对其进行调整,以在最终平台上实现对暴力活动的最终预测。发现暴力活动后,向最近的警察局或安全部门发出警报,以便迅速采取预防措施。我们发现,我们提出的方法优于现有的最先进的方法。
介绍:
在过去的十年里,随着计算机视觉领域的发展和进步,大量的现代技术因其广泛的监控应用而出现并受到研究者的关注[1-5]。这些措施有助于确保公共场所的安全。为了达到这个目的,世界经济论坛将重点放在使用这些摄像机检测暴力行为上。暴力是一种不正常的行为,是一种涉及到破坏某物、杀死或伤害人或动物的某种体力的活动;这些行为可以通过一个智能监控系统来识别,该系统可用于在发生进一步的致命事故之前防止这些事件的发生。在不同地区,如学校、街道、公园和医疗中心大规模部署的监视系统的主要功能之一是通过提醒当局注意暴力活动,为当局提供便利。然而,人类操作员监控监视的响应速度缓慢,导致人员生命和财产损失;因此,有必要建立自动暴力检测系统[7]。因此,这一领域的研究是在计算机视觉社会中不断增长并获得兴趣的。许多基于深度特征[8-10]和手工制作特征的技术已经出现。
人工特征提取多使用支持向量机。
基于深度学习的视频暴力检测方法是一项具有挑战性的任务,因为视频数据中存在复杂的序列信息模式。Chen等人[18]使用时空兴趣点,包括Harris角点检测器、时空兴趣点(STIP)[19]和运动尺度不变特征变换(Mo-SIFT)[7,20]进行暴力检测。类似地,Lloydetal[21]开发了新的叫做灰度共生纹理度量(GLCM)的描述符(GLCM),其中拥挤纹理的变化通过时间摘要编码,以检测暴力和异常人群。此外,Fu等人[22]开发了一个模型来检测一个明亮的场景,其功能是使用三个属性(包括运动加速度、运动幅度和运动区域)搜索基于运动分析的一系列特征。这些特征统称为运动信号,由运动区域求和得到。同样,Sudhakaran等人[23]提出了一种方法,通过对视频中发生的变化进行编码,将长时短时间内存(LSTM)和长时帧作为不同的输入输入到模型中。Mahmoodi等人[24]使用光流大小和方向(HOMO)直方图进行暴力检测。最近,Fenil等人提出了一个暴力行为识别框架[25],他们从每一帧中提取出方向梯度(HoG)特征的直方图。这些特性被用来训练双向长短期存储器(BD-LSTM),并确保其用于前后信息存取。此生成的输出包含有关暴力场景的信息。
上述方法试图解决暴力检测中的许多挑战,包括摄像机视图、复杂的人群模式和强度变化。例如,在检测暴力行为时,当人体发生变化时,他们无法通过提取特征来捕捉歧视性和有效性特征。这些变化是由视点、显著的相互遮挡和比例引起的[26]。接下来,[14]当仅考虑波动率时,该方法遇到一个问题:如果两个连续帧中一个像素的波动矢量具有相同的大小和不同的方向,则波动率的影响受到限制,因为波动率检测不到这两个波动矢量之间的差异。此外,早期的暴力检测方法使用火焰、爆炸和血液;这些方法由于检测率低而受到限制,并可能产生假警报。此外,基于HHMM的方法[12]和HOMO[24]无法识别复杂的人群行为。
近年来,卷积神经网络(CNNs)在行为识别和安全性[10,27,28]、目标跟踪和活动识别[29,30]、视频摘要[31]和灾难管理[8]等多种计算机视觉技术中得到了更高的精度和更好的结果。基于CNNs在上述领域的表现,我们提出了基于3D-CNN的暴力监控检测方法。拟议方法的主要贡献总结如下:
1、视频数据中的暴力检测是一个具有挑战性的问题,因为复杂的序列视觉模式识别。主流技术采用传统的低层特征来完成这一任务,这些特征在识别复杂模式方面效率不高,在实时监控中也很难实现。考虑到现有技术的局限性,我们提出了一种基于深度学习的3D-CNN模型来学习复杂的序列模式来准确预测暴力。
2、大多数暴力检测算法都无法处理大量不重要的帧,这会占用更多的内存,而且非常耗时。考虑到这一主要限制,我们首先使用预先训练的MobileNet CNN模型检测视频流中的人。只有包含人的16帧序列被传递到3D CNN模型进行最终预测,这有助于实现高效的处理。
3、由于暴力检测基准数据集缺乏数据,且准确率通常较低,当前主流方法无法学习有效模式。在转移学习概念的启发下,3D-CNN使用可公开获取的基准数据集对室内和室外监控中的暴力检测进行了精确调整。通过提高准确率,它在实验上优于传统的手工特征提取算法。
4、在获得深度学习训练模型后,使用OPENVINO工具包进行优化,以加快并改善其在模型部署阶段的性能。利用该策略,将训练后的模型转化为基于训练权值和拓扑结构的中间表示(IR)。
方法:
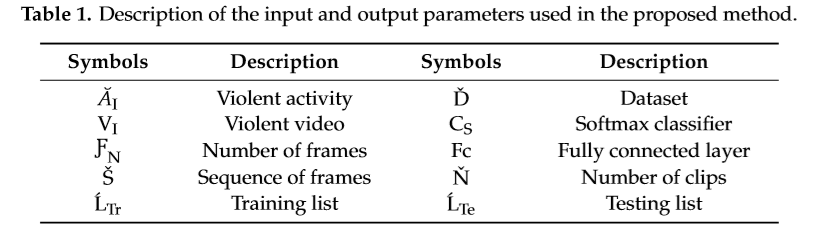
在本节中,我们将详细讨论我们提出的方法,其中使用端到端深度学习框架检测暴力活动。首先,摄像机捕捉视频流VI,该视频流直接被认为是rainedmobilenetcnnmodel来检测用户。当检测到personinthevideo流时,将16帧的序列sh传递给3D-CNN模型进行时空特征提取。这些特性被输入到Softmax分类器,以便最后分析活动特性并给出预测。当发现暴力事件并立即采取相应措施时,会向最近的安全部门发出警报。建议方法将在小节中进一步详细讨论,每个步骤如图1所示。表1用符号描述了e输入和输出参数。
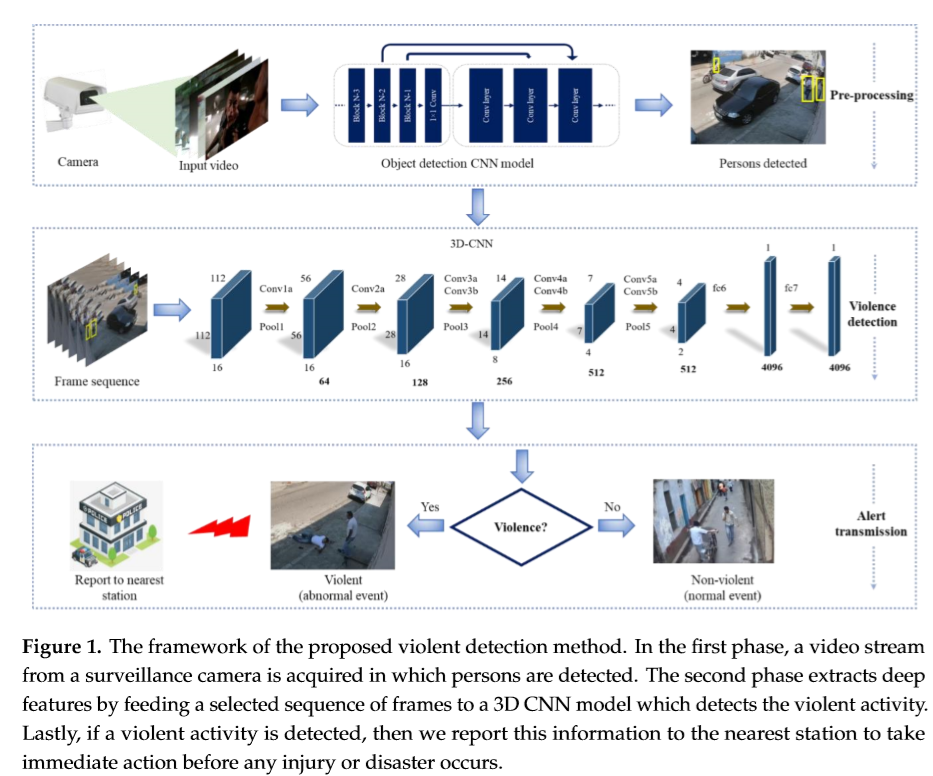
预处理:
在我们提出的方法中,人的检测是一个重要步骤,以确保在暴力检测步骤之前进行高效的处理。在本节中,我们将检测视频流中的人员以进行高效处理。我们不处理整个视频流,而是通过避免不重要的帧来处理那些包含人的序列。视频流被送入MobileNet SSD CNN模型[32]中进行人的检测。我们使用这种CNN架构是因为它可以帮助系统限制延迟和大小。MobileNet具有可分离的深度卷积来检测目标,而不是常规卷积。如果将深度卷积和点方向卷积分开计算,则共有28层,除最后的完全连接层外,每层后面都跟着非线性批范数和ReLU。第一卷积层包含两个跨距,滤波器形状为3×3×3×32,输入尺寸为224×224×3;其下一个纵深卷积有一个跨距,滤波器形状为3×3×32,输入尺寸为112×112×32。MobileNet主要用于分类,而其固态硬盘版本则用于定位多盒探测器及其组合执行目标检测。为此,网络执行前向卷积并生成固定大小的边界框组,通过提取特征映射并应用卷积滤波器来确保这些框中对象实例的存在和检测。

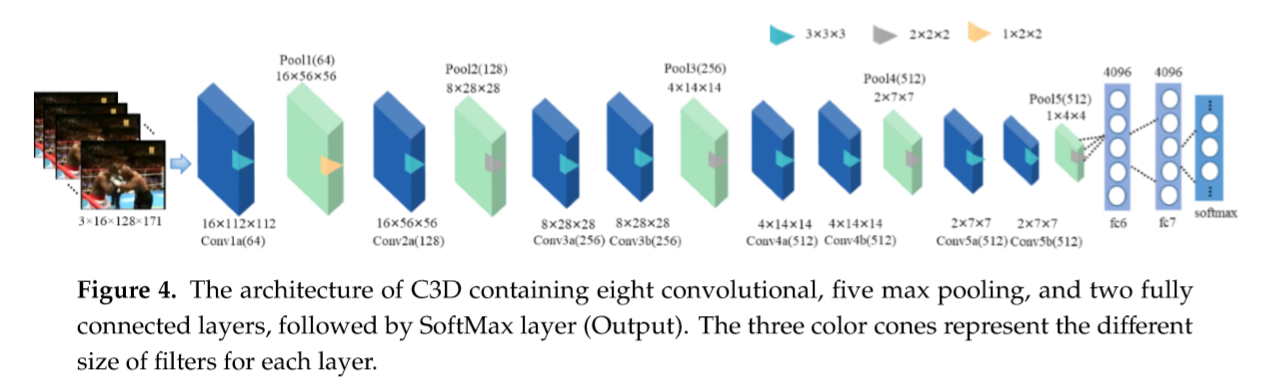
3D-CNN
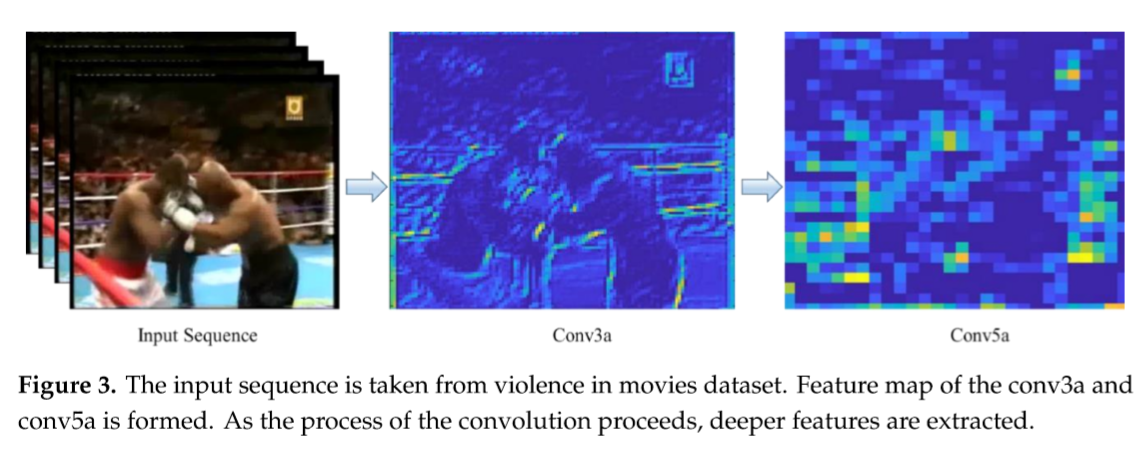
3D-CNN由于其三维卷积和池运算,非常适合于提取时空特征,能够更好地保存时间信息。此外,在2D CNN中,只有空间信息,而3D CNN可以捕获关于输入序列的所有时间信息。现有的一些方法是利用二维特征提取视频数据中的空间相关性,后者具有时间相关性。例如,在[33,34]中,2D CNN处理多个折射,并且所有的时间特性信息被合并。三维卷积通过在通过装配附加帧而设计的立方体上卷积一个三维遮罩来操作。从卷积层获得的特征映射被链接到前一层的多个附加帧,捕获运动信息。
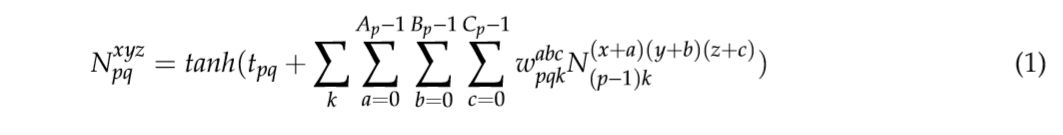
结果:
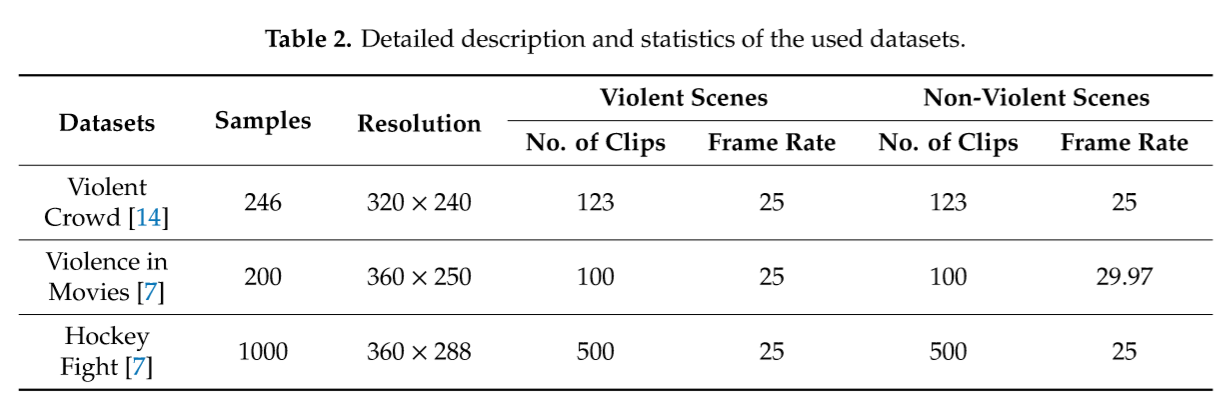
violent crowd [14], hockey fight [7], and violence in movies[7]
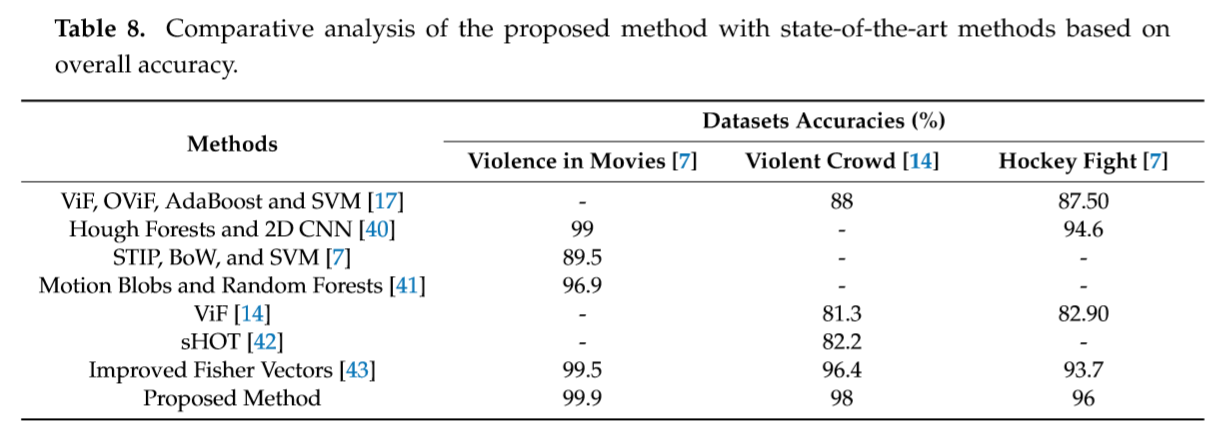
本文提出了一种三阶段端到端的视频监控流暴力检测框架。在第一阶段,使用一个有效的CNN模型来检测人,以去除不需要的帧,从而减少整体处理时间。接下来,将带有人的帧序列输入到在三个基准数据集上训练的3D CNN模型中,在该模型中提取时空特征并转发给Softmax分类器进行最终预测。最后,使用OPENVINO工具包对模型进行优化,提高了模型在终端平台上的运行速度和性能。在不同基准数据集上的实验结果证明,我们的方法是监测中暴力检测的最佳方法,并且比几种使用的技术获得了更好的准确性。在未来,我们打算确保我们的系统在资源受限的设备上实现。此外,我们计划使用智能设备快速响应,为物联网中的暴力识别工作提出边缘智能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号