第三篇 阅读文献---非平稳环境的实时动作识别
题目:

创新点:
1、非稳定监控的线上数据流动作识别
2、用于帧级表示的有效CNN模型
3、为学习序列和压缩高维特征提出了一个优化的深度自动编码
4、研究了非线性的动作识别学习方法
5、为新的积累数据迭代微调已经训练好的识别模型
摘要:
动作识别是一个极具挑战性的研究领域,目前已经提出了几种基于卷积神经网络(CNN)的动作识别方法,但这种方法在处理具有满意精度的实时在线数据时效率不高。本文提出了一种高效、优化的基于CNN的非平稳监视环境视觉传感器数据流实时处理系统。首先,利用一个预训练的CNN模型提取帧级深度特征。然后,引入一个优化的deep autoencoder(DAE)算法,对监控流中的行为进行学习时间变换,并训练一个线性学习方法,对人类行为进行分类。最后,在测试阶段添加一个迭代微调过程,该过程可以更新非静态环境中累积的数据的训练模型参数。实验在benchmark数据集上进行,结果显示在精度和运行时间方面,在当前的方法中我们的系统的性能更好,我们认为我们的系统是一个适合于非平稳环境下监视数据流中的行为识别的候选系统。
介绍:
非稳定数据流当遇到变化的新数据时,训练模型无法以以前的经验充分考虑数据的影响。因此,它对非稳定环境的适应性需要通过数据的多样性来提高,有人认为这是一个优化问题,可以通过生物启发算法来验证漂移的异质性,并通过自学习优化技术实现高多样性。另一种新方法改进了加权一类支持向量机,并将其用于非平稳流数据分析。Abdallah等人介绍了在线数据流挖掘中的数据详细调查和可视化识别此外,由于计算高维特征、视点变化、运动、杂乱背景、遮挡和不同照明条件,从在线监视数据流中实时准确识别人类行为是一项极具挑战性的任务。
为了解决这些问题,自过去十年以来,在识别人类行为的领域中使用了许多手工制作的局部特征描述符,其中,空间-时间的概率近似值提供了运动信息分析方案,并且可以改进Bag-of-Words(BoW)的性能,但是计算成本较高。Dalal等人提出了运动边界直方图(MBH),其中边缘运动被捕获在HOG描述子中分别计算了光流水平分量和垂直分量的局部梯度两个分量中对应的大小和方向用作局部方向直方图的加权投票。Klaser等人提出了HOG3D特征描述子的扩展形式。其中,从积分视频表示计算出的三维梯度方向被绑定到多面体中,以分析外观和运动信息。此方案由于高维结构而增加了量化成本。另外有梯度边界直方图(GBH)使用图像梯度的时间导数而不是简单的梯度来突出移动边缘边界。Klaseretal[26]提出了光流共现矩阵(OFCM)来提取一组利用光流的大小和方向捕获的统计度量设计OFCM的关键动机是假设空间关系可以在流场的局部邻域中建立,而流场在呈现运动中起着主要的作用。
手工特征提取机制涉及硬件工程,为表示视觉数据的低级语义需要进行复杂的提取和分类。因此,自动特征学习方法是研究者们更青睐的方法。例如,基于神经网络的方法可以根据训练后的权值和偏差直接从原始输入中提取特征,用CNN以分层的方式学习特征,初始层从视觉数据中获取局部特征,最终层提取代表高级语义的全局特征。近年来,研究者们试图开发出一种用于动作识别序列学习的CNN体系结构。例如,Karpathyetal提出了一个基于时空信息的CNN框架来获取运动特征,分析了几种将局部运动方向与全局特征融合的时空信息融合方案,但在UCF 101数据集上的识别率为63.3%表明他们的CNN架构无法有效地表示视频流中的人类行为。在另一部作品中,Park等人使用空间网络提取图像特定部分的运动信息,该捕捉器将激活光流的量级信息的特征利用计算机光流强度分析了空间网络区域最后一个卷积层的特征图。Simonyan和Zisserman[31]提出的另一个类似的工作是基于双流网络的方法。.第一流为空间网络,帧序列中提取的时间信息在第二个流中,利用时间网络来计算多个帧之间的光流信息。最后,使用两个流的平均得分进行预测。大多数深度CNN框架都是用于没有时间信息的2D图像。Jietal[32]演示了用于端到端动作识别的3d CNN他们的模型从空间和时间两个维度提取特征,从多个相邻帧中获取运动信息,该方法是基于对视频帧中的人体连续片段的分析。
基于深度CNN的方法可以学习有影响力的权重,以区分视觉数据中存在的不同动作。动作识别的模型并不是在像ImageNet这样的大规模数据集上训练的。许多研究[6,27,34]已经得出结论,激活预先训练的CNN模型在图像检索、火灾探测和视频摘要方面取得了令人印象深刻的成功。因此,我们对各种预训练cnn models的深度特征进行了广泛的研究,现有的CNN模型在计算成本很高,并且它们的识别精度并不能男足所有环境的要求。因此,我们将通过以下关键贡献来解决这些问题:
一、我们提出了一个有效的优化动作识别系统来处理从非平稳环境视觉监控中获得的数据流,我们的系统使用预先训练的VGG16 CNN模型的完全连接层的激活来表示动作的视频流
二、动作是连续帧中运动的序列,帧级特征是高维特征的原始数据,用于精确识别动作。因此,我们训练了一个优化的DAE(deep autoencoder)来压缩这些特征,并使其能够在低维特征平面中关联帧到帧的隐藏变化以便我们的系统能够有效地顺序学习动作识别,而不是使用复杂的学习方法,如长期短期记忆(LSTM)。
三、我们研究了一种非线性学习方法,并训练了一个从低维特征平面进行认知的非平稳环境下识别系统。
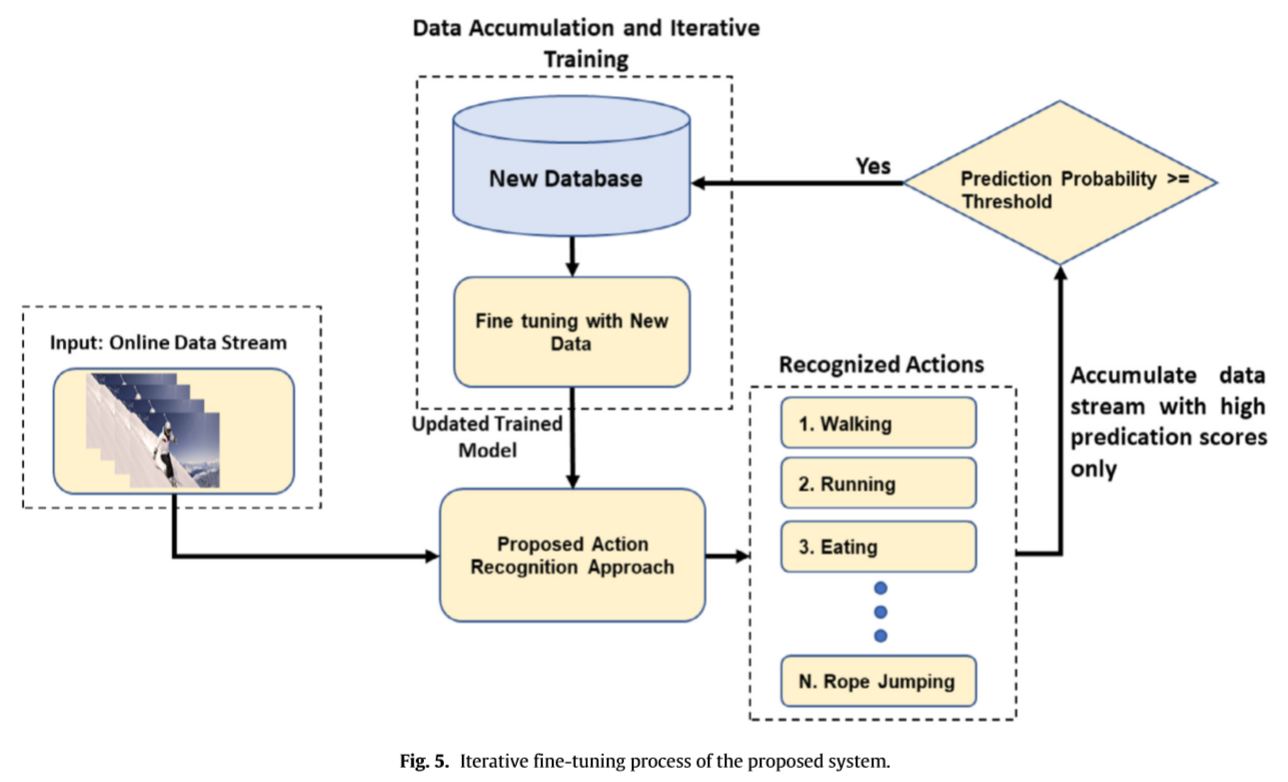
四、非平稳环境下的视频数据由于时间的变化而具有多样性,一次训练的模型不足以进行精确的预测,因此,我们介绍了迭代微调模块用于收集动作的高置信度预测新数据,并用这些数据迭代微调识别模型。这个过程使我们的系统能够根据底层非静态环境中的评估更新自己。
五、我们的系统从不同的角度在基准数据集上进行了测试,与最新技术相比,结果令人鼓舞,从而使其适用于一般的实时监控和特殊的非平稳环境的数据流。
设计框架:
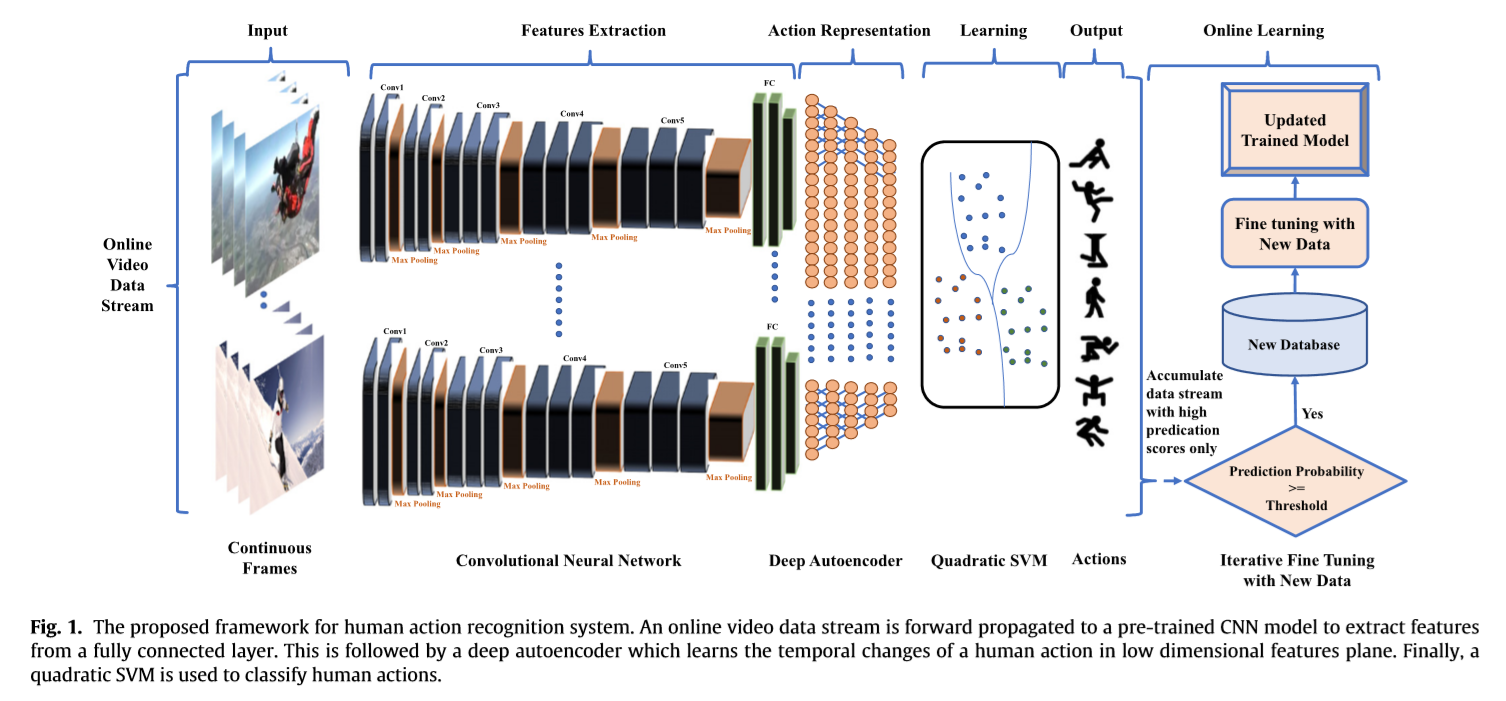
在这一部分中,详细讨论了所提出系统的机制该系统包括使用深度CNN特征的在线视频数据流中的动作表示,序列使用DAE进行学习,并使用二次支持向量机进行动作分类。首先,利用预先训练好的VGG-16cnn模型从在线数据流的选定帧中提取深度特征其次,对高维特性进行了跟踪,并在高维特性平面图上进行了学习,实现了特征间的时间转换,最后,利用二次SVM对在线视频流处理时长的压缩特征进行了分类。此外,我们用不同动作的高置信度分数来累积数据流,并用新的数据迭代微调我们的识别模型,以采用非平稳环境的变化。所提出的框架如图1所示,而每个系统都有不同的动作描述和实现步骤。
深度特征提取和预处理:FC8取特征图接入二次支持向量机
视频数据包含大量隐藏的视觉内容,包括纹理、运动、边缘和颜色的时间变化。使用预先训练好的CNN模型,它们的参数是在诸如ImageNet[38]这样的巨大数据集上训练的。在所提出的系统中,使用预先训练的VGG-16[39]CNN模型的完全连接的“FC8”层从视频帧中提取特征完全连接层,从图像中提取通用全局描述符[34]。因此,我们认为这些特征具有很强的主导性,并且能够表示视频内容,这有助于我们学习视频帧中的复杂序列预训练cnnmodel的帧特征之间的时间顺序,其中视频数据包含一系列帧,我们已经将15帧输入到所采用的CNN模型中,该模型从具有一帧跳跃的在线视频数据流中提取1秒,它给出了一个高维特征向量,表示原始形式的人类行为。这些特征之间的时间顺序是通过一个有效的DAE来确定的,并使用二次支持向量机来进行人类动作识别。
VGG-16 CNN模型:没有多余的池化层 省参数

VGG-16的结构是表1。VGG-16的结构不同于先前的最先进的CNN模型[40-43],后者的初始层以4到5步的速度与11×11或7×7的核进行转换这种设置增加了CNN模型中的参数数量。此外,如果步幅较大,它可能会丢失图像中的重要图案另一方面,VGG-16包含所有卷积层的3×3核,每个卷积层有1个网格,这有助于减少层的参数数量,并将每个像素卷积到1个网格,从表1可以看出,两个连续的3×3卷积层之间没有池层这种7×7核的两层结果效应的组合。组合连续的三个卷积层之后是一个“relu”激活,多个非线性函数使他变得更加有判断力。
深度自编码DAE:
四层自编码器:
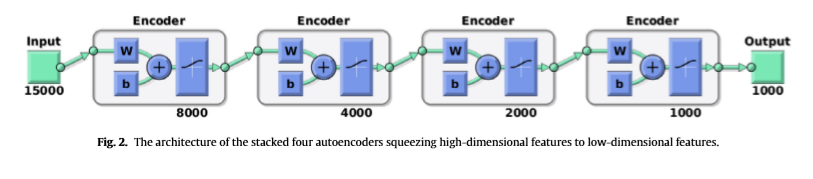
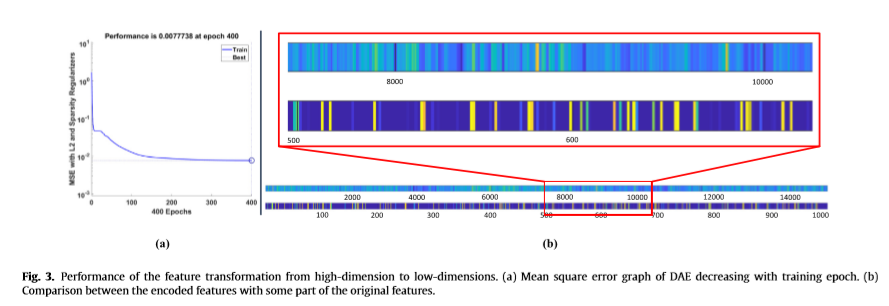
深度自编码是一种有效的多隐藏层无监督特征表示技术。隐藏层的参数不是人工构造的[44,45],而是根据给定的数据自动学习的。使用DAE可以实现视频数据处理的实时性。高维深特征在变换过程中被压缩到低维,误差可以忽略。从帧序列中提取深度特征,并使用四层叠加自动编码器的有效架构学习其隐藏模式和帧间变化。第一层将15000维特征向量编码为8000个神经元,然后分别跟踪4000, 2000个和1000个维度,减少半因子的高维数据是为了减少自动编码器的时间复杂度。用小步长和多个深层压缩高维数据会导致高的计算复杂度。DAE在输入数据[46]中学习“分层分组”或“部分-整体分解”堆叠的自动编码器一阶特征的初始层并在原始输入数据中更改,同时中间层学习与一阶特征中的模式相对应的二阶特征。因此,我们认为提出的DAE能够有效地学习视频序列中人类行为的变化和类别。
自编码公式:??普通神经网络?

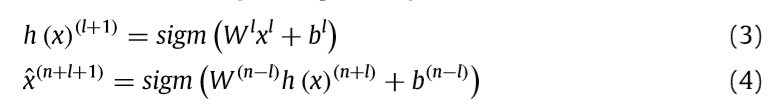
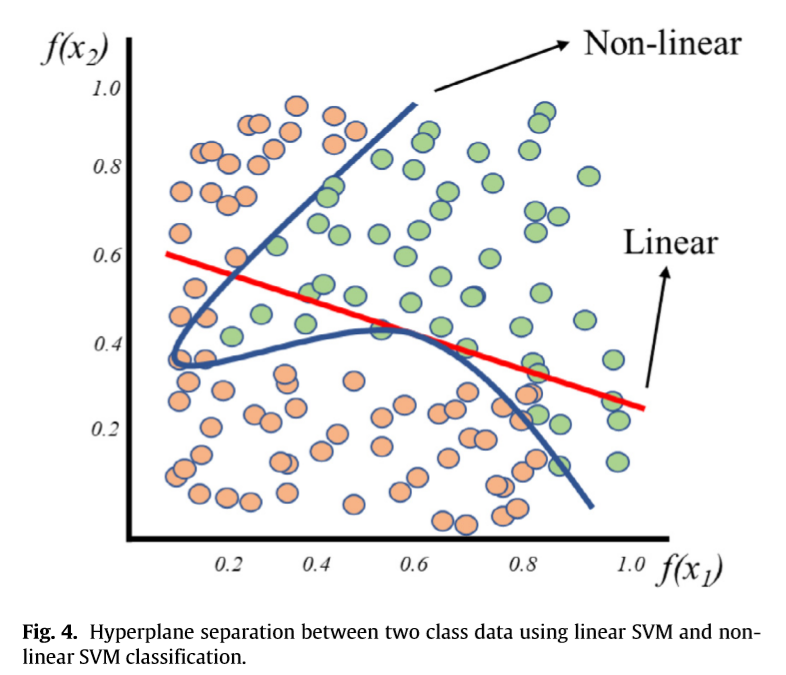
二次支持向量机学习动作:非线性分类(没啥意思)
数据流增量模型训练:
实验评估:数据集包括UCF101[29]、UCF50[58]、YouTube Actions[59]和HMDB51[60]。
原文:https://www.sciencedirect.com/science/article/pii/S0167739X18318533?via%3Dihub
总结:
1、VGG模型可以改进,使用轻量级网络替换
2、支持向量机计算量过大 分类环节可以替换
3、网络微调?迁移学习?没太看懂
(· 。· 不知道为什么会是2019年的论文)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号