第二篇 文献阅读---电影场景分割
题目:Movie scene segmentation using object detection and set theory

链接:https://journals.sagepub.com/doi/10.1177/1550147719845277
摘要:
电影数据在网络多媒体数据的指数增长中有着突出的作用,其分析已经成为计算机视觉领域的一个热点问题。电影分析的第一步是场景分割本文通过一种新的基于三步结构的智能卷积神经网络(CNN)来研究这一问题。
第一步将输入的电影分割成镜头,第二步检测分割镜头中的对象,第三步执行基于对象的镜头匹配以检测场景边界融合纹理和形状特征进行镜头分割。
每个镜头由一组从轻质CNN模型中提取的检测对象表示最后,我们将集合论和基于滑动窗口的方法相结合来整合相同的镜头以确定场景边界实验评估表明,我们提出的方法超越了现有的电影场景分割方法。
介绍:
镜头是电影的基本组成部分然而,一个镜头不足以传递任何语义另一方面,场景由一个或多个连续镜头组成,这些镜头在语义上相互关联,共享相同的物理设置,或呈现由演员执行的连续动作因此,用户更可能回忆一个场景而不是一个镜头,因为它涵盖了电影中的整个事件或子故事。场景分割在电影数据分析中起着至关重要的作用,它有大量的应用,如摘要、索引和检索、字幕对齐、字符识别。现有的基于特征提取的场景分割方法可分为三大类:(1)基于视觉的方法;(2)基于音频的方法;(3)混合场景分割方法。
基于镜头的关键帧选择是在现有文献中发现的主要限制之一,因为通过一个关键帧呈现一个镜头会导致缺少大量的长镜头信息,因此这种方案需要一个特殊的关键帧选择模块,同时这些方案的第二个主要问题是基于低层特征的镜头相似度测量。因为单个场景的镜头在语义上是相关的,通过低层特征来表示语义是非常困难的。为了解决这些问题,我们提出了一种基于对象在每个镜头中的外观将电影分割成场景的方案。首先,使用纹理和颜色特征将电影分割成镜头,然后使用YOLOv325卷积神经网络(CNN)模型检测每个镜头中的对象,该模型在具有80类日常生活对象的上下文(COCO)数据集26中对常见对象进行训练最后,我们提出一种新的基于集合论的镜头匹配机制来侦测场景边界。本文的主要贡献概括如下:
1 在电影中,使用多个摄像机从不同角度捕捉场景,最后合并每个角度的镜头以呈现场景我们融合了纹理和颜色特征来有效地检测这些镜头
2 现有技术依赖于单个或两个关键帧来表示镜头,从而导致信息丢失。此外,这些技术还需要额外的关键帧提取模块相比之下,我们通过一组出现在同一个镜头中的检测对象来表示一个镜头我们的策略是通过检测所有帧中的对象来覆盖镜头的最大信息。
3 镜头相似度是场景分割技术中的一个关键步骤,通常通过特征匹配来实现,这需要大量的处理时间因此,提出了一种新的基于集合论的镜头匹配方法,与基于特征的匹配方法相比,该方法具有较高的计算效率。
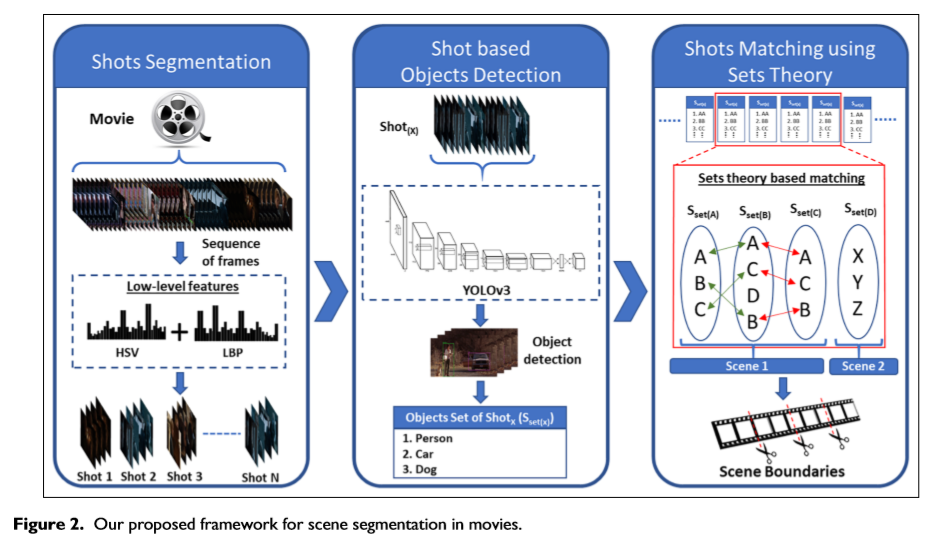
本文设计的镜头分割框架
第一部分 镜头分割
镜头分割电影的层次结构有助于将电影分解成短片段,从而使高层次的视频分割和电影分析更加有效。利用这个优势,我们首先将整部电影分割成镜头低层特征,如颜色直方图、局部二值模式(LBPs)和梯度直方图(HoG),在逐帧比较时显示出更好的镜头分割性能受基于直方图的方法的启发,我们使用HSV颜色空间作为颜色直方图,使用LBP作为纹理特征来计算两个连续帧之间的相似度单帧由大小为360的特征向量FV表示,该特征向量FV连接70个像素的颜色直方图,该直方图是在HSV颜色模型中使用颜色量化和290个纹理特征来实现的对于纹理特征,首先从一帧图像中提取LBP模式,其中我们只选择了58个均匀的模式,然后应用5个23 2的角度结构对这些模式进行分析最后,得到大小为5X58=290的纹理特征向量,使用公式(1)和(2)计算了两个连续帧之间的相似度S。其中S(i,j)分别是第i帧和第j帧的特征向量FVi和FVj之间的相似度得分如果第i帧和第j帧之间计算出的相似度得分大于预定阈值,则第j帧被视为与上一个镜头相关;否则,视为启动新的镜头经过大量的实验,我们把阈值设为0.9。

相似度计算公式
第二部分 基于镜头的目标检测
深度学习与高计算能力的结合使机器能够成功解决目标检测、分类以及其他一些与图像和视频实时相关的问题。我们将深度学习应用于电影场景分割领域,以检测镜头中的各种对象。在目标检测方面,我们使用了在COCO数据集上训练的带有DarkNet后端框架的YOLOv3-CNN25模型。由于该模型能够通过使用一个神经网络同时遇到多个区域来识别单个图像中的多个目标,因此适合我们的问题。COCO数据集中包含的对象被分为80个类,可以很好地用于电影中基于对象的镜头分割这些对象包括行人、车辆、招牌以及在电影数据中起着重要作用的许多其他室内和室外对象。在YOLOv3中,目标检测问题被看作是一个回归问题,它同时在一个视图中对多个类进行预测它还根据类的外观对类的上下文信息进行编码,这使得它适用于我们的问题。YOLOv3的架构在53个卷积层的序列中使用333和131大小的连续卷积滤波器,每一层之后是一个非线性激活函数称为漏校正(Leaky Rectified)和一个232大小的maxpooling层,步长为2。YOLVO3在时间复杂度和准确度方面比以前版本有显著的益处,并且它可以处理78个FPS而不需要批量处理。图3显示了使用YOLOv3检测到对象的测试电影 中的一些示例帧大多数场景分割方案选择一个关键帧或第一帧和最后一帧来表示镜头的整个帧序列,这样的方案在镜头较长时忽略了很多有用的信息在我们的方案中,我们检测所有镜头帧中的对象,以确保没有任何信息丢失然后,使用方程(3)和(4)将每个镜头中检测到的对象的并集与关注镜头相关联。


第三部分 基于集合论和滑动窗口方法的场景边界检测
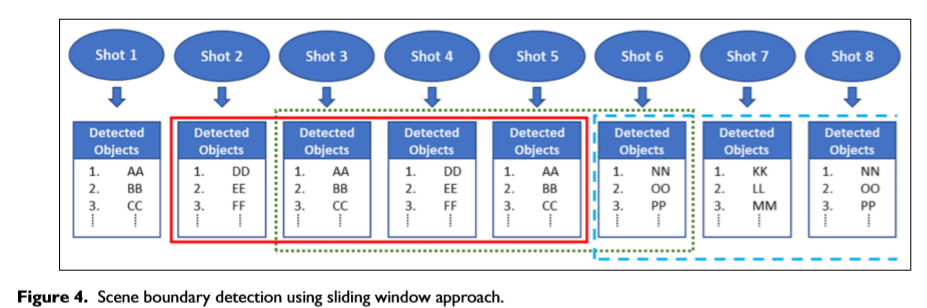
如引言所述,场景是一组连续的镜头,它们在语义上相互关联,在时间和空间上具有相似的连贯性以呈现整个事件。低层特征可以提供镜头间关联的一些有用信息,但它们无法描述镜头间的语义关联。因此,在所提出的方案中,我们利用集合论有效地利用镜头的内容来度量相似度。
图4给出了一个例子来解释所提出的镜头匹配机制的概念在前面的步骤中,每个镜头都表示为一组检测到的对象,如图4所示拍摄一个四个镜头的窗口来确定镜头之间的相似性。假设第2、3、4和5组快照位于红色窗口中然后,我们假设镜头2、3和4属于同一场景,为了检查镜头5,我们将其与窗口中的其他镜头集进行比较比较以集合论为基础,集合5与集合2、3、4分别求交如果交集元素的数量大于或等于集合2、3或4的任何元素总数,则该快照将被视为上一个正在运行的场景的一部分,并且窗口将移动到下一个快照,如用绿色窗口高亮显示的那样现在,集合6与绿色窗口中其他集合的交集给出了一个空集合,这意味着这些快照有零个共同元素因此,将启动一个新场景,并且窗口将从集合6(蓝色窗口)开始。
算法1给出了总体机制。

4、实验评估:

表2是拟议方案的总体执行情况电影NH的结果更低,因为在这部电影中,大多数镜头都是演员面部的特写镜头,因此在大多数镜头中,只检测到一个类。
场景变化检测大多数研究者用来评估场景变化准确性的常用指标是精确性(P)、召回率(R)和F-测度(F)我们使用方程(5)–(7)评估场景变化的准确性:
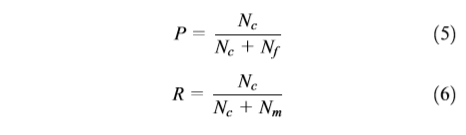

其中Nc是正确检测到的场景边界数,Nm是丢失的场景边界数,Nf是错误检测到的场景边界数。
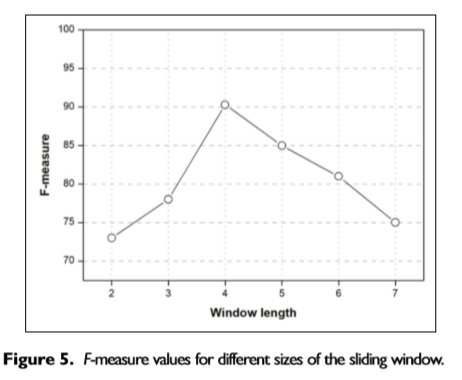
窗口大小选择曲线:
场景边界缺失原因:
在我们的方法中,场景边界的缺失是由两种类型的错误造成的第一种是相同对象在两个相邻场景中的外观例如,电影中几乎95%的镜头都必须包含一个演员,在我们提出的方案中,演员被预测为人物类因此,所有镜头中的共同目标检测都会导致对场景边界的漏检这些场景的例子可以在电影NH中找到,如图6(a)所示这种类型的错误很难使用视觉提示恢复,而不会导致许多错误检测第二个未检测到场景边界的原因是两个镜头之间的渐变尽管如此,电影中镜头之间的渐变很少,而且大多数都是在场景变化之间进行的一种稳健的镜头切换检测方案可以恢复这种错误图6(b)显示了两个场景之间的渐变。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号