
jedis keys和scan操作
关于redis的keys命令的性能问题
KEYS pattern
查找所有符合给定模式 pattern 的 key 。
KEYS * 匹配数据库中所有 key 。KEYS h?llo 匹配 hello , hallo 和 hxllo 等。KEYS h*llo 匹配 hllo 和 heeeeello 等。KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 。特殊符号用 \ 隔开
NOTICE: KEYS 的速度非常快,但在一个大的数据库中使用它仍然可能造成性能问题,如果你需要从一个数据集中查找特定的 key ,你最好还是用 Redis 的集合结构(set)来代替。
Keys模糊匹配,请大家在实际运用的时候忽略掉。因为Keys会引发Redis锁,并且增加Redis的CPU占用,情况是很恶劣的
实际应用中有时候会出现需要遍历redis中的所有键值的需求,比如清理没用的键等等。但是keys这个命令性能真的很差,redis官方文档是这么说的:
Warning: consider KEYS as a command that should only be used in production environments with extreme care. It may ruin performance when it is executed against large databases. This command is intended for debugging and special operations, such as changing your keyspace layout. Don’t use KEYS in your regular application code. If you’re looking for a way to find keys in a subset of your keyspace, consider using SCAN or sets.
由于执行keys命令,redis会锁定,如果数据庞大的话可能需要几秒或更长,对于生产服务器上锁定几秒这绝对是灾难了
如果有这种需求的话可以自己对键值做索引,比如把各种键值存到不同的set里面,分类建立索引,这样就可以很快的得到数据,但是这样也存在一个明显的缺点,就是浪费宝贵的空间,要知道这可是内存空间啊,所以还是要合理考虑,当然也可以想办法,比如对于有规律的键值,可以存储他们的始末值等等。
使用redis的时候要注意很多细节,当时的leader说过一句话很受启发,虽然redis只提供了五种类型,但是用起来不一定就只有五种,比如string类型,你可以存储任何你自己定义的类型,所以思想不能局限,灵活的设定数据结构。还有就是虽然redis存取很快,但是正常生产环境,redis服务器肯定和web服务器不是在一起,有时候甚至是在不同的地区,所以网络通信延迟就很重要了,所以要减少存取次数,一次存取完成更多的工作,否则你会发现做同样的事redis还没有关系型数据库快,所以redis存的时候一定要有技巧,尽可能减少存取次数。
从redis的官方文档上看,2.8版本之后SCAN命令已经可用,允许使用游标从keyspace中检索键。对比KEYS命令,虽然SCAN无法一次性返回所有匹配结果,但是却规避了阻塞系统这个高风险,从而也让一些操作可以放在主节点上执行。
需要注意的是,SCAN 命令是一个基于游标的迭代器。SCAN 命令每次被调用之后, 都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。同时,使用SCAN,用户还可以使用keyname模式和count选项对命令进行调整。SCAN相关命令还包括SSCAN 命令、HSCAN 命令和 ZSCAN 命令,分别用于集合、哈希键及有续集等。
另一方面,使用redis的时候一定要注意控制key,对于key的命令要制定一个完善的方案,这样才能对redis里面的数据可控,避免出现没用数据长时间占据数据库这种情况,也可以避免上面说的这种查询键值的操作。
Scan操作
ScanOptions options = ScanOptions.scanOptions().match(workQKey).count(Integer.MAX_VALUE).build(); Cursor c = redisConnection.scan(options); while (c.hasNext()) { logger.info(new String((byte[]) c.next())); }
测试了一番,和keys的效果是一致的。but,count的参数为什么是Integer.MAX_VALUE呢?我尝试了下,把Integer.MAX_VALUE改成了100(需要统计的key有122个),然后,就飙红了
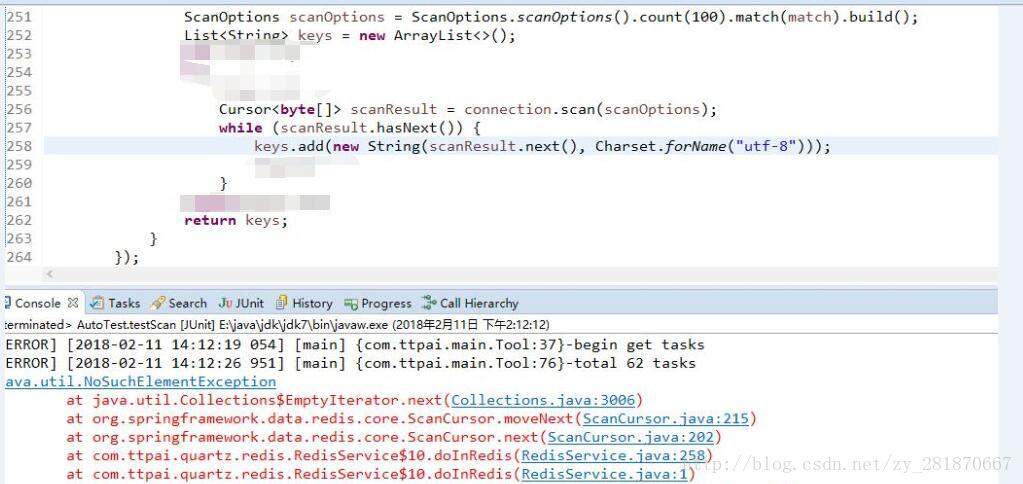
但是,你把count从100改成大于等于122,那就正常运行。按这规律,是count的参数必须不小于实际数量?我也在stackoverflow看到一篇帖子,说的貌似也是要这样解决。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号