C++ struct结构体内存对齐
•小试牛刀
我们自定义两个结构体 A 和 B:
struct A { char c1; char c2; int i; double d; }; struct B { char c1; int i; char c2; double d; };通过定义我们可以看出,结构体 A 和 B 拥有相同的成员,只不过在排列顺序上有所不同;
众所周知,char 类型占 1 个字节,int 类型占 4 个字节,double 类型占 8 个字节;
那么,这两个结构体所占内存空间大小为多少呢?占用的空间是否相同?
空口无凭,让我们通过编译器告诉我们答案(我使用的是 VS2022,X86)。
在 main() 函数中输出如下语句:
int main() { printf("结构体A所占内存大小为:%d\n", sizeof(A)); printf("结构体B所占内存大小为:%d\n", sizeof(B)); return 0; }运行之前,先盲猜一个结果:
sizeof(A) = sizeof(B) = sizeof(c1)+sizeof(c2)+sizeof(i)+sizeof(d) = 1+1+4+8 = 14
到底对不对呢?让我们来看看运行结果:
amazing~~
竟然一个都没猜对,这究竟是怎么回事呢?
下面开始进入今天的主题——struct 内存对齐。

•内存对齐
一种提高内存访问速度的策略,CPU 在访问未对齐的内存可能需要经过两次的内存访问,而经过内存对齐一次就可以了。
假定现在有一个 32 位处理器,那这个处理器一次性读取或写入都是四字节。
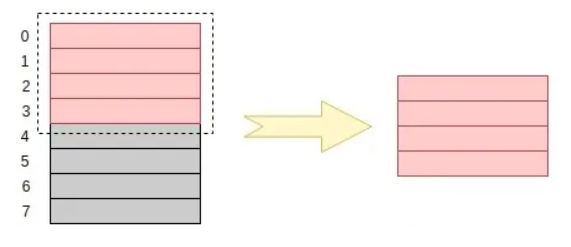
假设现在有一个 32 位处理器要读取一个 int 类型的变量,在内存对齐的情况下,处理器是这样进行读取的:
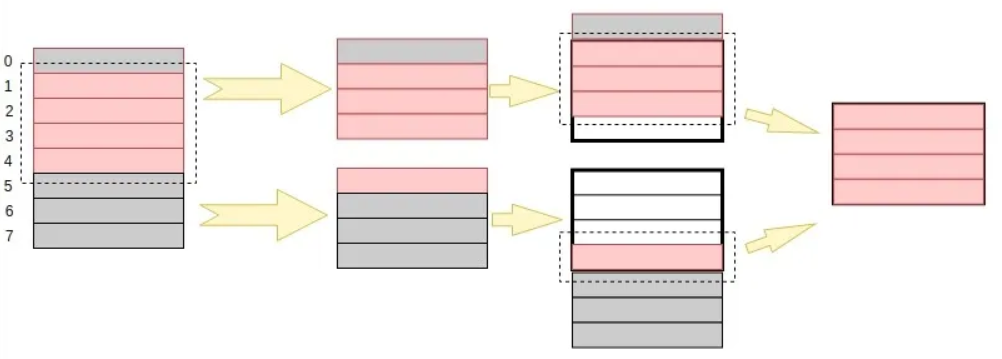
那如果数据存储没有按照内存对齐的方式进行的话,处理器就会这样进行读取:
对比内存对齐和内存没有对齐两种情况我们可以明显地看到,在内存对齐的情况下,取得这个 int型 变量只需要经过一次寻址(0~3);
但在内存没有对齐的情况下,取得这个 int型 变量需要经过两次的寻址(0~3 和 4~7),然后再合并数据。
通过上述的分析,我们可以知道内存对齐能够提升性能,这也是我们要进行内存对齐的原因之一。
•内存对齐的原则
- 对于结构体的各个成员,除了第一个成员的偏移量为 0 外,其余成员的偏移量是 其实际长度 的整数倍,如果不是,则在前一个成员后面补充字节。
- 结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍。
- 如程序中有 #pragma pack(n) 预编译指令,则所有成员对齐以 n字节 为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
下面通过样例来分享一下我的见解,为方便理解,声明如下:
- 定义的结构体包含 char , short , int , double类型各一个,并通过不同的组合构造出不同的结构体 Test01 , Test02 , Test03 , Test04
- 内存地址的编号设置为 0~24
- char 类型占1 个 字节,并用橙色填充
- short 类型占 2个 字节,并用黄色填充
- int 类型占 4个 字节,并用绿色填充
- double 类型占 8个 字节,并用蓝色填充
- 补充字节用黑色填充
Test01
struct Test01 { char c; short s; int i; double d; }t1;内存分布情况:
- 第一个成员 c 的偏移量为 0,所以成员 c 的内存空间的首地址为 0
- 第二个成员 s 的内存空间的首地址为 2 号地址,偏移量为 2 - 0 = 2
- 第三个成员 i 的内存空间的首地址为 4 号地址,偏移量为 4 - 0 = 4
- 第三个成员 d 的内存空间的首地址为 8 号地址,偏移量为 8 - 0 = 8
- Test01 所占内存大小为 16 个字节
让我们通过输出来验证一下:
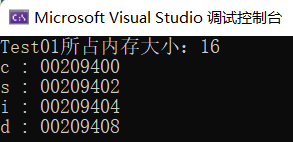
void showTest01() { printf("Test01所占内存大小:%d\n",sizeof(Test01)); //并按照声明顺序输出 Test01 中的成员变量地址对应的十六进制 printf("%p\n", &t1.c); printf("%p\n", &t1.s); printf("%p\n", &t1.i); printf("%p\n", &t1.d); }输出结果:
我们将输出的十六进制地址转化为十进制:
00209400 -> 2135040
00209402 -> 2135042
00209404 -> 2135044
00209408 -> 2135048
- 以第一个成员 c 的起始地址为起点
- 第二个成员 s 的偏移量为 2
- 第三个成员 i 的偏移量为 4
- 第四个成员 d 的偏移量为 8
- 所占内存大小为 16
验证成功!
Test02
调换一下成员顺序,再次测试:
struct Test02 { char c; double d; int i; short s; }t2;内存分布情况:
- 第一个成员 c 的偏移量为 0,所以成员 c 的内存空间的首地址为 0
- 第二个成员 d 的内存空间的首地址为 8 号地址,偏移量为 8 - 0 = 8(double 类型的整倍数)
- 第三个成员 i 的内存空间的首地址为 16 号地址,偏移量为 16 - 0 = 16(int 类型的整倍数)
- 第三个成员 s 的内存空间的首地址为 20 号地址,偏移量为 20 - 0 = 20(short 类型的整倍数)
- Test02 所占内存大小为 24 个字节(结构体占用内存大小是结构体内最大数据成员 double 的最小整数倍:24 / 8 = 4)
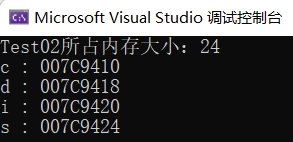
接着通过输出来验证一下:
我们将输出的十六进制地址转化为十进制:
007C9410 -> 8164368
007C9418 -> 8164376
007C9420 -> 8164384
007C9424 -> 8164388
- 以第一个成员 c 的起始地址为起点
- 第二个成员 d 的偏移量为 8164376 - 8164368 = 8
- 第三个成员 i 的偏移量为 8164384 - 8164368 = 16
- 第四个成员 d 的偏移量为 8164388 - 8164368 = 20
- 所占内存大小为 24
验证成功!
Test03 & Test04
struct Test03 { short s; double d; char c; int i; }t3; struct Test04 { double d; char c; int i; short s; }t4;内存分布情况:
可自行输出验证!!!



•总结
通过自行模拟,再回过头看看内存对齐的原则,是不是有种恍然大明白的感觉~
通过模拟上述不同情况,你会发现同种类型的成员变量通过不同的组合,所占用的总内存是不相同的;
那么,关于结构体内成员定义的顺序应该遵循这样一个原则:按照长度递增的顺序依次定义各个成员。
•声明
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号