【平价数据】SimGAN:活用合成数据和无监督数据
【平价数据】SimGAN:活用合成数据和无监督数据
Shrivastava, Ashish, et al. “Learning from simulated and unsupervised images through adversarial training.” IEEE Conference on Computer Vision and Pattern Recognition.2017
概述
本文是Apple在机器学习领域的首秀,同时也是CVPR 2017的两篇Best Paper之一。
在使用深度学习结局实际问题时,我们常常遇到以下的局面:
| 类别 | 品质 | 标记 | 数量 |
|---|---|---|---|
| 监督数据 | 真实 | 有 | 少 |
| 无监督数据 | 真实 | 无 | 大 |
| 合成数据 | 不真实 | 有 | 大 |
本文举了两个例子:视线方向识别和手势识别。
- 两种问题的标定都十分困难,使得监督数据昂贵而稀少。- 可以用CG模型合成数据。这些数据的视线方向和手关节位置已知,但画面不够真实。 本文利用GAN思想,通过无监督数据提升合成数据的质量,同时不改变合成数据的标记。之后使用优化过的合成数据训练模型。
方法
系统框架
类似GAN网络,本文系统中包含两个核心模块
R
R
R:输入合成数据,输出改善结果。</li><li>鉴别器
D
D
D:判断输入是真实数据还是经过改善的合成数据。</li>
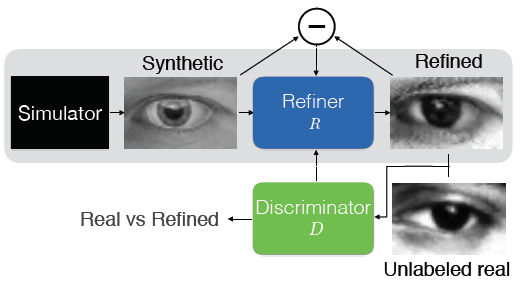
注意,训练的最终目的是生成改善后的合成数据。而不是改善器或者鉴别器本身。
优化
相关的代价有三种
- 代价1:鉴别器识别改善图像的错误率。- 代价2:鉴别器识别真实图像的错误率。- 代价3:改善图像和原始图像的逐像素差。 其中,代价3保证改善图像和原始图像的类标相同。例如,保证手势姿态不变,保证视线方向不变。除了直接比较像素,还可以提取图像特征之后在做差。
在每一轮迭代中:
R
R
R的参数。共执行
K
r
K_r
Kr次SGD。</li><li>最小化**代价1**,最小化**代价2**,优化鉴别器
D
D
D的参数。共执行
K
d
K_d
Kd次SGD。</li>
经过若干次迭代得到的改善器
R
R
R,可以将合成样本加工成具有以下两个性质的样本:
- 品质和真实图像难以分辨- 保持合成样本原有类标不变 ## 改进:局部损失
问题
随着迭代进展,鉴别器
D
D
D可能过分利用某些错误的全局特征进行分类,进而使得改善图像出现不自然的artifact。
举例:真实图像中可能只包含几个固定视线方向的样本,但合成图像的视线方向则均匀而连续。于是鉴别器“剑走偏锋”地以视线方向作为真假样本的判别标准。[1](#fn1)
解决
本文在训练鉴别器
D
D
D时,将图像分割成
w
×
h
w\times h
w×h的小块分别输入;在利用
D
D
D进行分类时,以各个小块的分类结果只和作为该图像的结果。<br> 除了避免全局信息引入artifact之外,这种方法还能够增加训练样本的数量。
改进:历史信息
问题
随着每一次迭代,改善器
R
R
R输出的图像是**逐步变化**的。相应地,鉴别器能够有效辨识的图像也**集中**在最近的改善器输出中。这导致两个问题:
- 对抗训练不收敛[2](#fn2)
- 改善器
R
R
R会重新引入之前出现过、但已经被鉴别器
D
D
D忘记的artifact</li>
解决
本文设置一个buffer来储存迭代中生成的改善图像。
b
b
b的mini-batch中,有一半数据来源于这个buffer,另一半来源于当前改善器
R
R
R的输出。</li><li>完成迭代后,用当前改善器的输出替换
b
/
2
b/2
b/2个buffer中的样本。</li>
实验
视线方向估计
数据
真实数据:214K的MPIIGaze数据库
合成数据:1.2M使用UnityEyes生成图像,使用单一渲染环境
由于合成图像和真是图像在颜色上差别较大,在计算代价3时使用RGB三通道平均值之差代替逐像素差。
由于视线方向估计是在灰度图上进行,使用灰度代价即可。
结果
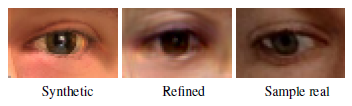
改善图像(中)能够保持原始图像(左)的视线方向,同时其品质接近真实图像(右),即使真人也难以分辨。
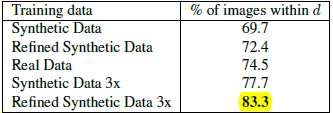
使用改善图像训练的分类器,效果大大超出使用原始合成图像训练的分类器。 与state of the art相比,错误率也有明显降低。

手势识别
数据
真实数据:NYU hand pose。70K训练,8K测试。未标定。裁剪缩放为224×224深度图像。
合成数据:数量未提及。包含14个关节标定结果。
结果
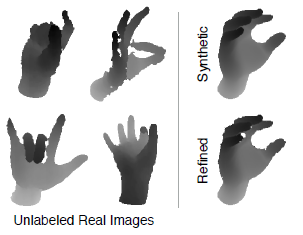
改善数据能够逼真模拟真实数据中的噪声。
使用改善数据训练的分类器指标具有明显优势。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号