
BP、pytorch、TensorFlow
TensorFlow:
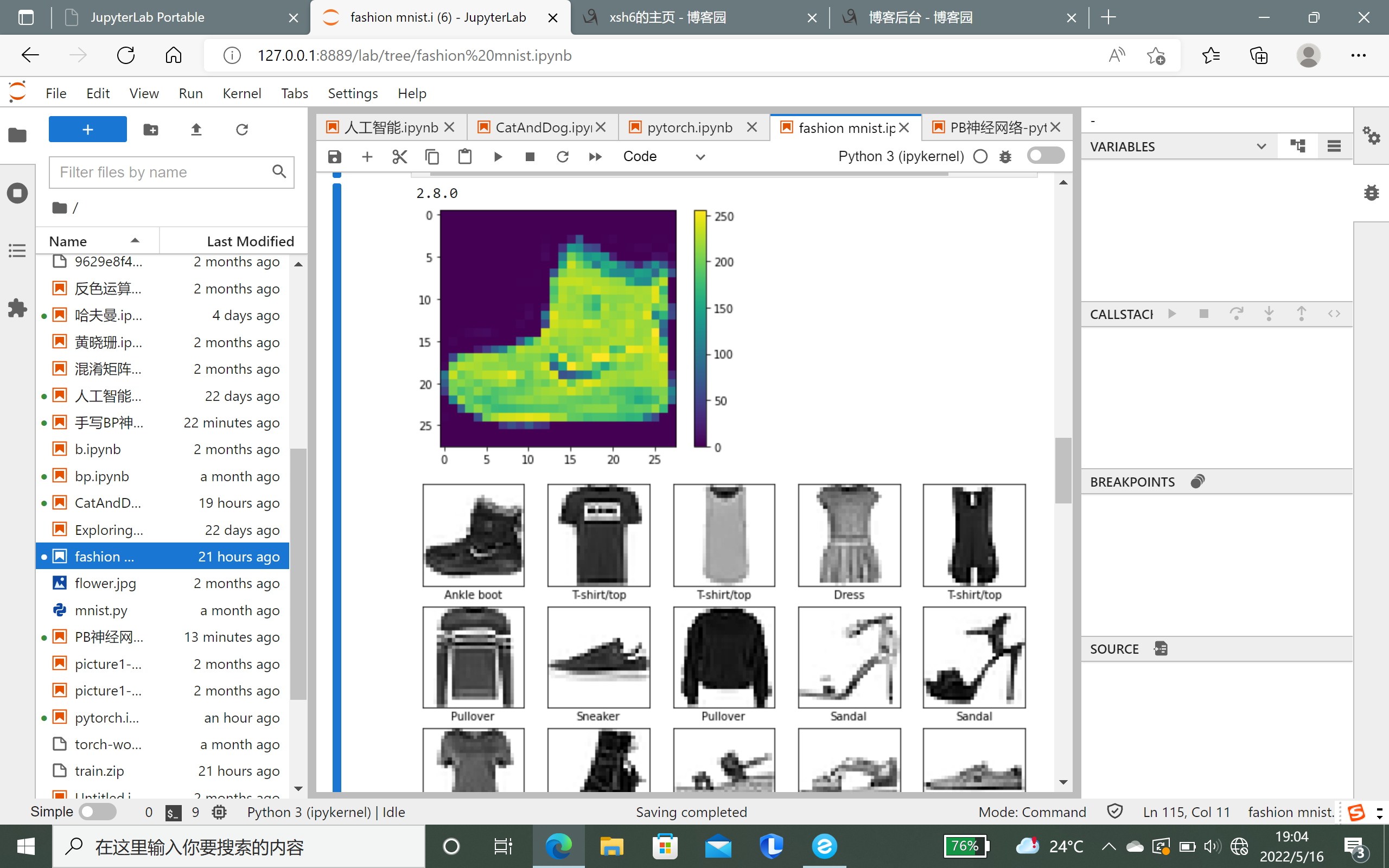
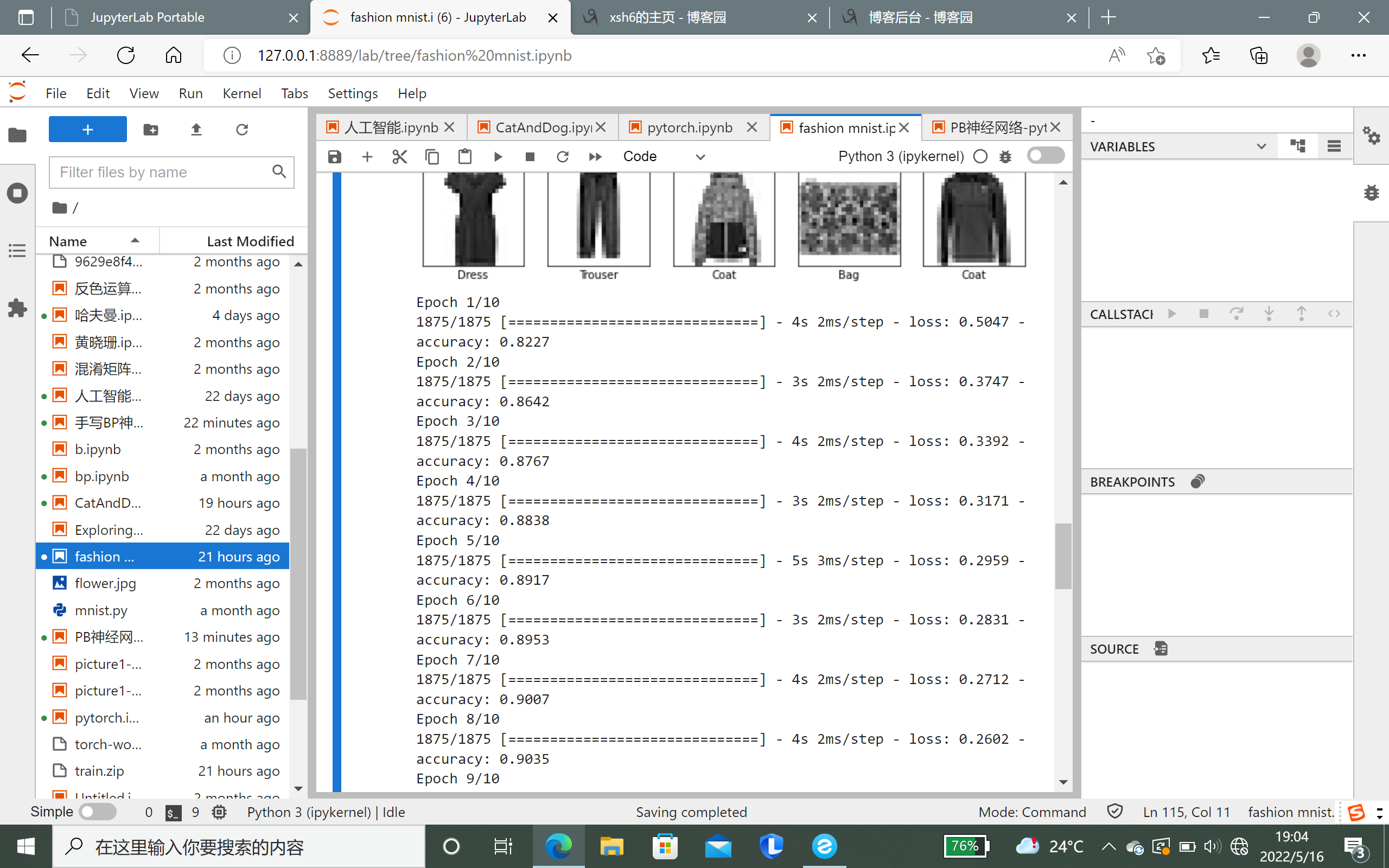
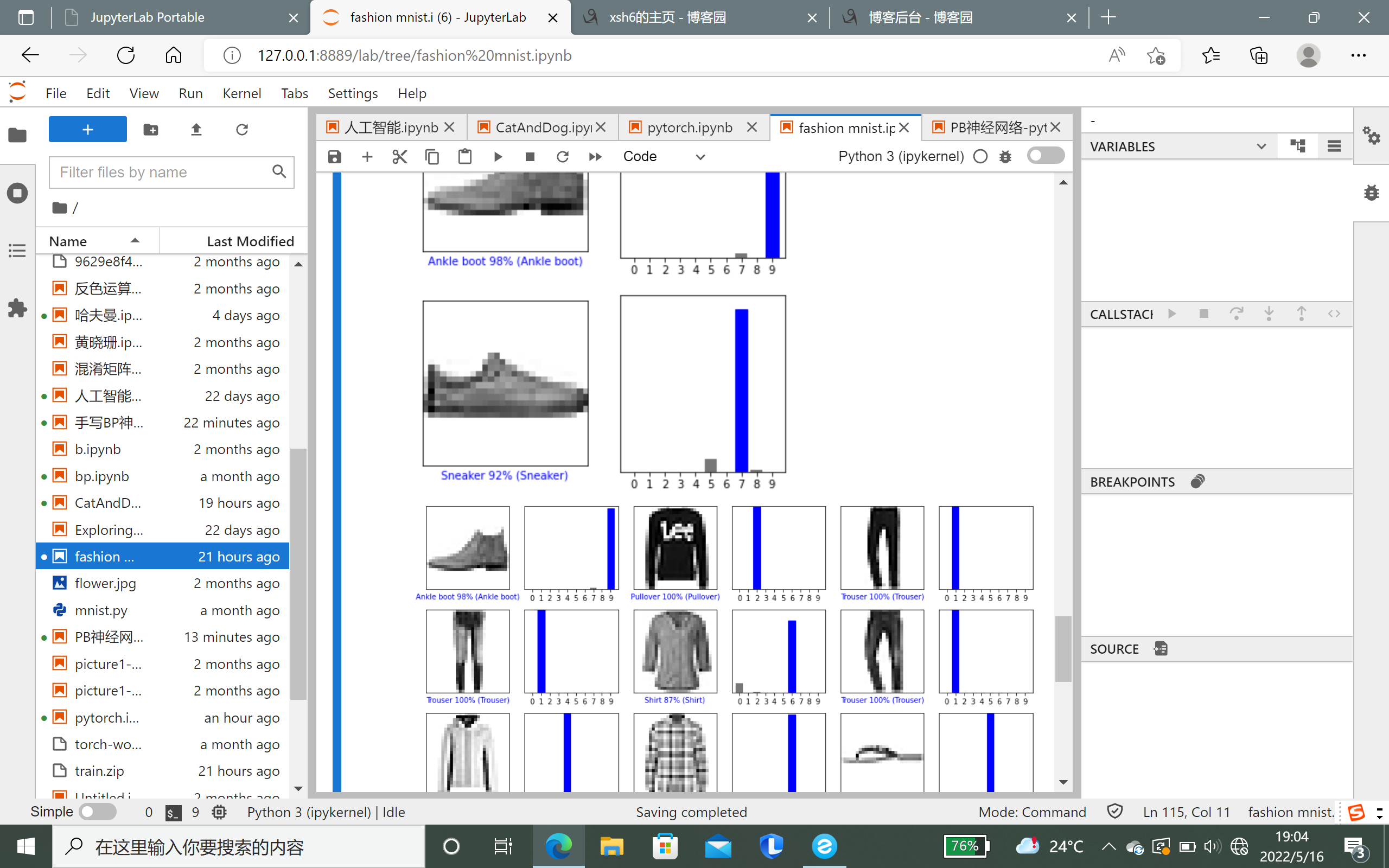
# TensorFlow and tf.keras import tensorflow as tf from tensorflow import keras # Helper libraries import numpy as np import matplotlib.pyplot as plt print(tf.__version__) fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False) plt.show() train_images = train_images / 255.0 test_images = test_images / 255.0 plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]]) plt.show() model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10) ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) model.fit(train_images, train_labels, epochs=10) test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print('\nTest accuracy:', test_acc) probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()]) predictions = probability_model.predict(test_images) def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array, true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array, true_label[i] plt.grid(False) plt.xticks(range(10)) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue') i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions[i], test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions[i], test_labels) plt.show() i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions[i], test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions[i], test_labels) plt.show() num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions[i], test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions[i], test_labels) plt.tight_layout() plt.show()
pytorch:
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 1 input image channel, 6 output channels, 5x5 square convolution # kernel self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) # an affine operation: y = Wx + b self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features net = Net() print(net)

params = list(net.parameters()) print(len(params)) print(params[0].size()) # conv1's .weight
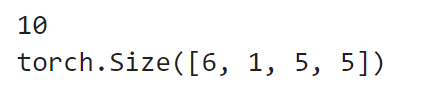
input = torch.randn(1, 1, 32, 32) out = net(input) print(out)

net.zero_grad()
out.backward(torch.randn(1, 10))
output = net(input) target = torch.randn(10) # a dummy target, for example target = target.view(1, -1) # make it the same shape as output criterion = nn.MSELoss() loss = criterion(output, target) print(loss)

print(loss.grad_fn) # MSELoss print(loss.grad_fn.next_functions[0][0]) # Linear print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU

net.zero_grad() # zeroes the gradient buffers of all parameters print('conv1.bias.grad before backward') print(net.conv1.bias.grad) loss.backward() print('conv1.bias.grad after backward') print(net.conv1.bias.grad)

learning_rate = 0.01 for f in net.parameters(): f.data.sub_(f.grad.data * learning_rate)
import torch.optim as optim # create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01) # in your training loop: optimizer.zero_grad() # zero the gradient buffers output = net(input) loss = criterion(output, target) loss.backward() optimizer.step() # Does the update
CatAndDog:
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers, regularizers import numpy as np import os import cv2 import matplotlib.pyplot as plt os.environ["CUDA_VISIBLE_DEVICES"] = "1"
resize = 224 path ="train/" def load_data(): imgs = os.listdir(path) num = len(imgs) train_data = np.empty((5000, resize, resize, 3), dtype="int32") train_label = np.empty((5000, ), dtype="int32") test_data = np.empty((5000, resize, resize, 3), dtype="int32") test_label = np.empty((5000, ), dtype="int32") for i in range(5000): if i % 2: train_data[i] = cv2.resize(cv2.imread(path+'/'+ 'dog.' + str(i) + '.jpg'), (resize, resize)) train_label[i] = 1 else: train_data[i] = cv2.resize(cv2.imread(path+'/' + 'cat.' + str(i) + '.jpg'), (resize, resize)) train_label[i] = 0 for i in range(5000, 10000): if i % 2: test_data[i-5000] = cv2.resize(cv2.imread(path+'/' + 'dog.' + str(i) + '.jpg'), (resize, resize)) test_label[i-5000] = 1 else: test_data[i-5000] = cv2.resize(cv2.imread(path+'/' + 'cat.' + str(i) + '.jpg'), (resize, resize)) test_label[i-5000] = 0 return train_data, train_label, test_data, test_label
def vgg16(): weight_decay = 0.0005 nb_epoch = 100 batch_size = 32 # layer1 model = keras.Sequential() model.add(layers.Conv2D(64, (3, 3), padding='same', input_shape=(224, 224, 3), kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.3)) # layer2 model.add(layers.Conv2D(64, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # layer3 model.add(layers.Conv2D(128, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer4 model.add(layers.Conv2D(128, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # layer5 model.add(layers.Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer6 model.add(layers.Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer7 model.add(layers.Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # layer8 model.add(layers.Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer9 model.add(layers.Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer10 model.add(layers.Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # layer11 model.add(layers.Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer12 model.add(layers.Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.4)) # layer13 model.add(layers.Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Dropout(0.5)) # layer14 model.add(layers.Flatten()) model.add(layers.Dense(512, kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) # layer15 model.add(layers.Dense(512, kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation('relu')) model.add(layers.BatchNormalization()) # layer16 model.add(layers.Dropout(0.5)) model.add(layers.Dense(2)) model.add(layers.Activation('softmax')) return model
#if __name__ == '__main__': train_data, train_label, test_data, test_label = load_data() train_data = train_data.astype('float32') test_data = test_data.astype('float32') train_label = keras.utils.to_categorical(train_label, 2) test_label = keras.utils.to_categorical(test_label, 2)
#定义训练方法,超参数设置 model = vgg16() sgd = tf.keras.optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) #设置优化器为SGD model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy']) history = model.fit(train_data, train_label, batch_size=20, epochs=10, validation_split=0.2, #把训练集中的五分之一作为验证集 shuffle=True) scores = model.evaluate(test_data,test_label,verbose=1) print(scores) model.save('model/vgg16dogcat.h5')

acc = history.history['accuracy'] # 获取训练集准确性数据 val_acc = history.history['val_accuracy'] # 获取验证集准确性数据 loss = history.history['loss'] # 获取训练集错误值数据 val_loss = history.history['val_loss'] # 获取验证集错误值数据 epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, 'bo', label='Trainning acc') # 以epochs为横坐标,以训练集准确性为纵坐标 plt.plot(epochs, val_acc, 'b', label='Vaildation acc') # 以epochs为横坐标,以验证集准确性为纵坐标 plt.legend() # 绘制图例,即标明图中的线段代表何种含义 plt.show()
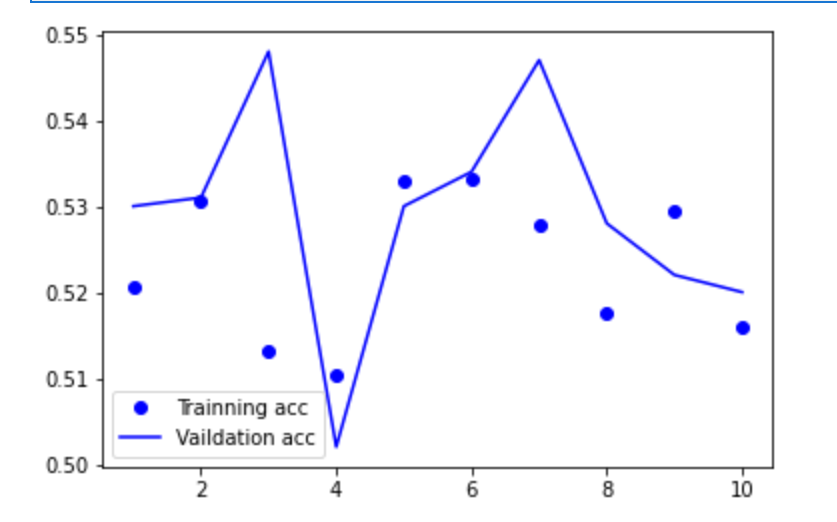
BP:
import math import numpy as np import csv from sklearn import preprocessing import xlsxwriter import matplotlib.pyplot as plt
#首先一开始权重w和偏置b是不知道的,所以先要随机生成一个 def initial_bp_neural_network(n_inputs, n_hidden_layers, n_outputs): # hidden_layers 是一个列表,表示第n层隐含层神经元有几个 global hidden_layers_weights global hidden_layers_bias hidden_layers_weights = [] hidden_layers_bias = [] # 一定要有隐含层, np.ones((行,列));每个神经元对应着一个偏置 if len(n_hidden_layers) > 0: hidden_layers_weights.append(np.random.randn(n_hidden_layers[0], n_inputs) * 0.01) #print("1:",hidden_layers_weights) for i in range(len(n_hidden_layers) - 1): hidden_layers_weights.append(np.random.rand(n_hidden_layers[i + 1], n_hidden_layers[i]) * 0.01) #print("i:",n_hidden_layers[i + 1]) #print("2:",hidden_layers_weights) for i in n_hidden_layers: hidden_layers_bias.append(np.zeros(i)) #print("3:",hidden_layers_bias) hidden_layers_weights.append(np.random.rand(n_outputs, n_hidden_layers[len(n_hidden_layers) - 1]) * 0.01) #print("4:",hidden_layers_weights) hidden_layers_bias.append(np.zeros(n_outputs)) #print("5:",hidden_layers_bias) return hidden_layers_weights #最后合并在一起
# import tensorflow.compat.v1 as tf # def leaky_relu(x, leak=0.2, name="leaky_relu"): # with tf.variable_scope(name):#tf.variable_scope()用来指定变量的作用域 # f1 = 0.5 * (1 + leak) # f2 = 0.5 * (1 - leak) # return f1 * x + f2 * abs(x) # def logistic(z,name="logistic"): # with tf.variable_scope(name): # return 1 / (1 + np.exp(-z))
#向前传播 def forward_propagate(inputs): global hidden_layers_weights global hidden_layers_bias global train_outputs global train_inputs train_inputs = [] train_outputs = [] function_vector = np.vectorize(Leaky_ReLu) #np.vecotrize(pyfunc)定义一个向量化的函数(pyfunc),使得数组可以作为输入, 并返回数组作为输出。 for i in range(len(hidden_layers_weights)): outputs = np.array(hidden_layers_weights[i]).dot(inputs) outputs = np.array(outputs) + np.array(hidden_layers_bias[i]) outputs = np.array(batch_normalization(outputs)) train_inputs.append(outputs) outputs = function_vector(outputs) # 把每一层的输出都记录进去 train_outputs.append(outputs) inputs = outputs.copy() return train_outputs
#反向传播 def backward_error_propagate(outputs): global error # error 是倒着来存放的 error = [] function_vector = np.vectorize(Leaky_ReLu_derivative) # train_outputs 包含了每一层的输出,最后一个才是最终的结果 print("len(train_outputs):",len(train_outputs)) print("len(train_inputs):",len(train_inputs)) for i in range(len(train_outputs)): if i == 0: # 一个是对均方误差求导数,一个是对激活函数求导数 # error.append(error_function_derivative(outputs, train_outputs[len(train_outputs) - 1]) * # function_vector(np.array(train_inputs[len(train_inputs) - 1]))) error.append(error_function_derivative(outputs, soft_max()) * function_vector(np.array(train_inputs[len(train_inputs) - 1]))) else: # 激活函数求导,直接点乘 # print(function_vector(np.array(train_inputs[len(train_inputs) - 1 - i]))) # 一个神经元对应的权重的误差求和 error.append(function_vector(np.array(train_inputs[len(train_inputs) - 1 - i])) * hidden_layers_weights[len(train_outputs) - i].T.dot(error[i - 1]))
for i in range(2): print(i)

#更新 def update(inputs): global hidden_layers_weights global hidden_layers_bias global error global train_inputs # 更新权重 for i in range(len(hidden_layers_weights)): if i == 0: hidden_layers_weights[i] = hidden_layers_weights[i] - learning_rate * ( error[len(error) - i - 1].reshape(len(error[len(error) - i - 1]), 1) * np.array(inputs).reshape(1, len(inputs)) + np.array(hidden_layers_weights[i])) else: hidden_layers_weights[i] = hidden_layers_weights[i] - learning_rate * ( error[len(error) - i - 1].reshape(len(error[len(error) - i - 1]), 1) * np.array(train_outputs[i - 1]).reshape(1, len(train_outputs[i - 1])) + np.array(hidden_layers_weights[i])) # print('error:') # print(learning_rate * ( # error[len(error) - i - 1].reshape(len(error[len(error) - i - 1]), 1) * # np.array(train_inputs[i - 1]).reshape(1, len(train_inputs[i - 1])) + hidden_layers_weights[i])) # print('hidden_layer_weight:') # print(hidden_layers_weights[i]) for i in range(len(hidden_layers_bias)): hidden_layers_bias[i] = hidden_layers_bias[i] - learning_rate * (error[len(error) - i - 1])
# 交叉熵函数作为损失函数 def error_function(actual_outputs, predict_outputs): function_vector = np.vectorize(math.log) return -sum(actual_outputs * function_vector(predict_outputs)) # 交叉熵函数的导数,针对输出层所有神经元 # 这个顺序一定不能颠倒 def error_function_derivative(actual_outputs, predict_outputs): return predict_outputs - actual_outputs # 激活函数 Leaky_ReLu def Leaky_ReLu(x): if x > 0: return x return 0.01 * x # 激活函数Leaky_ReLu函数的导数 def Leaky_ReLu_derivative(x): if x > 0: return 1 return 0.01 # 预测判断,判断是否达到收敛或者是和预期结果一样,精度可以自己调试 def judge_predict(): for i in range(len(train_outputs[len(train_outputs) - 1])): if abs(train_outputs[len(train_outputs) - 1][i] - test_outputs[i]) > 0.00001: return 0 return 1 # 分类判断,输出精确度 def judge_classification(label): max_value = max(soft_max()) max_index = soft_max().index(max_value) if max_index + 1 == label: # return 1 return label return 0
# 将输出的数值转换为概率 def soft_max(): return [math.exp(train_outputs[len(train_outputs) - 1][0]) / (math.exp(train_outputs[len(train_outputs) - 1][0]) + math.exp(train_outputs[len(train_outputs) - 1][1]) + math.exp(train_outputs[len(train_outputs) - 1][2])), math.exp(train_outputs[len(train_outputs) - 1][1]) / (math.exp(train_outputs[len(train_outputs) - 1][0]) + math.exp(train_outputs[len(train_outputs) - 1][1]) + math.exp(train_outputs[len(train_outputs) - 1][2])), math.exp(train_outputs[len(train_outputs) - 1][2]) / (math.exp(train_outputs[len(train_outputs) - 1][0]) + math.exp(train_outputs[len(train_outputs) - 1][1]) + math.exp(train_outputs[len(train_outputs) - 1][2]))]
with open(r'C:\Users\Administrator\Desktop\Datasets-master\wheat-seeds.csv', 'r') as file: reader = csv.reader(file) print(reader) column = [row for row in reader] data = np.array(column).astype(float) print(data)
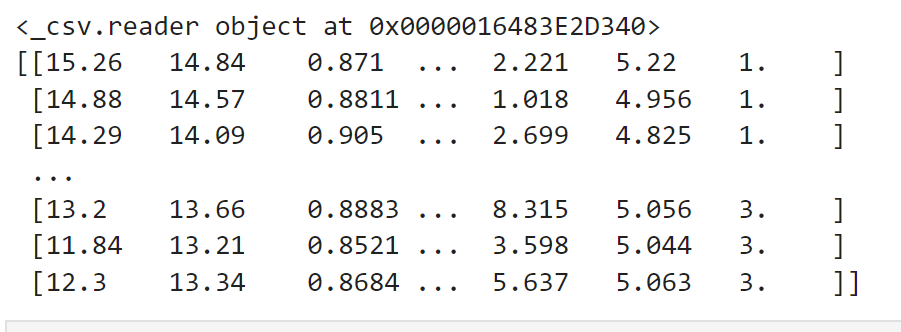
# 训练网络 def train_network(epoch): global data global test_inputs global test_outputs with open(r'C:\Users\Administrator\Desktop\Datasets-master\wheat-seeds.csv', 'r') as file: reader = csv.reader(file) column = [row for row in reader] # 乱序排列 data = np.array(column).astype(float) # batch_size batch_size = 30 iteration = 7 # workbook = xlsxwriter.Workbook('data.xlsx') worksheet = workbook.add_worksheet() for _epoch in range(epoch): # 获取乱序, 让每次迭代都不一样 if _epoch != 1: np.random.shuffle(data) # 获取输入 test_inputs = [row[0:7] for row in data] test_inputs = min_max_scaler.fit_transform(test_inputs) # 获取输出 test_outputs = [row[7] for row in data] # 训练一个batch就是一次iteration for i in range(iteration): n1 = 0 n2 = 0 n3 = 0 # 一次迭代更新网络的参数 # len(test_outputs) for j in range(batch_size): forward_propagate(test_inputs[j + i * batch_size]) # 使用独热编码 if test_outputs[j + i * batch_size] == 1: backward_error_propagate(np.array([1, 0, 0])) elif test_outputs[j + i * batch_size] == 2: backward_error_propagate(np.array([0, 1, 0])) else: backward_error_propagate(np.array([0, 0, 1])) update(test_inputs[j + i * batch_size]) # print("迭代完成") # 使用训练好的网络来得到测试的结果 print('--------开始测试集的工作--------') # for j in range(len(test_inputs)): # forward_propagate(test_inputs[j]) # print(soft_max()) for j in range(len(test_outputs)): forward_propagate(test_inputs[j]) # print(judge_classification(test_outputs[j])) if judge_classification(test_outputs[j]) == 1: # n = n + 1 n1 = n1 + 1 elif judge_classification(test_outputs[j]) == 2: n2 = n2 + 1 elif judge_classification(test_outputs[j]) == 3: n3 = n3 + 1 # acc = n / len(test_outputs) acc1 = n1 / 70 acc2 = n2 / 70 acc3 = n3 / 70 worksheet.write(_epoch, 0, acc1) worksheet.write(_epoch, 1, acc2) worksheet.write(_epoch, 2, acc3) print('第' + str(_epoch) + "次迭代") print('准确率为:') print(acc1) print(acc2) print(acc3) workbook.close()
def batch_normalization(outputs): output = [] # 求均值 arr_mean = np.mean(outputs) # 求方差 arr_var = np.var(outputs) for i in outputs: output.append((i-arr_mean)/(math.pow(arr_var, 0.5))) return output
if __name__ == '__main__': learning_rate = 0.0005 hidden_layers_weights = [] hidden_layers_bias = [] train_outputs = [] train_inputs = [] # 误差项 error = [] test_inputs = [] test_outputs = [] min_max_scaler = preprocessing.MinMaxScaler() data = [] # 这是一个三分类的问题,一共有三个标签 initial_bp_neural_network(7, [10], 3) train_network(100)

...


 浙公网安备 33010602011771号
浙公网安备 33010602011771号