#025爬虫引出的正则表达式。
正则表达式(Python)
笔记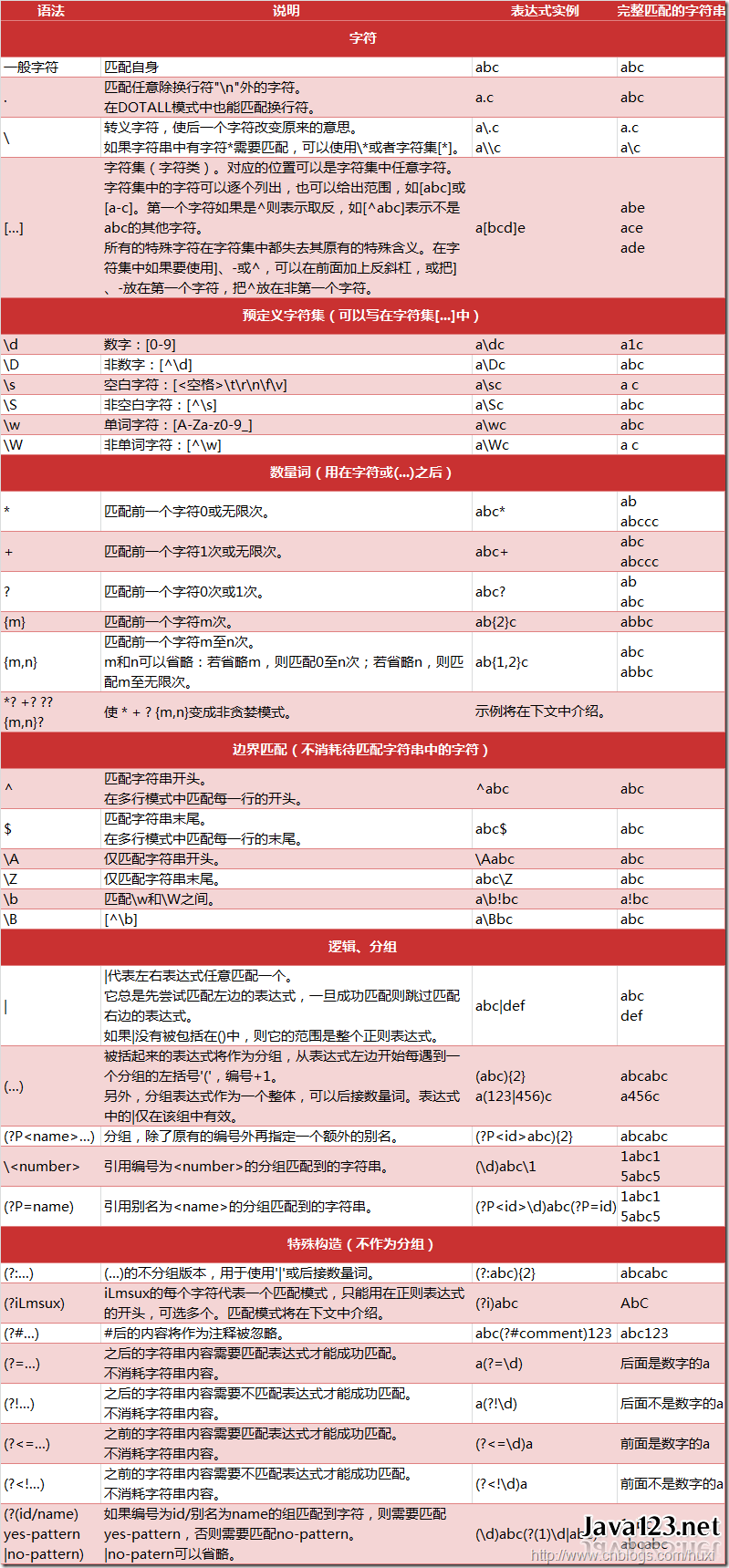
简单的匹配
# matching string pattern1 = "cat" pattern2 = "bird" string = "dog runs to cat" print(pattern1 in string) # True print(pattern2 in string) # False
import re # regular expression pattern1 = "cat" pattern2 = "bird" string = "dog runs to cat" print(re.search(pattern1, string)) # <_sre.SRE_Match object; span=(12, 15), match='cat'> print(re.search(pattern2, string)) # None
灵活匹配
1 # multiple patterns ("run" or "ran") 2 ptn = r"r[au]n" # start with "r" means raw string 3 print(re.search(ptn, "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
1 print(re.search(r"r[A-Z]n", "dog runs to cat")) # None 2 print(re.search(r"r[a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'> 3 print(re.search(r"r[0-9]n", "dog r2ns to cat")) # <_sre.SRE_Match object; span=(4, 7), match='r2n'> 4 print(re.search(r"r[0-9a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
按类型匹配
- \d : 任何数字
- \D : 不是数字
- \s : 任何 white space, 如 [\t\n\r\f\v]
- \S : 不是 white space
- \w : 任何大小写字母, 数字和 “” [a-zA-Z0-9]
- \W : 不是 \w
- \b : 空白字符 (只在某个字的开头或结尾)
- \B : 空白字符 (不在某个字的开头或结尾)
- \\ : 匹配 \
- . : 匹配任何字符 (除了 \n)
- ^ : 匹配开头
- $ : 匹配结尾
- ? : 前面的字符可有可无
1 # \d : decimal digit 2 print(re.search(r"r\dn", "run r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'> 3 # \D : any non-decimal digit 4 print(re.search(r"r\Dn", "run r4n")) # <_sre.SRE_Match object; span=(0, 3), match='run'> 5 # \s : any white space [\t\n\r\f\v] 6 print(re.search(r"r\sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'> 7 # \S : opposite to \s, any non-white space 8 print(re.search(r"r\Sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'> 9 # \w : [a-zA-Z0-9_] 10 print(re.search(r"r\wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'> 11 # \W : opposite to \w 12 print(re.search(r"r\Wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'> 13 # \b : empty string (only at the start or end of the word) 14 print(re.search(r"\bruns\b", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 8), match='runs'> 15 # \B : empty string (but not at the start or end of a word) 16 print(re.search(r"\B runs \B", "dog runs to cat")) # <_sre.SRE_Match object; span=(8, 14), match=' runs '> 17 # \\ : match \ 18 print(re.search(r"runs\\", "runs\ to me")) # <_sre.SRE_Match object; span=(0, 5), match='runs\\'> 19 # . : match anything (except \n) 20 print(re.search(r"r.n", "r[ns to me")) # <_sre.SRE_Match object; span=(0, 3), match='r[n'> 21 # ^ : match line beginning 22 print(re.search(r"^dog", "dog runs to cat")) # <_sre.SRE_Match object; span=(0, 3), match='dog'> 23 # $ : match line ending 24 print(re.search(r"cat$", "dog runs to cat")) # <_sre.SRE_Match object; span=(12, 15), match='cat'> 25 # ? : may or may not occur 26 print(re.search(r"Mon(day)?", "Monday")) # <_sre.SRE_Match object; span=(0, 6), match='Monday'> 27 print(re.search(r"Mon(day)?", "Mon")) # <_sre.SRE_Match object; span=(0, 3), match='Mon'>
如果一个字符串有很多行, 我们想使用^形式来匹配行开头的字符, 如果用通常的形式是不成功的. 比如下面的 “I” 出现在第二行开头, 但是使用r"^I"却匹配不到第二行, 这时候, 我们要使用 另外一个参数, 让re.search()可以对每一行单独处理. 这个参数就是flags=re.M, 或者这样写也行flags=re.MULTILINE.
1 string = """ 2 dog runs to cat. 3 I run to dog. 4 """ 5 print(re.search(r"^I", string)) # None 6 print(re.search(r"^I", string, flags=re.M)) # <_sre.SRE_Match object; span=(18, 19), match='I'>
重复匹配
*: 重复零次或多次+: 重复一次或多次{n, m}: 重复 n 至 m 次{n}: 重复 n 次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号