


之前从hive数据库中导出数据到本地mysql数据库没有使用sqoop,发现非常的麻烦,步骤太多并且一点也不好操作。
今天完成了sqoop的配置,首先下载sqoop1.4.7的版本,因为我的hadoop是3.3.4的版本,适配的sqoop为1.4.8版本,但是国内镜像最新的只有1.4.7,要1.4.8的话只能开魔法。
但是hadoop3.3.4使用1.4.7版本会有一些问题。所以进行了一些配置的修改,确保常用的不会出错。
-
那么首先进行sqoop的解压与目录权限的释放,并修改环境变量填入实际的路径。
cd /opttar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
chown -R hadoop:hadoop /opt/sqoop-1.4.7
并进行sqoop-env.sh的配置填入自己的hadoop,hive的实际路径
- 由于sqoop缺少jdbc驱动,首次执行需要将jdbc驱动的jar包复制到sqoop
![image]()

确认mysql账号权限与密码是否有问题
验证sqoop是否安装成功:sqoop version
我在使用mysql时出现了一点问题,密码安全度不够,重设密码并且又修改hive的一些配置,导致处理时间有些长。
-
NameNode 安全模式导致 Hive 启动失败
这个也是我出现的一些问题,可能是之前的数据哪里出错了或者修改了,导致NameNode一直不放锁,只需要 hdfs dfsadmin -safemode forceExit 这个命令修改一下就行 -
hive 与 mysql数据交互
执行sqoop语句即可,可以直接将hive中数据导入到本地mysql中,只需要修改为本机的ip地址即可。
最终将数据进行了导出。
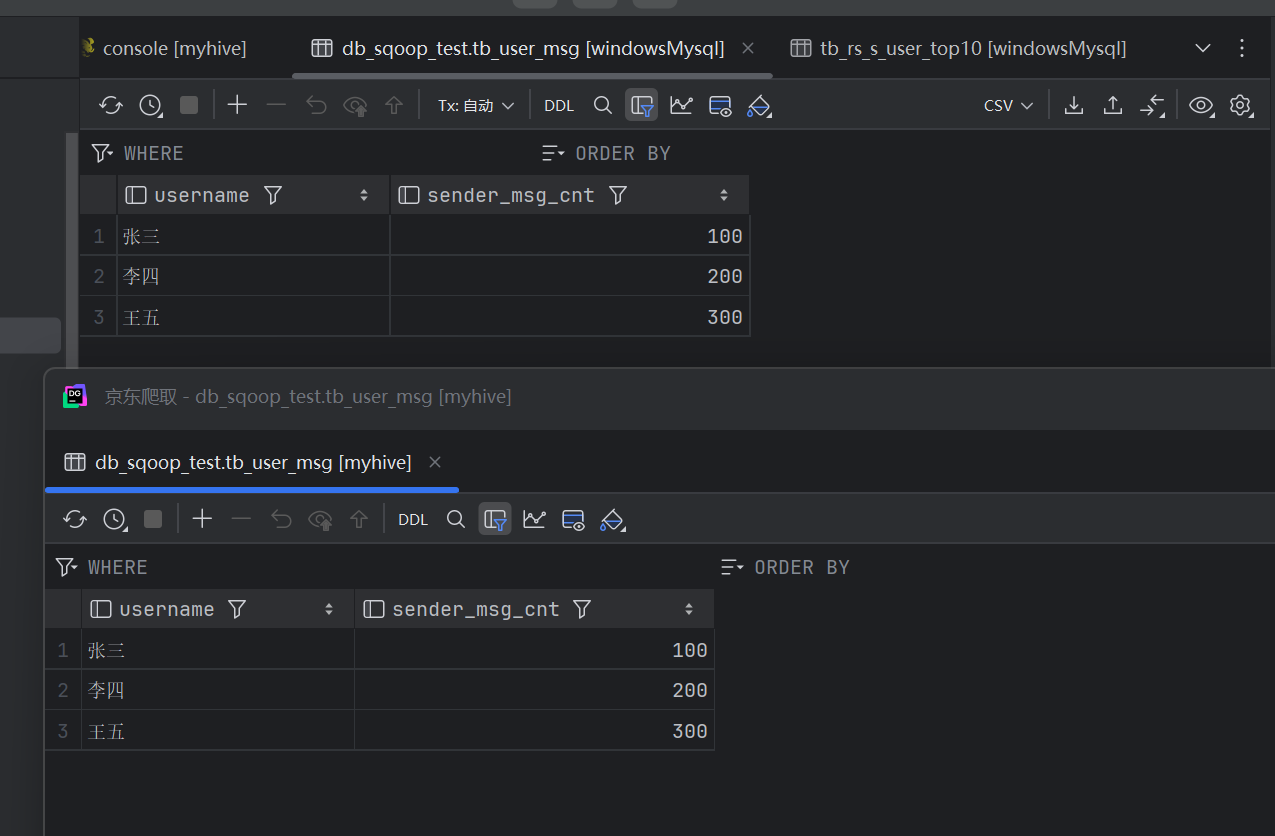
数据导出之后做可视化展示就比较简单了,之前的数据爬取,数据清洗等也进行了使用,目前就差sqoop配置进行数据导出这一步,今天也算是完成了。
整体体会:
从 Sqoop 安装到跨机导出数据,整个过程经历了目录权限、环境变量、JDBC 驱动缺失、MySQL 用户/密码与权限、
Hive Metastore 连接、NameNode 安全模式、YARN 任务失败、驱动兼容性、不同主机名/IP 解析等一系列实际问题。
每一步都通过“看报错 → 找关键句(Access denied / Connection refused / Could not load driver)→ 对应修改配置或权限”解决,
最终把 Hive、Hadoop、Sqoop、本机和虚拟机两套 MySQL 全部串联起来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号