面试题
2017-03-02 17:43 2017hwx 阅读(1151) 评论(0) 收藏 举报1、hash碰撞
我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突。如下将介绍如何处理冲突,当然其前提是一致性hash。
1.开放地址法
2.再哈希法
3.链地址法(拉链法)
http://blog.csdn.net/zeb_perfect/article/details/52574915
2、arraylist与linkdlist区别
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
http://www.cnblogs.com/liqiu/p/3302607.html
3、数据库锁、连接池
3、缓存redis
4、数据结构
http://www.cnblogs.com/liqiu/p/3302607.html
5、Springmvc
1. 简要描述String、StringBuffer、StringBuilder的区别
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
StringBuilder >StringBuffer > String
2. 描述一下JVM加载CLASS文件的原理机制
JVM中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java中的类加载器是一个重要的Java运行时系统组件,它负责在运行时查找和装入类文件中的类。
由于Java的跨平台性,经过编译的Java源程序并不是一个可执行程序,而是一个或多个类文件。当Java程序需要使用某个类时,JVM会确保这个类已经被加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后JVM对类进行初始化,包括:1)如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;2)如果类中存在初始化语句,就依次执行这些初始化语句。
类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展加载器(Extension)、系统加载器(System)和用户自定义类加载器(java.lang.ClassLoader的子类)。 从Java 2(JDK 1.2)开始,类加载过程采取了父亲委托机制(PDM)。PDM更好的保证了Java平台的安全性,在该机制中,JVM自带的Bootstrap是根加载器,其他的加载器都有且仅有一个父类加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子类加载器自行加载。JVM不会向Java程序提供对Bootstrap的引用。下面是关于几个类加载器的说明:
Bootstrap:一般用本地代码实现,负责加载JVM基础核心类库(rt.jar);
Extension:从java.ext.dirs系统属性所指定的目录中加载类库,它的父加载器是Bootstrap;
System:又叫应用类加载器,其父类是Extension。它是应用最广泛的类加载器。它从环境变量classpath或者系统属性java.class.path所指定的目录中记载类,是用户自定义加载器的默认父加载器。
http://blog.csdn.net/gfangxiong/article/details/7425563
3. Char型变量能否存储一个中文字?为什么?
可以啊。JAVA默认的编码是UNICODE.不是ASCII的char .
java采用unicode,2个字节(16位)来表示一个字符.
4. JAVA中实现多态有哪些方式?
5. 写出你所知道的java.util.concurrent包中的类,并简述它们的用途和应用场景
http://blog.csdn.net/defonds/article/details/44021605/
6. 简述synchronized和java.util.concurent.locks.Lock的异同点
- synchronized 代码块不能够保证进入访问等待的线程的先后顺序。
- 你不能够传递任何参数给一个 synchronized 代码块的入口。因此,对于 synchronized 代码块的访问等待设置超时时间是不可能的事情。
- synchronized 块必须被完整地包含在单个方法里。而一个 Lock 对象可以把它的 lock() 和 unlock() 方法的调用放在不同的方法里。
7. 编程题:设有N个人依次围成一圈,从第1个人开始报数,第M个人出列,然后从出列的下一个人开始报数,数到第M个人又出列,...,如此反复到所有的人全部出列为止,设N个人的编号分别为1,2,...,N,打印出出列的顺序,要求用java实现。

8. 说说你所知道的查找消耗比较大的SQL方法
9. 一张用户表有1000万条记录,主键为自增ID,从中取10条随机记录,如何实现?简述你的解决方案,可以用伪代码描述。
SELECT * FROM tablename WHERE id> ROUND(1+10000000*RAND()) LIMIT 10;
10. 一个大型网站用一张LOG表来记录用户的操作行为,每天会产生上百万条记录。另有一个调试程序定时清除三天前的数据(比如每天凌晨4点执行),以保障LOG表的数据量不会无限增长,要求写出调度程序的伪代码。
11. 写出Linux里查看进程的命令
ps -ef|grep java
12. 在LINUX里,如何查看一个监听端口为8060的进程?
13. 分析日志文件,要求统计出响应时间超过100ms的请求及其个数,写出相应的shell命令,文件内容如下,有三个字段,分别表示请求产生的时间戳、请求、响应时间
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法;
- 在运行时调用任意一个对象的方法;
- 生成动态代理。

springmvc 运行周期是什么?
1.dispatcherServlet会初始化HandlerMapping(注:通过它来处理客户端请求到各个Controller处理器的映射)
2. dispatcherServlet会初始化HandlerAdapter(注:HandlerMapping会根据它来调用Controller里需要被执行的方法)
3. dispatcherServlet会初始化handlerExceptionResolver(注:spring mvc处理流程中,如果有异常抛出,会交给它来进行异常处理)
4. dispatcherServlet会初始化ViewResolver (注:HandlerAdapter会把Controller中调用返回值最终包装成ModelAndView,ViewResolver会检查其中的view,如果view是一个字符串,它就负责处理这个字符串并返回一个真正的View,如果view是一个真正的View则不会交给它处理)
spring事务传播机制包括哪些?为了解决什么?
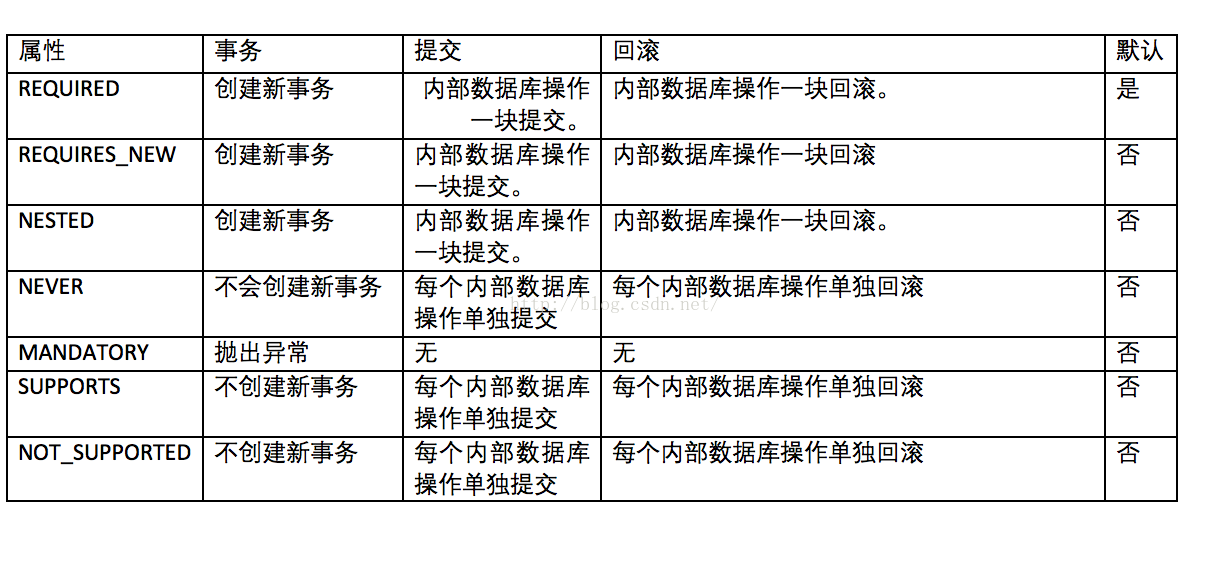
当有外部事务时

Redis内建支持两种持久化方案,snapshot快照和AOF 增量Log方式。快照顾名思义就是隔一段时间将完整的数据Dump下来存储在文件中。AOF增量Log则是记录对数据的修改操作(实际上记录的就是每个对数据产生修改的命令本身),两种方案可以并存,也各有优缺点,具体参见http://redis.io/topics/persistence
public class testHello {
public static void main(String[] args) {
// TODO Auto-generated method stub
System.out.println("test helllo");
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号