
搭建HBase+Phoenix大数据平台
一、大数据平台的技术选择
- HBase技术
HBase是一个分布式,版本化,面向列的开源数据库,构建在 Apache Hadoop和 Apache ZooKeeper之上。HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。

HBase的特点
- 海量数据存储,HBase中的表可以容纳上百亿行x上百万列的数据。
- 列式存储,HBase中的数据是基于列进行存储的,能够动态的增加和删除列。
- 准实时查询,HBase在海量的数据量下能够接近准实时的查询(百毫秒以内)
- 多版本,HBase中每一列的数据都有多个版本。
- 高可靠性,HBase中的数据存储于HDFS中且依赖于Zookeeper进行Master和RegionServer的协调管理。
HBase虽然支持表结构,但是操作起来并不方便。例如下面是个学生表,里面包含了若干的字段。
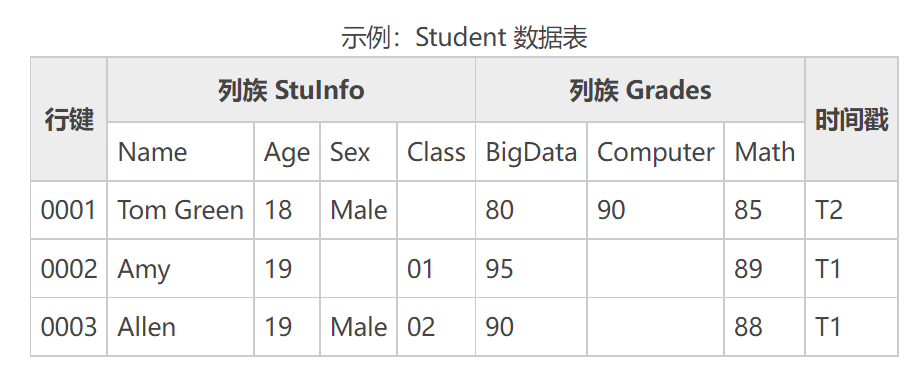
如果我们给学生表添加新的记录,就需要执行下面的命令。
put 'Student', '0001', 'Stulnfo:Name', 'Tom Green', 1
想要获取数据的时候,我们执行get命令就可以了。
get 'student', '0001'
对于我们平时习惯SQL语句的人来说,上面的命令如果简单还行,要是叠加上复杂的条件和函数,那么阅读性就非常差,所以我们要引入Phoenix技术。
scan 'mytest:test01',FILTER=>"RowFilter(=,'substring:202006')",LIMIT=>1
count 'mytest:test01',FILTER=>"RowFilter(=,'substring:202004')",INTERVAL=>10000
- Phoenix技术
Phoenix是给HBase添加了一个语法表示层,允许我们用SQL语句读写HBase中的数据,可以做联机事务处理,拥有低延迟的特性,这就让我方便多了。Phoenix会把SQL编译成一系列的Hbase的scan操作,然后把scan结果生成标准的JDBC结果集,处理千万级行的数据也只用毫秒或秒级就搞定。而且Phoenix还支持MyBatis框架,正好可以和华夏代驾项目整合到一起。

二、部署HBase与Phoenix
- 导入镜像文件
docker load < phoenix.tar.gz
- 创建容器
因为镜像中已经包含和HBase和Phoenix,所以我们只需要创建出容器即可。由于HBase需要使用的内存较大,这里我没有规定具体的内存大小,容器会自动使用空闲的内存。容器中数据目录是/tmp/hbase-root/hbase/data,我把这个目录映射到宿主机的/root/hbase/data目录。
docker run -it -d -p 2181:2181 -p 8765:8765 -p 15165:15165 \
-p 16000:16000 -p 16010:16010 -p 16020:16020 \
-v /root/hbase/data:/tmp/hbase-root/hbase/data \
--name phoenix --net mynet --ip 172.18.0.14 \
boostport/hbase-phoenix-all-in-one:2.0-5.0
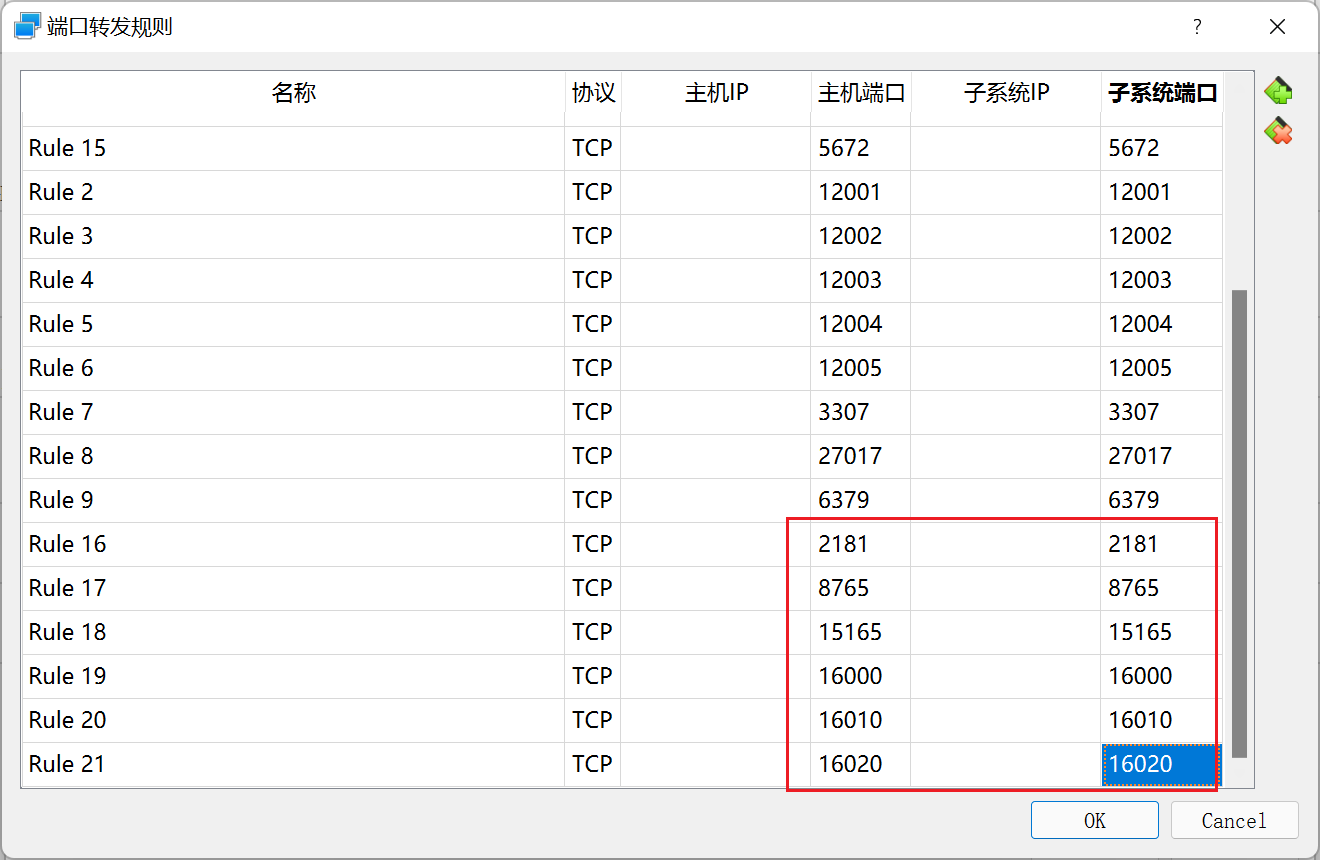
- 开放端口
我们要把Linux的2181、8765、15165、16000、16010、16020端口,映射到Windows的相应端口上面。
- 初始化Phoenix
运行命令,进入到Phoenix容器中,然后执行命令设置HBASE_CONF_DIR环境变量。
docker exec -it phoenix bash
export HBASE_CONF_DIR=/opt/hbase/conf/
接下来我们要连接Phoenix的命令行客户端。虽然IDEA也内置了Phoenix客户端,但是Bug挺多的,用着并不方便,所以我建议大家使用Phoenix自带的命令行客户端更好一些。而且我们要执行的SQL语句也并不多,命令行客户端已经足够用了。
/opt/phoenix-server/bin/sqlline.py localhost
三、创建逻辑库和数据表
- 创建逻辑库
为了存储数据,我们需要像操作MySQL一样,先创建逻辑库,然后定义数据表。在Phoenix的命令行客户端我们先来执行创建逻辑库的命令。
CREATE SCHEMA hxds;
USE hxds;
- 创建数据表
接下来我们要创建order_voice_text、order_monitoring和order_gps数据表。其中order_voice_text表用于存放司乘对话内容的文字内容;
CREATE TABLE hxds.order_voice_text(
"id" BIGINT NOT NULL PRIMARY KEY,
"uuid" VARCHAR,
"order_id" BIGINT,
"record_file" VARCHAR,
"text" VARCHAR,
"label" VARCHAR,
"suggestion" VARCHAR,
"keywords" VARCHAR,
"create_time" DATE
);
CREATE SEQUENCE hxds.ovt_sequence START WITH 1 INCREMENT BY 1;
CREATE INDEX ovt_index_1 ON hxds.order_voice_text("uuid");
CREATE INDEX ovt_index_2 ON hxds.order_voice_text("order_id");
CREATE INDEX ovt_index_3 ON hxds.order_voice_text("label");
CREATE INDEX ovt_index_4 ON hxds.order_voice_text("suggestion");
CREATE INDEX ovt_index_5 ON hxds.order_voice_text("create_time");
order_monitoring表存储AI分析对话内容的安全评级结果。
CREATE TABLE hxds.order_monitoring
(
"id" BIGINT NOT NULL PRIMARY KEY,
"order_id" BIGINT,
"status" TINYINT,
"records" INTEGER,
"safety" VARCHAR,
"reviews" INTEGER,
"alarm" TINYINT,
"create_time" DATE
);
CREATE INDEX om_index_1 ON hxds.order_monitoring("order_id");
CREATE INDEX om_index_2 ON hxds.order_monitoring("status");
CREATE INDEX om_index_3 ON hxds.order_monitoring("safety");
CREATE INDEX om_index_4 ON hxds.order_monitoring("reviews");
CREATE INDEX om_index_5 ON hxds.order_monitoring("alarm");
CREATE INDEX om_index_6 ON hxds.order_monitoring("create_time");
CREATE SEQUENCE hxds.om_sequence START WITH 1 INCREMENT BY 1;
order_gps表保存的时候代驾过程中的GPS定位。
CREATE TABLE hxds.order_gps(
"id" BIGINT NOT NULL PRIMARY KEY,
"order_id" BIGINT,
"driver_id" BIGINT,
"customer_id" BIGINT,
"latitude" VARCHAR,
"longitude" VARCHAR,
"speed" VARCHAR,
"create_time" DATE
);
CREATE SEQUENCE hxds.og_sequence START WITH 1 INCREMENT BY 1;
CREATE INDEX og_index_1 ON hxds.order_gps("order_id");
CREATE INDEX og_index_2 ON hxds.order_gps("driver_id");
CREATE INDEX og_index_3 ON hxds.order_gps("customer_id");
CREATE INDEX og_index_4 ON hxds.order_gps("create_time");
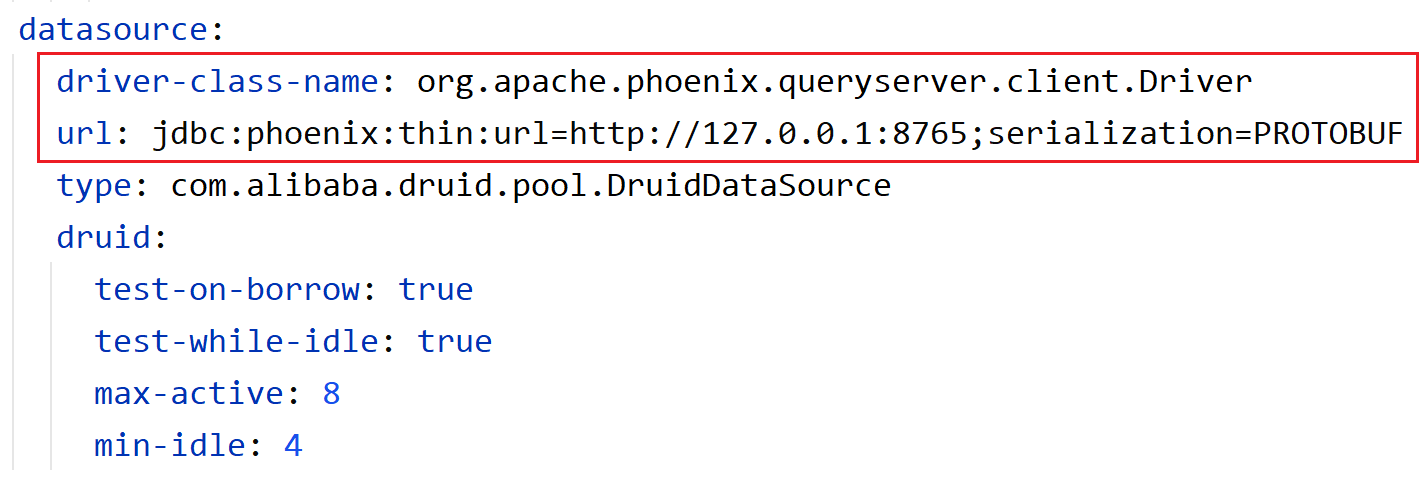
四、配置JDBC驱动
修改系统的application.yml文件,里面的JDBC驱动和URL路径都是为了连接Phoenix的。如果你用的是云主机,别忘了URL要写云主机的IP,而且还要在安全组里面把相关端口开放一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号