
利用Docker环境来使用MyCat管理MySQL集群
一、导入MyCat镜像
MyCat并不是数据库,它只是SQL语句的路由器而已。创建MyCat容器之前,我们先导入镜像文件。照例把镜像文件上传到/root目录,然后用命令导入镜像文件。
mycat.tar.gz 链接:https://share.weiyun.com/RGR4FdVA 密码:z8mz7t
docker load < mycat.tar.gz
二、设置MyCat配置文件
课程提供了MyCat配置文件的压缩包,你找到这个压缩包然后解压缩,我们要修改里面的配置文件。这些配置文件我也是从MyCat官网提供的MyCat压缩包中提取出来,你自己也可以提取。
MyCat配置文件.zip 链接:https://share.weiyun.com/SmhTrqqN 密码:ah79ne
我们先修改server.xml文件,操作较多,手册不详细列举了,大家注意看视频的操作。主要配置的就是MyCat帐户的用户名和密码,以及默认的逻辑库。
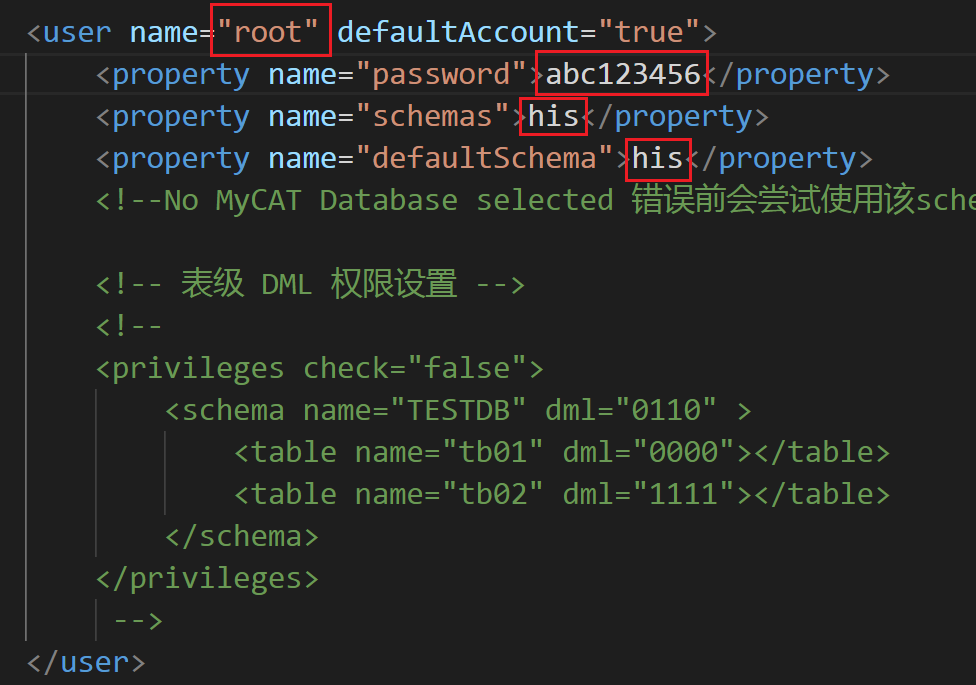
接下来,删除schema.xml文件原有的内容,覆盖上如下的内容,大家认真看这部分的操作和讲解。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="his" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="tb_action" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_customer" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_dept" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_goods" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_module" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_permission" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_role" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_user" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_rule" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_order" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_appointment" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_appointment_restriction" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_system" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_checkup_report" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_customer_location" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_flow_regulation" primaryKey="id" dataNode="dn1" type="global"/>
<table name="tb_customer_im" primaryKey="id" dataNode="dn1" type="global"/>
</schema>
<dataNode name="dn1" dataHost="ds_1" database="his" />
<dataHost name="ds_1" maxCon="1000" minCon="10" balance="1" writeType="0"
dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select 1</heartbeat>
<writeHost host="w1" url="172.18.0.2:3306" user="root" password="abc123456">
<readHost host="w1r1" url="172.18.0.3:3306" user="root" password="abc123456"/>
<readHost host="w1r2" url="172.18.0.4:3306" user="root" password="abc123456"/>
</writeHost>
<writeHost host="w2" url="172.18.0.5:3306" user="root" password="abc123456">
<readHost host="w2r1" url="172.18.0.6:3306" user="root" password="abc123456"/>
<readHost host="w2r2" url="172.18.0.7:3306" user="root" password="abc123456"/>
</writeHost>
</dataHost>
</mycat:schema>
三、创建MyCat容器
先创建/root/mycat/conf目录,然后把MyCat所有配置文件上传到该目录中。接下来我们通过Docker命令,创建MyCat容器。由于MyCat是用Java语言开发的中间件程序,它运行的时候需要的内存空间比较大,所以我们规定MyCat容器使用内存的上限为2GB。注意这只是上限,不是初始就占用了2GB的内存空间。
docker run -it -d --name mycat -p 8066:8066 -p 9066:9066 \
--net mynet --ip 172.18.0.8 -m 2048m \
-v /root/mycat/conf:/opt/mycat/conf \
-v /root/mycat/logs:/opt/mycat/logs \
-e TZ=Asia/Shanghai --privileged=true \
mycat:1.6.7.4
四、测试MyCat路由SQL语句
我们在MyCat的his逻辑库中随便打开一个数据表,里面的数据展示和操作与普通的MySQL数据表完全是一致的。但是Java程序要用SQL语句和MyCat打交道,所以我们来看看MyCat转发SQL语句的效果吧。
我们先在MyCat上面执行一个SQL语句,看看INSERT语句是否能转发给主节点,然后数据同步到其他5个节点。
INSERT INTO tb_system
SET id = 3,
item = "测试",
value = "test";
接下来我们执行UPDATE语句,看看MyCat是不是依旧能正常转发SQL语句。
UPDATE tb_system
SET item = "demo"
WHERE id = 3 ;
最后我们来运行SELECT语句,看看MyCat能不能查询出来数据。
SELECT * FROM tb_system;
五、测试MyCat对故障节点的管理
上面的几个SQL语句,MyCat都能正常转发给MySQL节点去执行。下面我们来搞点刺激的,比如说我把6个节点挂掉4个,我看看MyCat还能不能正常操作了。当然了,也不能随便挂掉节点。假如两个主节点挂掉了,那么其余4个读节点自然也就用不了,所以我们的MySQL集群最多能支持挂掉1个主节点和3个从节点。比如说我让MySQL_1、MySQL_2、MySQL_3、MySQL_5节点挂掉,仅存MySQL_4和MySQL_6节点。
我们现在让MyCat执行DELETE语句,看看是不是还能正常运行。如果成功执行了SQL语句,我们一定要去MySQL_4节点查看数据是不是被删除了。
DELETE FROM tb_system
WHERE id = 3;
我们让MyCat执行SELECT查询语句,看看仅存的读节点是否还能正常工作。
SELECT * FROM tb_system;
最后我们把挂掉的4个节点上线,再看看它们的数据同步情况是不是最终达成一致。大家尽可放心,MyCat心跳检测非常的给力,那些宕机的MySQL上线之后,MyCat检测到它们能应答心跳检测之后,就会把SQL语句转发给它们。
六、关于数据库集群读写一致性的思考
我们使用主从同步机制搭建出来的MySQL集群,属于弱一致性的集群。也就是说在非常特殊的场景下,我们写入的数据和读取出来的数据可能不一致。我把会出现读写不一致的场景归纳出来了,我们一起看一下。
- 写入和查询间隔时间太短
假设我们要执行的INSERT语句发送给了MySQL_1节点执行,但是紧接着马上执行了SELECT语句,这个查询语句被MyCat转发给MySQL_2执行。假设INSERT和SELECT语句之间的时间间隔短到1毫秒,导致MySQL_2还没有同步写入的数据,查询语句就来了,自然是查询不到刚刚插入的数据。
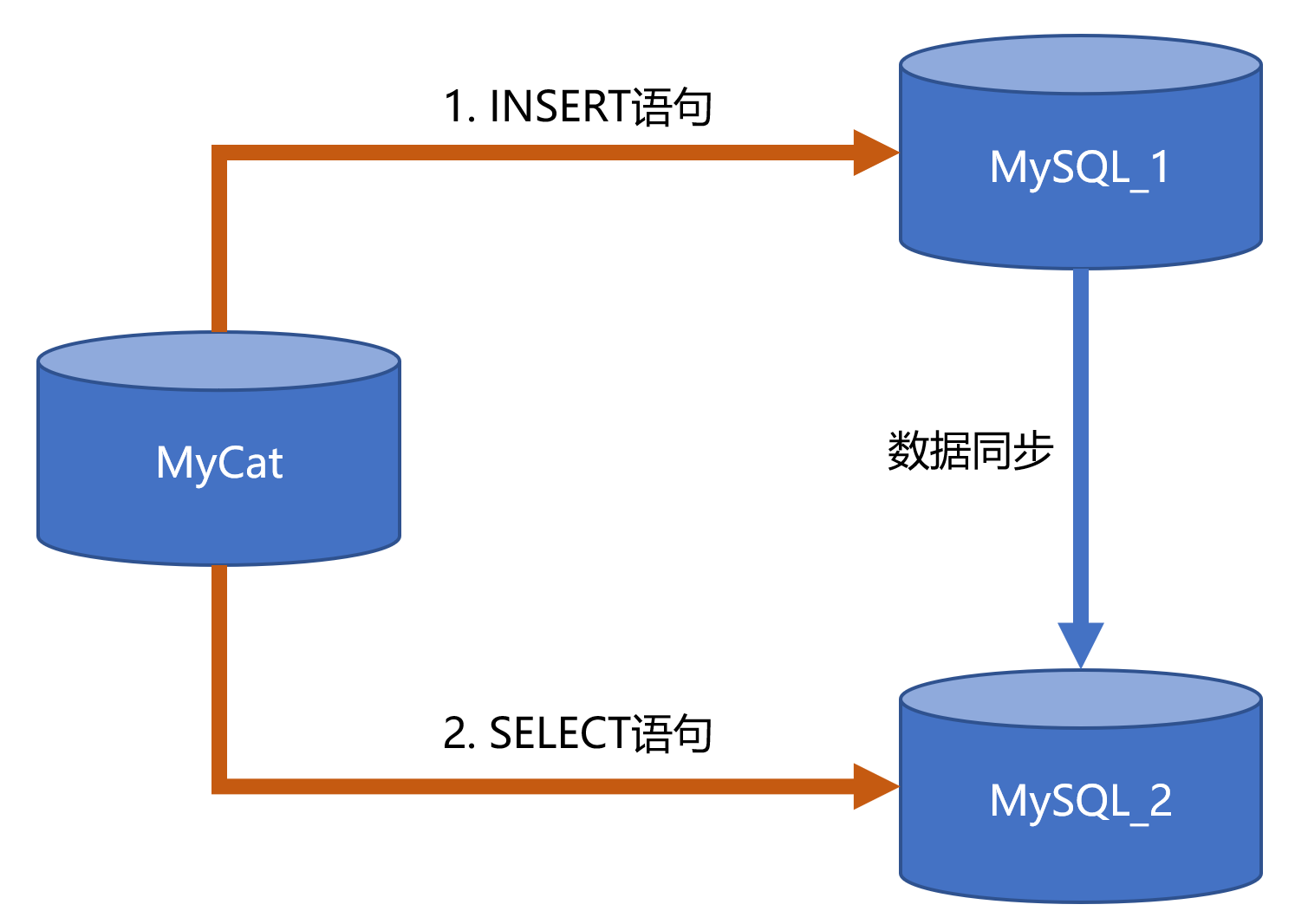
上面描述的情况属实存在,但是仅限于写入和查询间隔的时间非常短,短到毫秒级别,这个限定条件还是很苛刻的很难达到。
- 主从同步失效
当MySQL_1和MySQL_2的主从同步失效,MySQL_2节点依然能应答MyCat心跳检测,所以MyCat依然认为MySQL_2节点是正常的节点。还是刚才的例子,MySQL_1写入数据后,因为主从同步失效,导致MySQL_2节点上没有新写入的数据,我们也就查询不到刚写入的数据了。那么有没有解决办法呢?我们只能写监控程序,每隔1秒钟执行一次show slave status语句,查看结果是不是包含两个YES字样。如果数据同步失效,就立即发送告警邮件,由运维人员及时处理。
也许有人好奇什么情况会导致主从同步失效?软硬件都有可能,比如说MyCat、MySQL_1和MySQL_2各自处在不同的机房中。MyCat与MySQL_1和MySQL_2的网络是通畅的,但是MySQL_1和MySQL_2机房之间网络却是不通的,可能是网线断了,也可能是交换机软件的故障。反正网络不通,主从同步自然也就失效了。
七、数据库集群强一致性方案
既然主从同步是弱一致性的数据库集群,那么有没有有强一致性的数据库集群呢?当然有,那就是PXC集群方案。在PX集群中用的是Percona数据库(MySQL衍生版),每个Percona节点在写入数据的时候,一定要保证集群中其他节点都成功同步了数据,才算写入成功。如果有任何一个节点数据同步失败,所有节点就会回滚事物,删除刚刚同步的数据。想要了解PXC集群方案的同学,可以看我那门《Docker环境下的前后端分离部署与运维》实战课,肯定会让你打开认知的新领域。
既然PXC集群能保证所有节点数据的一致性,为什么我们不用PXC集群方案呢?数据强一致性是以牺牲写入性能为代价的。每次写入数据都要等待其他节点同步数据成功,势必延长了写入的时间。如果PXC集群的Percona节点越多,同步数据的时间也就越长。因此PXC集群有个铁律:节点数量不应该超过15个。这个数量级的MySQL集群,应对高并发的情况压力还是很大的,除非金融领域对数据的一致性非常看重之外,宁愿牺牲读写性能也要保证数据的一致性,其他领域的项目更倾向于有一个快速读写的速度。即便出现了数据读写不一致的小概率事件,可以由客服先安抚客户,赠与代金券,然后让技术人员去解决故障。
其实呢,就算淘宝和京东这样的电商巨头也没法保证数据的读写一致性。咱们抛开主从同步和PXC集群不谈,电商网站和银行系统有各自的数据库系统。这就会导致电商项目和银行系统分别处在不同的数据库事务中,没法做到一体式的回滚,所以可能会出现银行数据库已经回滚了,但是电商网站的数据库没有回滚,数据也就不一致了。最后还是得由技术人员出马解决,所以同学们也就不用纠结数据不一致这个小概率事件了。程序员解决不了的事情,就交给客服和运维去处理吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号