


20172315 2018-2019-1 《程序设计与数据结构》实验二报告
20172315 2018-2019-1 《程序设计与数据结构》实验二报告
课程:《程序设计与数据结构》
班级: 1723
姓名: 胡智韬
学号:20172315
实验教师:王志强
实验日期:2018年11月2日
必修/选修: 必修
1.实验内容
实验二-1-实现二叉树
参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验二 树-2-中序先序序列构造二叉树
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树
用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台

实验二 树-3-决策树
自己设计并实现一颗决策树
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验二 树-4-表达式树
输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分)
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验二 树-5-二叉查找树
完成PP11.3
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验二 树-6-红黑树分析
参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
(C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
课下把代码推送到代码托管平台
2. 实验过程及结果
实验(1)

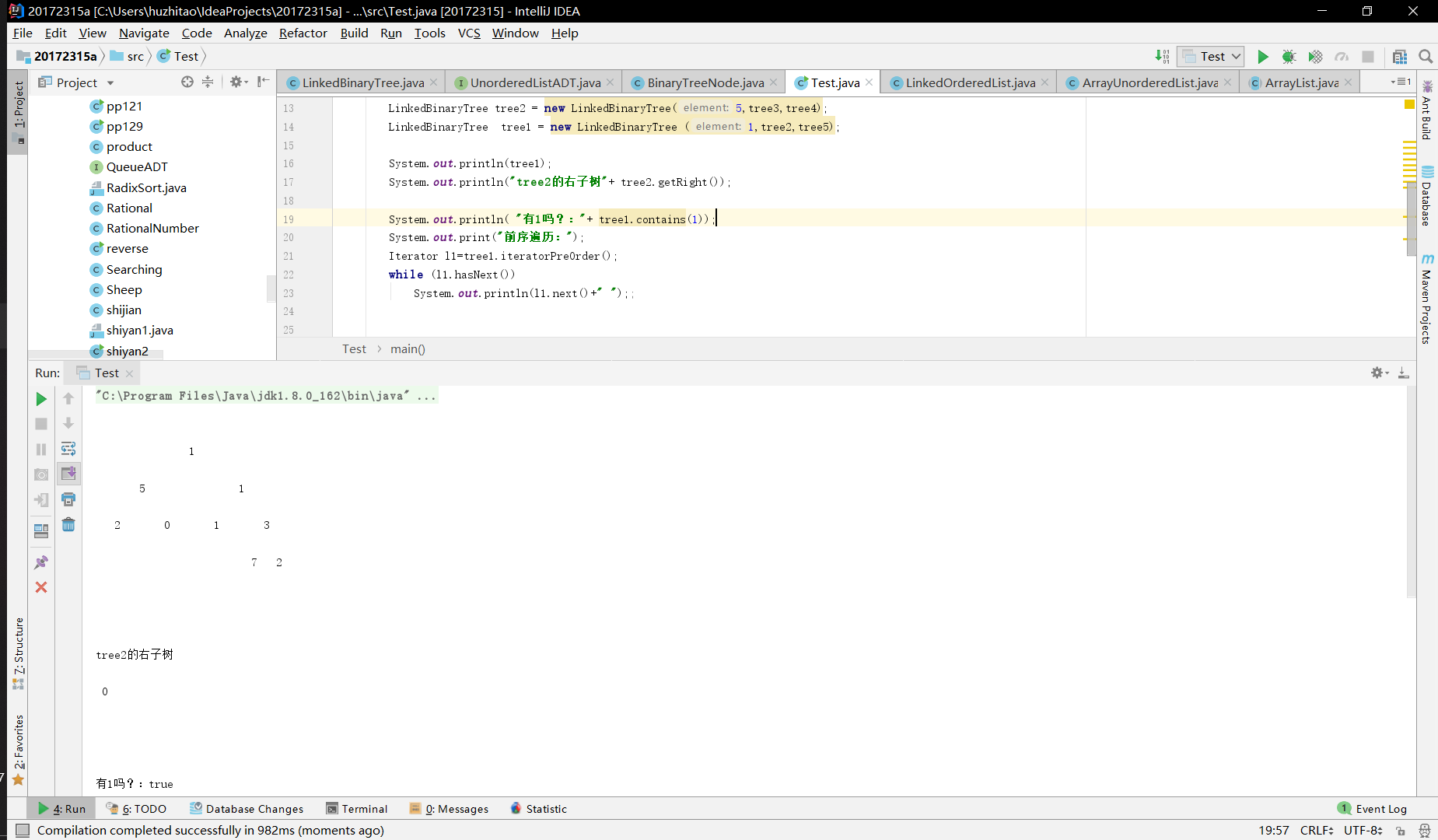
实验(2)
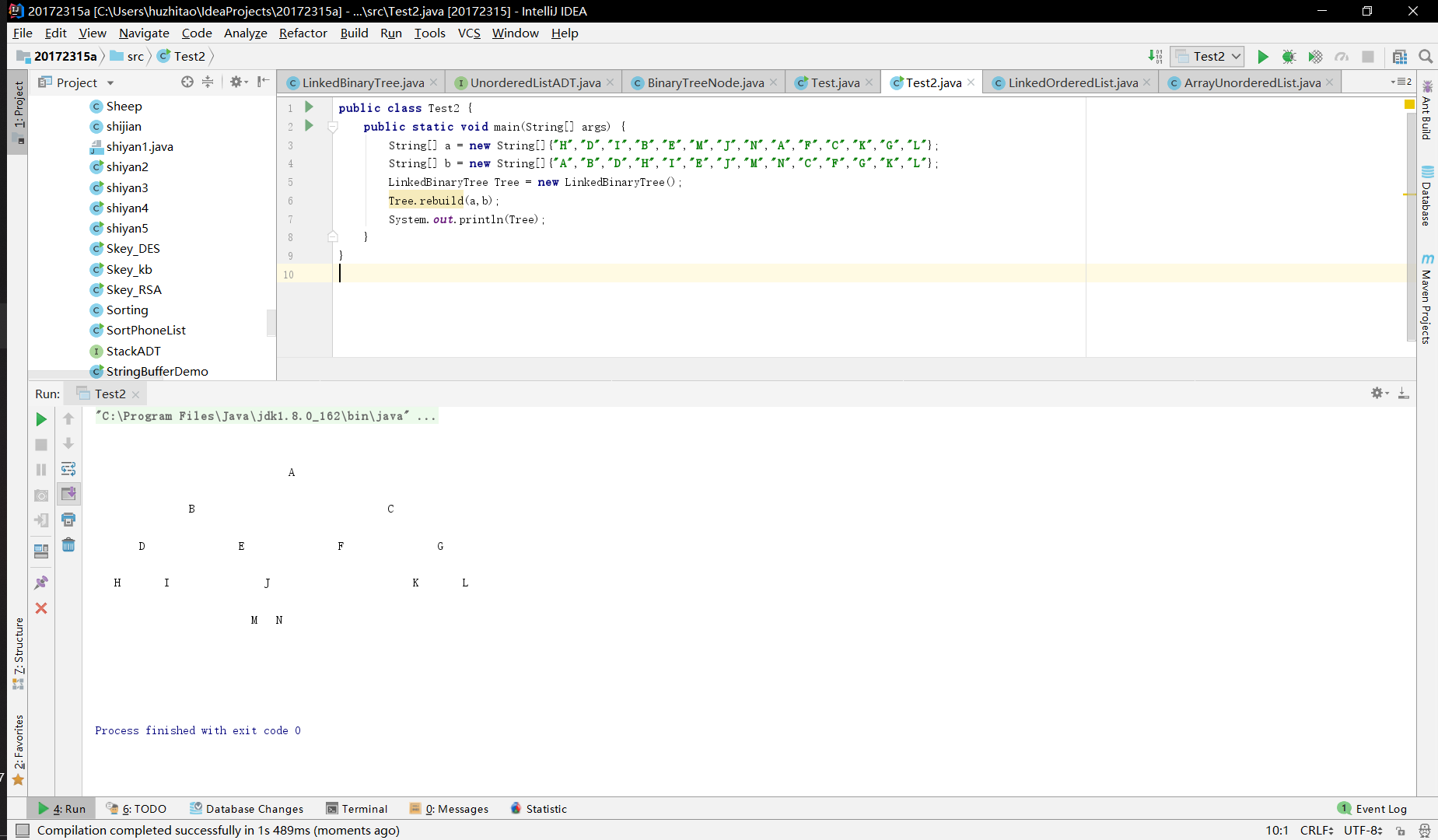
实验(3)

实验(4)
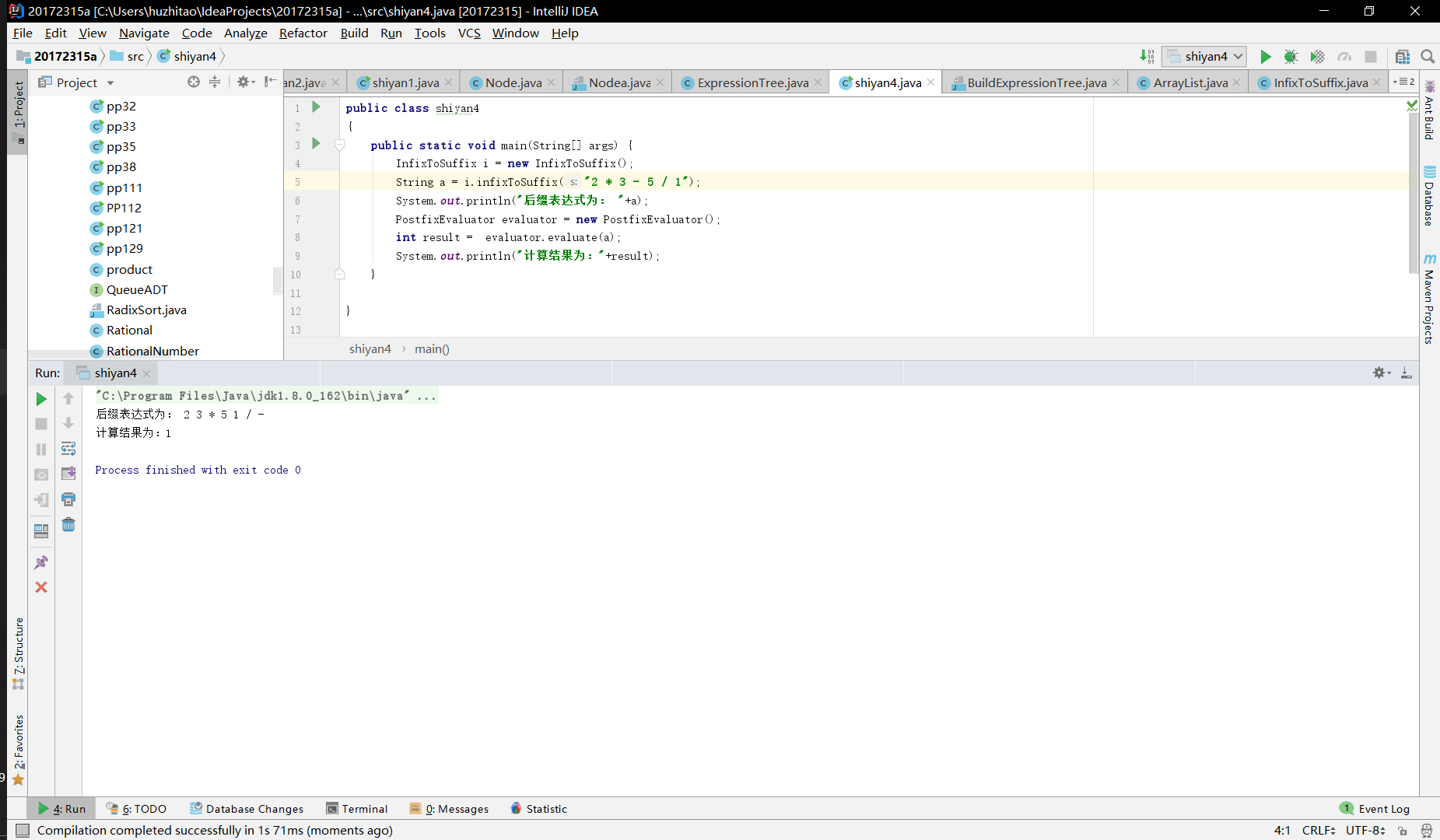
实验(5)
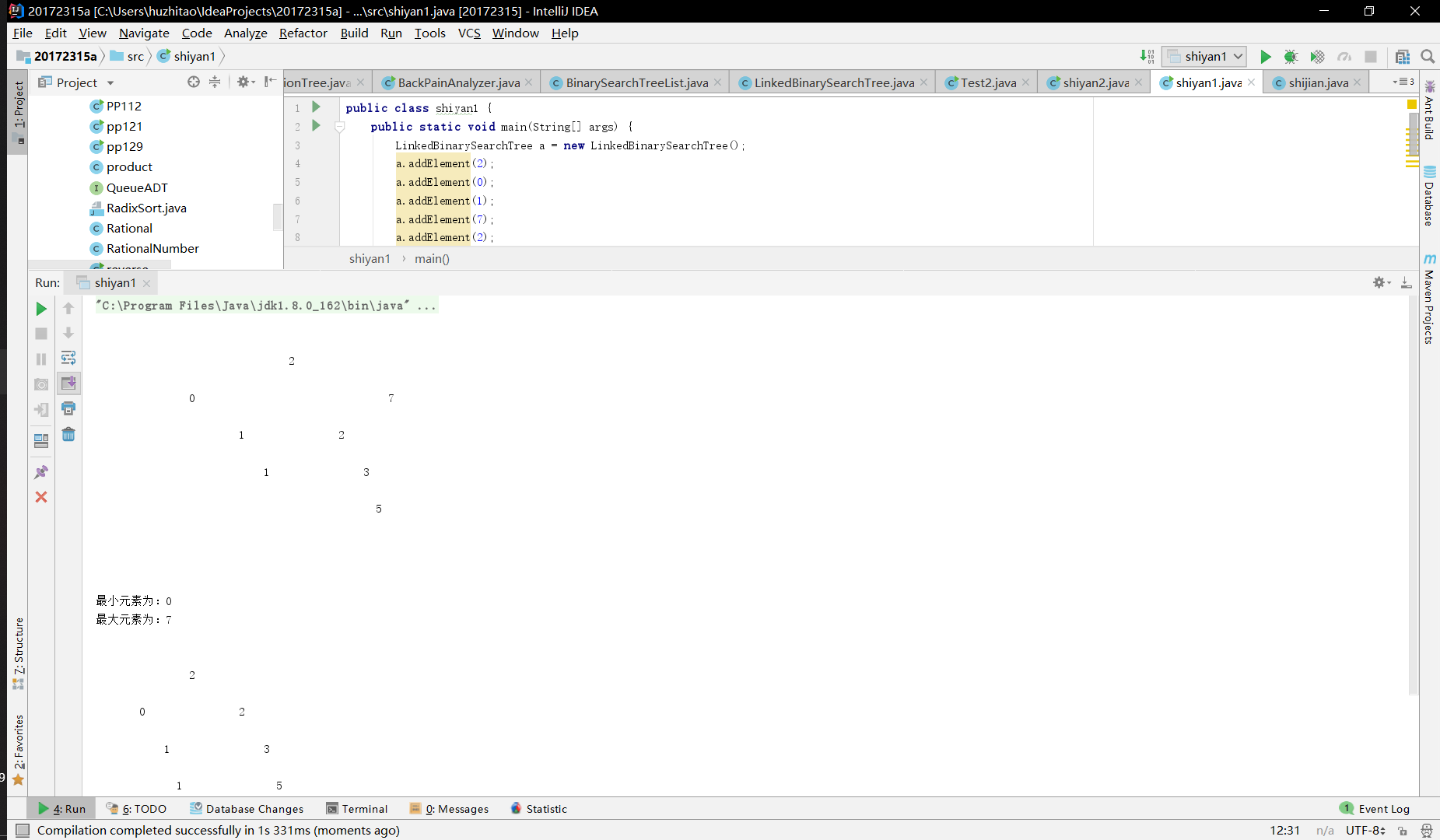
实验(6)
hashmap:
Entry是HashMap中的一个静态内部类。代码如下
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}

简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
public HashMap(int initialCapacity, float loadFactor) {
//此处对传入的初始容量进行校验,最大不能超过MAXIMUM_CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现
}
从上面这段代码我们可以看出,在常规构造器中,没有为数组table分配内存空间(有一个入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组
treemap:
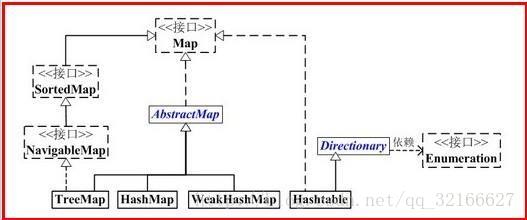
在详细介绍TreeMap的代码之前,我们先建立一个整体概念。
TreeMap是通过红黑树实现的,TreeMap存储的是key-value键值对,TreeMap的排序是基于对key的排序。
TreeMap提供了操作“key”、“key-value”、“value”等方法,也提供了对TreeMap这颗树进行整体操作的方法,如获取子树、反向树。
1 默认构造函数
public TreeMap() {
comparator = null;
}
2 带比较器的构造函数
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
3 带Map的构造函数,Map会成为TreeMap的子集
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
该构造函数会调用putAll()将m中的所有元素添加到TreeMap中。putAll()源码如下:
public void putAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
从中,我们可以看出putAll()就是将m中的key-value逐个的添加到TreeMap中。
4 带SortedMap的构造函数,SortedMap会成为TreeMap的子集
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
该构造函数不同于上一个构造函数,在上一个构造函数中传入的参数是Map,Map不是有序的,所以要逐个添加。
而该构造函数的参数是SortedMap是一个有序的Map,我们通过buildFromSorted()来创建对应的Map。
3. 实验过程中遇到的问题和解决过程
-
问题1:在做实验4时不知道该如何写
-
问题1解决方案:可以利用二叉树求得后缀表达式,首先利用中缀表达式构造二叉树,数字是叶子节点,操作符为根节点。每次找到“最后计算”的运算符,作为当前根节点,运算符左侧表达式作为左节点,右侧表达式作为右节点,然后递归处理(http://www.xuebuyuan.com/388108.html)。9+(3-1)*3+10/2对应的二叉树的构造过程如下图所示:
![]()
此二叉树做后序遍历就得到了后缀表达式。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号