《操作系统原理》课堂测试2及知识整理
《操作系统原理》课堂测试2
1.(1分)嵌入式计算机通常运行在(B)操作系统上。A
(A)实时
(B) Windows XP
(C)网络
(D)集群
要点概括:
2.(1分)一个正在执行的应用程序最好被描述成为(B)。
(A)内核
(B)进程
(C)线程
(D)系统调用
进程
3.(1分)以下哪个是操作系统中有效的进程转换?(A).B
(A)唤醒:就绪态→运行态
(B) I/0事件到:运行态→阻塞态
(C)阻塞:就绪态→阻塞态
(D)时间片用完:就绪态→阻塞态
改错:
A: 唤醒:阻塞态→就绪态
C:阻塞:运行态→阻塞态
D时间片用完:运行态→就绪态
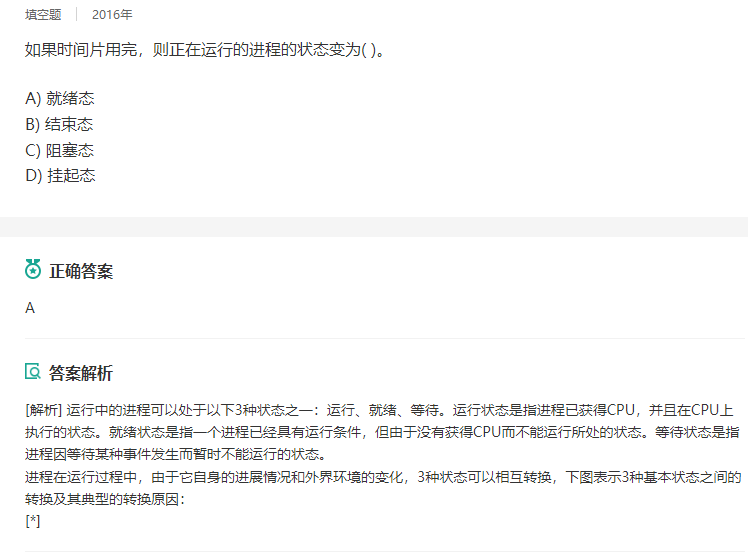
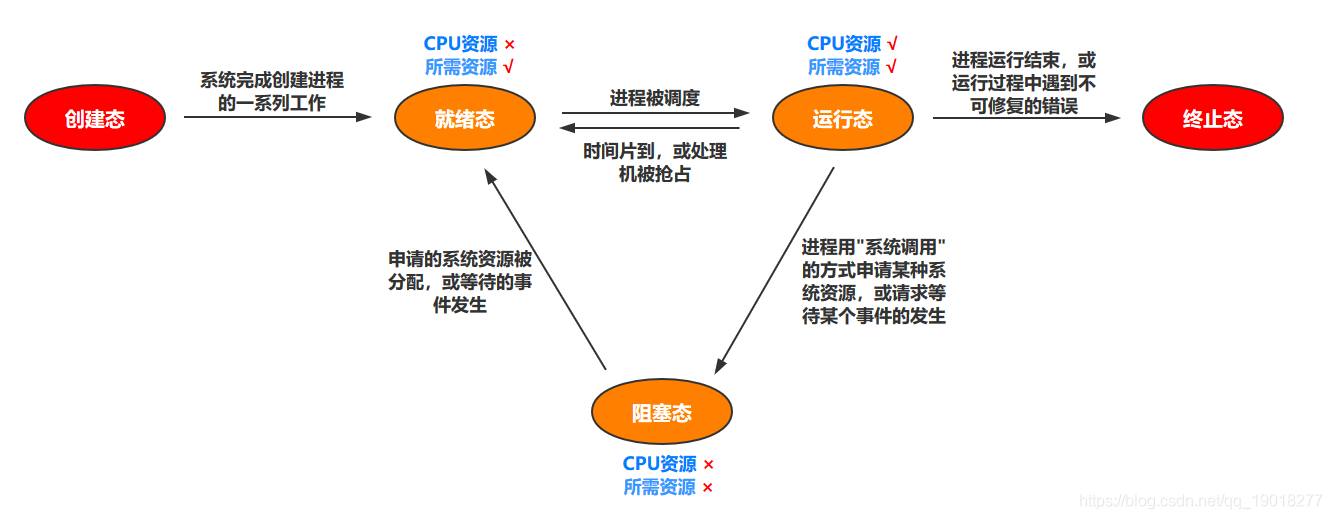
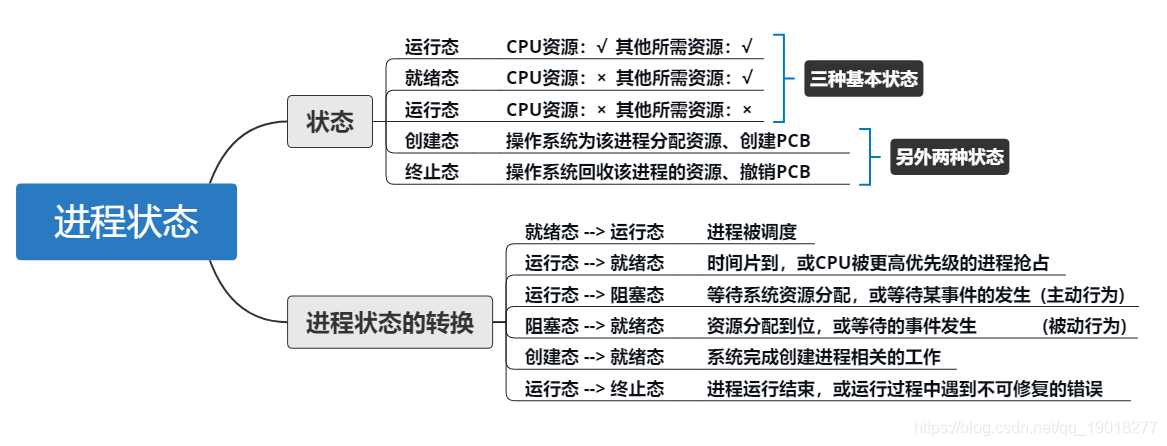
4.(1分)在一个CPU调度采用时间片轮转调度算法的系统中,当一个进程
无法在给定的一个时间片内完成其计算任务时,以下哪个是正确的?(C)
(A)该进程将自行终止
(B)该进程将由操作系统终止
(C)该进程状态由运行态变为就绪态
(D)以上均不是
如上题D选项同义
5.(1分)当一个用户进程正运行在单一CPU系统上时,以下除了(A)以外都是正确的。D
(A)内核未处于运行态
(B)磁盘可以将数据写到内存
(C)如果访问某些内存地址CPI将产生异常(软中断)
(D)CPU处于内核(系统)模式
关于用户态向内核态的切换-------
用户准备好参数,通过触发软中断,CPU进入内核态,执行操作系统准备好的中断处理程序。由于用户只能改变参数,而不能改变处理程序本身,内核保护自身不被破坏。
用户进程在运行,应该为CPU处于用户模式
D改错:CPU处于用户模式
则A:用户模式下内核未处于运行态
CPU是在两种不同的模式下运行的:
-
Kernel Mode
在内核模式下,代码具有对硬件的所有控制权限。可以执行所有CPU指令,可以访问任意地址的内存。内核模式是为操作系统最底层,最可信的函数服务的。在内核模式下的任何异常都是灾难性的,将会导致整台机器停机。 -
User Mode
在用户模式下,代码没有对硬件的直接控制权限,也不能直接访问地址的内存。程序是通过调用系统接口(System APIs)来达到访问硬件和内存。在这种保护模式下,即时程序发生崩溃也是可以恢复的。在你的电脑上大部分程序都是在用户模式下运行的。
面所说的两种模式不仅仅是字面上的区别,它们是受CPU严格制约的。如果在用户模式下,程序尝试做些其权限以外的事情,比如说,执行一条高权限的CPU指令,修改其被禁止访问的内存,这时一个可捕获的异常就会抛出。但这只会导致这个倒霉的应用程序崩溃,而不会让你的整个系统崩溃。这就是用户模式的意义所在。
x86 CPU提供4种保护层级: 0, 1, 2 and 3. 实际上,只用0级(内核)和3级(用户程序)被使用到了。
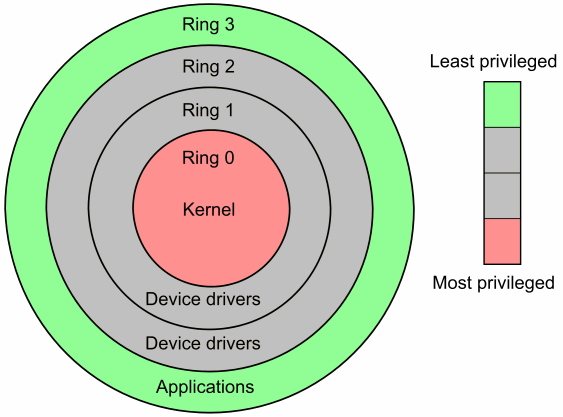
参考链接:https://blog.csdn.net/qq_35191331/article/details/75557567
6.(1分)当一个进程通过使用fork()系统调用创建时,父进程的(D)属性不能被子进程继承。B
(A)进程地址空间
(B)进程标识符
(C)用户标识符
(D)打开的所有文件
子进程继承父进程
1.用户号UIDs和用户组号GIDs 用户标识符即UID---userID,用于说明拥有该进程的用户 用户组标识符即GID GID---groupID
2.环境Environment
3.堆栈 堆栈是进程地址空间的部分()
4.共享内存 进程间通信——共享内存(Shared Memory)
5.打开文件的描述符
(不同的文件描述符对应相同的文件表。
文件表加节点表就是物理文件。
文件描述符隶属于进程数据的一部分,
换言之各个进程的文件描述符彼此独立)
fork 子进程如何不继承父进程打开的文件描述符(面试题)
fork vfork clone 三者的区别?
vfork
vfork系统调用不同于fork,用vfork创建的子进程与父进程共享地址空间,也就是说子进程完全运行在父进程的地址空间上,如果这时子进程修改了某个变量,这将影响到父进程。
因此,上面的例子如果改用vfork()的话,那么两次打印a,b的值是相同的,所在地址也是相同的。
但此处有一点要注意的是用vfork()创建的子进程必须显示调用exit()来结束,否则子进程将不能结束,而fork()则不存在这个情况。
Vfork也是在父进程中返回子进程的进程号,在子进程中返回0。
用 vfork创建子进程后,父进程会被阻塞直到子进程调用exec(exec,将一个新的可执行文件载入到地址空间并执行之)或exit。vfork的好处是在子进程被创建后往往仅仅是为了调用exec执行另一个程序,因为它就不会对父进程的地址空间有任何引用,所以对地址空间的复制是多余的 ,因此通过vfork共享内存可以减少不必要的开销。
系统调用fork()和vfork()是无参数的,而clone()则带有参数。fork()是全部复制,vfork()是共享内存,而clone()是则可以将父进程资源有选择地复制给子进程,而没有复制的数据结构则通过指针的复制让子进程共享,具体要复制哪些资源给子进程,由参数列表中的clone_flags来决定。另外,clone()返回的是子进程的pid。
参考 https://blog.csdn.net/u012675539/article/details/51093770
6.执行时关闭(Close-on-exec)标志
7.信号(Signal)控制设定
8.进程组号
9.当前工作目录
10.根目录
11.文件方式创建屏蔽字
12.资源限制
13.控制终端
子进程独有
①进程号PID
②不同的父进程号
③自己的文件描述符和目录流的拷贝
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
④子进程不继承父进程的进程正文(text),数据和其他锁定内存(memory locks)
⑤不继承异步输入和输出
⑥父进程和子进程拥有独立的地址空间和PID参数。
总的来说,子进程从父进程继承了用户号和用户组号,用户信息,目录信息,环境(表),打开的文件描述符,堆栈,(共享)内存等。
经过fork()以后,父进程和子进程拥有相同内容的代码段、数据段和用户堆栈,就像父进程把自己克隆了一遍。事实上,父进程只复制了自己的PCB块。而代码段,数据段和用户堆栈内存空间并没有复制一份,而是与子进程共享。只有当子进程在运行中出现写操作时,才会产生中断,并为子进程分配内存空间。由于父进程的PCB和子进程的一样,所以在PCB中断中所记录的父进程占有的资源,也是与子进程共享使用的。这里的“共享”一词意味着“竞争”
原文链接:https://blog.csdn.net/feiyagogogo/article/details/79671398
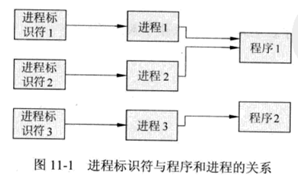
进程标识符(PID)
进程标识符(PID)是一个进程的基本属性,其作用类似于每个人的身份证号码。根据进程标识符,用户可以精确地定位一个进程。
一个进程标识符唯一对应一个进程,而多个进程标识符可以对应同一个程序。如下图所示:
7.(1分)创建子进程时,在子进程的执行或地址空间方面,下列哪项是可能的?(D)。
(B)子进程中加载了一个新程序
(A)子进程与父进程同时运行
(C)子进程是父进程的副本
(D)以上均有可能
C:
Unix环境高级编程中8.3节中说,“子进程是父进程的副本。例如,子进程获得父进程数据空间、堆和栈的副本。注意,这是子进程所拥有的副本。父进程和子进程并不共享这些存储空间部分。父进程和子进程共享正文段。”
书中还预留了例子说明子进程对变量所做的改变并不影响父进程中该变量的值。
fork后子进程只是获得了父进程的副本,所有变量的变更都只在各自进程中有效。
参考:https://blog.csdn.net/zn2857/article/details/78791064
8.(1分)当一个正在运行的进程X请求从磁盘上的文件F读取数据块时,0S将(D)。
(A)保存X的当前状态
(B)为F的数据块调度一次磁盘请求
(C)加载另一个处于就绪态的进程Y
(D)以上均是
A:I/O中断由I/O控制器产生,用于发信号通知一个操作的正常完成或各种错误条件(书本P6);
P8 1.42中断处理 “处理器需要准备把控制权转交到中断程序。首先,需要保存从中断点恢复当前程序所需要的信息,要求的最少信息包括程序状态字(PSW)和保存在程序计数器(PC)中的下一条要执行的指令地址,它们被压入系统控制栈。”
B:磁盘请求属于I/O请求
C:就绪态(通俗点讲:万事俱备,只欠CPU)
9. 1分)对于单一处理器系统, 以下哪个表述是正确的?(A)。B
(A)进程等待执行的时间很长
(B)永远不会有多个正在运行的进程
(C)输入输出总是会导致CPU速度减慢
D)进程调度算法总是最优的
A:与进程调度算法优劣有关
在单处理器操作系统中,运行状态最多1个,最少0个;
等待(阻塞)状态最多N个,最少N-1个;
就绪状态最多N-1个,最少0个。
10.(1分)当UNIX shell(如bash)执行外部命令(如ls)时,它通常会执行
(C)系统调用?
(A) fork
(B) wait
(C)A和B
(D)以上均不是
外部命令:指的是Linux系统中能够完成特定功能的脚本文件或二进制程序,每个外部命令对应了系统中的一个文件,是属于Shell解释器程序之外的命令,所以称为外部命令。Linux系统必须知道外部命令对应的文件位置,才能够由Shell加载并执行。
Linux系统默认会将存放外部命令、程序的目录(如/bin、/usr/bin、/usr/local/bin等)添加到用户的“搜索路径”中,当使用位于这些目录中的外部命令时,用户不需要指定具体的位置。因此在大多数情况下,不用刻意去分辨内部、外部命令,其使用方法是基本类似的。
外部命令就是由Shell副本(新的进程)所执行的命令,基本的过程如下:
a. 建立一个新的进程(fork)。此进程即为Shell的一个副本。
b. 在新的进程里,在PATH变量内所列出的目录中,寻找特定的命令。
/bin:/usr/bin:/usr/X11R6/bin:/usr/local/bin为PATH变量典型的默认值。
当命令名称包含有斜杠(/)符号时,将略过路径查找步骤。
c. 在新的进程里,以所找到的新程序取代执行中的Shell程序并执行。
d. 程序完成后,最初的Shell会接着从终端读取下一条命令,和执行脚本里的下一条命令。
sleep 和wait的区别
在 shell 中使用 wait 是在等待上一批或上一个脚本执行完(即上一个的进程终止),再执行wait之后的命令。
sleep是使系统休眠一定的时间之后再去执行下面的任务。
语法
wait [进程号或作业号]
wait 22 等待22进程完在执行下面的
wait %1 第一个作业
1
2
如果wait后面不带任何的进程号或作业号,那么wait会直至当前shell中进程的所有子进程都执行结束后,才继续执行下一步。
原文链接:https://blog.csdn.net/thermal_life/article/details/111309562
11. (1分)进程之间的上下文切换由(B)执行。A
(A)分派程序(dispatcher)
(B)中断处理程序
(C)线程管理程序
(D)以上均不是
链接:https://www.nowcoder.com/questionTerminal/13e82348a0a84428b0a9c43ccea21e5b?toCommentId=1155332
来源:牛客网
分派程序(dispatcher):每次进程切换时都要使用的一个模块,用于将CPU控制交给由低级调度器(short-term scheduler) 所选的进程。功能包括1)切换上下文;2)切换到用户模式;3)跳转用户程序的合适位置来重启程序。
分派延迟(dispatch latency):dispatcher停止一个进程并启动另一个进程所用的时间。
另外:关于三种调度器 进程调度https://www.cnblogs.com/lcchuguo/p/4585291.html
于是,这些被保存在大容量存储设备上等待运行。
12.(1分)当一个进程(D),其状态由就绪变为运行。
(A)被中断
(B)执行一次1/0事件
(C)完成一次I/0事件
(D)被分派程序调度
分派程序(dispatcher):每次进程切换时都要使用的一个模块,用于将CPU控制交给由低级调度器(short-term scheduler) 所选的进程。
D:被调度的进程即变为运行态
13.(1分)当一个进程(A),其状态由运行变为阻塞。B
(A)被中断
(B)执行一次I/0事件
(C)完成一次I/0事件
(D)被进程调度程序分派
C:完成一次I/O事件,进程 阻塞态→就绪态
A:被中断打断的进程会处于一个什么状态?
2.如果由于其他的因素造成的中断的话,应该会转入就绪状态。
14.(1分)进程的上下文切换时间是操作系统开销。上下文切换开销取决于以下若干因素,除了( B)。
(A)操作系统和 PCB的复杂程度
(B)开源操作系统
(C)每个CPU的寄存器组数
(D)同时加载的上下文数量
显然选B,
引起上下文切换的原因有哪些?
对于抢占式操作系统而言, 大体有几种:
1、当前任务的时间片用完之后,系统CPU正常调度下一个任务;
2、当前任务碰到IO阻塞,调度线程将挂起此任务,继续下一个任务;
3、多个任务抢占锁资源,当前任务没有抢到,被调度器挂起,继续下一个任务;
4、用户代码挂起当前任务,让出CPU时间;
5、硬件中断;
进程上下文切换开销都有哪些
那么上下文切换的时候,CPU的开销都具体有哪些呢?开销分成两种,一种是直接开销、一种是间接开销。
直接开销就是在切换时,cpu必须做的事情,包括:
- 1、切换页表全局目录
- 2、切换内核态堆栈
- 3、切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
- ip(instruction pointer):指向当前执行指令的下一条指令
- bp(base pointer): 用于存放执行中的函数对应的栈帧的栈底地址
- sp(stack poinger): 用于存放执行中的函数对应的栈帧的栈顶地址
- cr3:页目录基址寄存器,保存页目录表的物理地址
- ......
- 4、刷新TLB
- 5、系统调度器的代码执行
间接开销主要指的是虽然切换到一个新进程后,由于各种缓存并不热,速度运行会慢一些。如果进程始终都在一个CPU上调度还好一些,如果跨CPU的话,之前热起来的TLB、L1、L2、L3因为运行的进程已经变了,所以以局部性原理cache起来的代码、数据也都没有用了,导致新进程穿透到内存的IO会变多。 其实我们上面的实验并没有很好地测量到这种情况,所以实际的上下文切换开销可能比3.5us要大。
想了解更详细操作过程的同学请参考《深入理解Linux内核》中的第三章和第九章。
参考链接 标题:进程/线程上下文切换会用掉你多少CPU?
https://zhuanlan.zhihu.com/p/79772089?utm_source=wechat_session
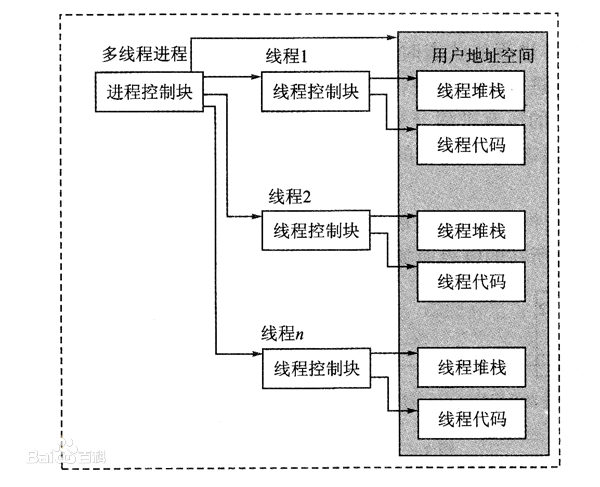
15.(1分)(C)信息存储在线程控制块(TCB)中。B
(A)打开的文件列表
(B)堆栈指针
(C)内存映射表
(D)线程所有者ID
线程控制块(Thread Control Block,TCB)是与进程的控制块(PCB)相似的子控制块,只是TCB中所保存的线程状态比PCB中保存少而已。
来源——百度百科
16.(1分)对于进程和线程来说以下哪个表述是正确的?(B)。
(A)进程中的线程共享同一堆栈
(B)进程中的线程共享相同的文件描述符
(C)进程中的线程共享相同的寄存器值
(D)以上均不是
线程共享的环境包括:
进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理器、进程的当前目录和进程用户ID与进程组ID。
每个线程都有自己的线程ID,这个ID在本进程中是唯一的。进程用此来标 识线程。
由于线程间是并发运行的,每个线程有自己不同的运行线索,当从一个线
3.线程的堆栈 (A选项)X
堆栈是保证线程独立运行所必须的。
由于同一个进程中有很多个线程在同时运行,可能某个线程进行系统调用后设置了errno值,而在该 线程还没有处理这个错误,另外一个线程就在此时被调度器投入运行,这样错误值就有可能被修改。所以,不同的线程应该拥有自己的错误返回码变量。
由于每个线程所感兴趣的信号不同,所以线程的信号屏蔽码应该由线程自己管理。但所有的线程都 共享同样的信号处理器。
由于线程需要像进程那样能够被调度,那么就必须要有可供调度使用的参 数,这个参数就是线程的 优先级。
17. (1分)线程控制块(C)D
(A)由父进程管理
(B)包含与进程控制块相同的信息
(C)具有与进程控制块相同的结构
(D)不包括有关父进程资源分配的信息
进程和线程的区别:
内核中使用了一个进程控制块(PCB)和一个线程控制块(TCB),以便在委托给它们的CPU上有时间' - 通常不会。 PCB将有一个或多个TCB链接到它。 TCB描述一个执行上下文(例如堆栈指针),一个PCB环境上下文(例如,内存段和权限)。
7-10 线程的实现
三种实现方式:
用户线程,在用户空间实现,OS看不到,由应用程序的用户线程库来管理;POSIX Pthreads, Mach C-threads
内核线程,在内核中实现,OS管理的;Windows
轻量级进程lightweight process:内核中实现,支持用户线程。Solaris, Linux
用户线程与内核线程间,可以是多对一,一对一,多对多。
在用户空间实现的线程机制,不依赖于OS内核,有一组用户级的线程库函数来完成线程的管理,包括创建、终止、同步和调度等。
使用用户态线程的优缺点:
优点:OS只能看到线程所属的进程,可用不支持线程技术的多进程OS,每个进程都有私有的TCB列表来跟踪记录各个线程的状态信息(PC, 栈指针,寄存器),TCB由线程库函数来维护;切换线程也由线程库函数完成,无用户态/核心态切换,速度快;每个进程由自定义的线程调度算法。灵活。
缺点:一个线程发起系统调用而阻塞,那整个进程都在等待(OS只能判断进程);一个线程开始运行后,除非主动交出CPU使用权,否则所在进程中的其他线程都无法运行;由于时间片分给进程,多线程时时间片更少会慢。
内核线程,OS内核来完成线程的创建终止和管理。OS的调度单位不再是进程而是线程。进程主要完成资源的管理。
内核维护PCB和TCB,PCB维护了一系列的TCB,具体调度是TCB完成,只要完成一次切换(或创建,终止)就要完成一次用户态到内核态的变化,系统调用/调用内核函数,OS开销比用户线程大。在一个进程中,某个内核线程阻塞不影响其他线程运行;时间片分给线程,多线程的进程自动获得更多CPU时间。Windows NT/2000/XP
轻量级进程
内核支持的用户线程。一个进程有一个或多个轻量级进程,每个轻量级进程由一个单独的内核线程来支持。
原文链接:https://blog.csdn.net/github_36487770/article/details/60144610
线程控制块 TCB(Thread control block)
内容:
-
线程标识符
-
一组寄存器(现场)
-
通用寄存器
-
程序计数器PC
-
状态寄存器
-
-
线程运行状态
-
优先级
-
线程专有存储区
-
信号屏蔽
-
堆栈指针
存放位置
用户级:目态空间(运行级系统)
核心级:系统空间
18.(1分)在用户级线程包中,线程由(A)调度。C
(A)内核
(B)用户
(C)进程
(D)以上均不是
例题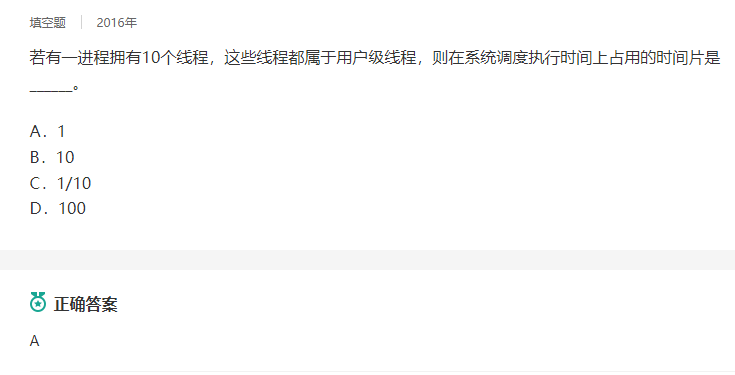
在引入线程的操作系统中,线程是进程中的一个实体,是系统独立调度和分派的基本单位。但是线程自己基本上不拥有系统资源,所以它不是资源分配的基本单位,它只拥有一部分在运行中必不可少的与处理机相关的资源,如线程状态、寄存器上下文和栈等,它同样有就绪、阻塞和运行三种基本状态。它可与同属一个进程的其他线程共享进程所拥有的全部资源。一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行。由于用户线程不依赖于操作系统内核,因此,操作系统内核是不知道用户线程的存在的。用户线程是由用户来管理和调度的,用户利用线程库提供的API来创建、同步、调度和管理线程。所以,用户线程的调度在用户程序内部(进程)进行,通常采用非抢先式和更简单的规则,也无须用户态和核心态切换,所以速度很快。由于操作系统不知道用户线程的存在,所以,操作系统把CPU的时间片分配给用户进程,再由用户进程的管理器将时间分配给用户线程。那么,用户进程(1个)能得到的时间片即为所有用户线程共享。因此,正确答案应为A。
线程包的概念:
开发者用于创建、操作、结束线程的开发库。头文件为:pthread.h。你可以打开该头文件看看。如果你的c程序需要进行线程控制,就需要此包。
在用户空间实现
内核对线程包一无所知,从内核角度考虑,就是按正常单线程进程管理。每个进程需要有其专用的线程表,用来跟踪该进程中的线程。这些表和内核中的进程表类似,不过仅仅记录各个线程的属性,如每个线程的程序计数器,堆栈指针、寄存器和状态等,并由运行时系统管理。
优点:
用户级线程包可以在不支持线程的操作系统上实现。线程切换比陷入内核要快一个数量级。因为如果某个线程阻塞,线程表保存该线程的寄存器,然后查看表中可运行的线程,并且把新线程的保存值重新装入机器的寄存器中。只要堆栈指针和程序计数器被切换,新的线程即可立即投入运行。如果机器有一条保存所有寄存器的指令和另一条装入全部寄存器的指令,那么切换可以在几条指令内完成。另外,保存线程状态的过程和调度程序是本地过程,不需要内核调用。不需要陷阱,不需要上下文切换,也不需要对Cache进行刷新。
允许每个进程有自己定制的调度算法。
扩展性:内核空间中内核线程需要一些固定表格空间和堆栈空间,如果数量过大,就会出现问题。
缺点:
阻塞系统调用:假设在没有任何击键之前,一个线程读取键盘,让该线程实际进行该系统调用是不可接受的。因为这会停止所有线程。使用线程的一个目标是,首先要允许每个线程使用阻塞调用,但是还要避免被阻塞的线程影响其他线程。有了阻塞系统调用,这个目标很难实现。
改进:如果某个调用会阻塞,提前通知。例如在Unix中使用select允许调用者通知预期read是否会阻塞。如果有这个调用,那么read就可以被新的操作替代。首先进行select调用,然后只有在不会阻塞的情况下才进行read调用。如果read调用会被阻塞,有关的调用就不进行,代之以运行另一个线程。
如果一个线程引起页面故障(跳转到不在内存上的指令),内核由于不知道有线程存在,通常会把整个进程阻塞,直到磁盘I/O完成为止,尽管其他线程是可以运行的。
如果一个线程开始运行,那么在该进程中其他的线程就不能运行,除非第一个线程自动放弃CPU。在一个单独的进程内部,没有时钟中断,所以不可能用轮转调度。除非某个线程能够按照自己的意志进入运行时系统,否则调度程序没有任何机会。 可能的方法是让运行时系统请求每秒一次的时钟信号(中断),但是这样对程序也是生硬和无序的。不可能总是高频率地发生周期性的时钟中断。有可能扰乱系统使用的时钟,因为线程可能也需要时钟中断。
在内核中实现
不需要运行环境,每个进程没有自己的线程表。相反,在内核中有用来记录系统中所有线程的线程表。当某个线程希望创建一个新线程或撤销一个已有线程时,它进行一个系统调用,这个系统调用通过对线程表的更新完成线程创建或撤销工作。
优点:
所有能够阻塞线程的调用都以系统调用的形式实现,当一个线程阻塞时,内核根据其选择, 可以运行同一个进程中的另一个线程(若有就绪线程)或者运行另一个进程中的线程。而在用户级线程中,运行环境始终运行自己进程中的线程,直到内核剥夺它的CPU为止。
因为在内核中创建或撤销线程代价较大,某些系统采取的处理方式为,回收线程,当某个线程被撤销时,把它标志为不可运行的,但是内核数据结构没有收到影响,在稍后创建新线程时,就重新启动某个旧线程,节省开销。
缺点:
当一个多线程进程创建新的进程时,新进程是拥有与原进程相同数量的线程还是应该只有一个线程。取决于进程下一步要做什么。如果要启动一个新程序,一个线程或许就可以。如果要继续运行,则应该复制所有线程。实现复杂。
信号:因为信号是发给进程而不是线程的,当一个信号到达时,应该如何决定由哪一个线程处理它。
3. 混合实现
使用内核级线程,一个内核级线程可能对应多个用户级线程
原文链接:实现线程包的方式 https://blog.csdn.net/github_37129174/article/details/78588658
19.(1分)在同一进程的用户级线程之间切换通常比其内核级线程之间切换
更有效,这是由于(A) C
(A)用户级线程需要跟踪较少的状态
(B)用户级线程共享相同的内存地址空间
(C)用户级线程之间切换不需要模式切换
(D)执行状态保持在采用用户级线程的同一进程内
4.2请列出线程间的模式切换比进程间的模式切换开销更低的原因。
进程间切换的步骤: 1,保存程序计数其以及其他寄存器。2,更新当前处于“运行态”的进程的进程控制块,把进程状态改为相应状态,更新其他相关域3,把被切换进程的进程控制块移到相关状态的队列4,选择另外一个进程开始执行,把该进程进程控制块的状态改为“运行态”5,恢复被选择进程的处理器在最近一次被切换出运行态时的上下文,比如载入程序计数器以及其他处理器的值进程间切换伴随着两次模式切换(用户--内核,内核-用户)。
(同一进程内〉线程间切换的步骤:线程分两种,用户级线程和内核级线程。在用户级线程中,有关线程管理的所有工作都由应用程序完成,内核没有意识到线程的存在。(同一进程内)用户级线程间切换时,只需要保存用户寄存器的内容,程序计数器,栈指针,不需要模式切换。在内核级线程中,有关线程的管理工作都是由内核完成的,应用程序部分没有线程管理的权限,只有一个接口(API)。(同一进程内)内核级线程间切换时,除了保存上下文,还要进行模式切换。
20.(1分)考虑一个32位微处理器,它有一个16位外部数据总线,并由一个8MHz 的输入时钟驱动。假设该微处理器的总线周期的最大持续时间等于4个输入时钟周期。问该微处理器可以支持的最大数据传输速率刀多少(D)B
(A)8 MBytes/sec
(B)4 MBytes/sec
(C)2 MBytes/sec
(D)1 MBytes/sec
解:时钟周期1/8 MHZ=125ns ns:纳秒
总线周期=4*125=500ns
即500ns 处理16位(b)/(1B/8b) =2B B:比特/字节
传输速率=数据量(字节数)/时间
=2B/500ns
统一单位
1M=10^6
2*2*10^6B/500*2*10^6ns
=4MB/10^9ns
=4MB/1s
选D

 浙公网安备 33010602011771号
浙公网安备 33010602011771号