

ThreadLocal与线程控制
一、ThreadLocal原理分析
1、概念
ThreadLocal类并不是用来解决多线程环境下的共享变量问题,而是用来提供线程内部的共享变量。在多线程环境下,可以保证各个线程之间的变量互相隔离、相互独立。
2、核心原理
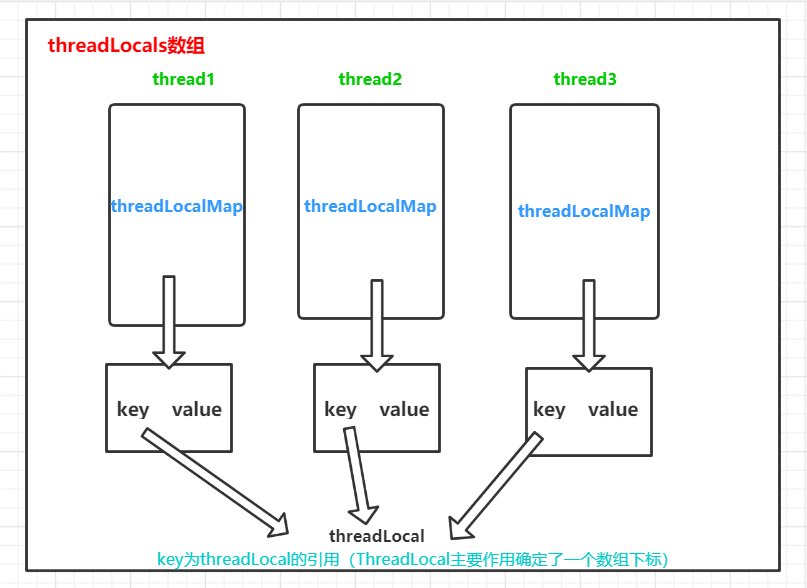
即:实际上是ThreadLocal的静态内部类ThreadLocalMap为每个Thread都维护了一个数组table,ThreadLocal确定了一个数组下标(ThreadLocal对象生成的hashCode),而这个下标就是value存储的对应位置。
通过源码分析:
set()方法即将value保存在当前线程的threadLocals成员变量中,threadLocals类型为ThreadLocal.ThreadLocalMap,ThreadLoclMap底层存储由Entry数组构成,单个entry结构为<ThreadLocal, Object>
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); }
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue); }
ThreadLocal.ThreadLocalMap threadLocals = null;
static class ThreadLocalMap { static class Entry extends WeakReference<ThreadLocal<?>> { Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } } }
3、ThreadLocal和Synchronized的区别与联系
联系:
threadLocal和Synchronized都是为了解决多线程中相同变量的访问冲突问题。
区别:
- Synchronized是通过线程等待,牺牲时间来解决访问冲突
- ThreadLocal是通过每个线程单独一份存储空间,牺牲空间来解决冲突,并且相比于Synchronized,ThreadLocal具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问到想要的值。
4、内存泄露问题
Entry类继承了WeakReference,即每个Entry对象都有一个ThreadLocal的弱引用,采用ThreadLocal的设计巧妙之处在于存储的ThreadLocalMap的每个Entry采用this(ThreadLocal)作为key,而弱引用的优势在于若ThreadLocal对象置为null,标记为回收对象,则指向该对象的弱引用会被清除,指向它的弱引用对象会进入引用队列中。
在ThreadLocalMap中,它的key是一个弱引用。通常弱引用都会和引用队列配合清理机制使用,但是ThreadLocal是个例外,它并没有这么做。这意味着,废弃项目的回收依赖于显式地触发,否则就要等待线程结束,进而回收相应ThreadLocalMap,这就是很多OOM的来源,所以通常都会建议,应用一定要自己负责remove,并且不要和线程池配合,因为worker线程往往是不会退出的。
二、控制线程
1、ForkJoin与ForkJoinPool
1)、概念
ForkJoin是由JDK1.7后提供多线并发处理框架。处理逻辑大概分为两步:
1.任务分割:Fork,先把大的任务分割成足够小的子任务,如果子任务比较大的话还要对子任务进行继续分割。
2.合并结果:join,分割后的子任务被多个线程执行后,再合并结果,得到最终的完整输出。
2)、设计思想
- 普通线程池内部有两个重要集合:工作线程集合和任务队列。
- ForkJoinPool也类似,工作集合里放的是特殊线程ForkJoinWorkerThread,任务队列里放的是特殊任务 ForkJoinTask。不同之处在于,普通线程池只有一个队列。而ForkJoinPool的工作线程ForkJoinWorkerThread每个线程内都绑定一个双端队列。
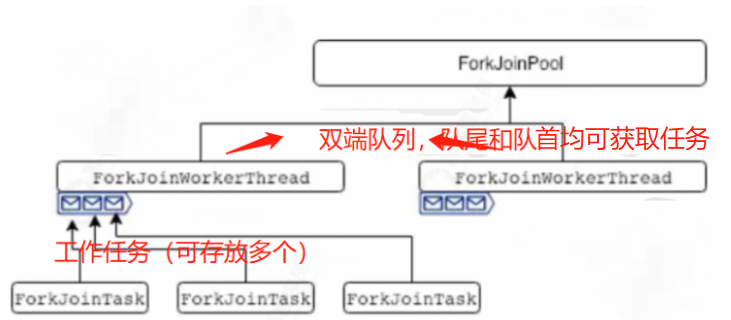
- 在fork的时候,也就是任务拆分,将拆分的task会被当前线程放到自己的队列中。
- 如果有任务,那么线程优先从自己的队列里取任务执行默认从队尾。
- 当自己队列中执行完后,工作线程会跑到其他队列的队首偷任务来执行。
eg:
package thread;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class ForkJoin extends RecursiveTask<Long> {
private long start;
private long end;
public ForkJoin(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long middle = (start + end) / 2;
ForkJoin leftTask = new ForkJoin(start, middle);
ForkJoin rightTask = new ForkJoin(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完毕
long left = leftTask.join();
long right = rightTask.join();
return left + right; // 合并子任务的计算结果
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
ForkJoin task = new ForkJoin(1, 11l);
Future<Long> future = pool.submit(task);
try {
System.out.println("result: " + future.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
2、 join线程
1)作用:阻塞当前线程,优先执行join进来的线程,join放大加入的线程执行完后,被阻塞的当前线程继续执行。
eg:
package thread;
public class Join extends Thread {
public Join(String name) {
super(name);
}
@Override
public void run(){
for (int i=0; i<10; i++){
System.out.println("curr thread name : "+getName()+", r :"+i+", priority : "+Thread.currentThread().getPriority());
}
}
public static void main(String[] args) throws InterruptedException {
//启动子线程,输出0-9
Join th1 = new Join("sub");
th1.start();
//主线程中打印0-9
for (int k=0; k<10; k++){
if (k==5){
//k==5时,执行join方法,当前线程的打印操作停止,join线程(子线程)启动打印,子线程之间执行顺序按照优先级依次执行
Join j = new Join("join");
j.start();
j.join();
}
System.out.println("main priority : " + Thread.currentThread().getPriority() + ", r : " + k);
}
}
}
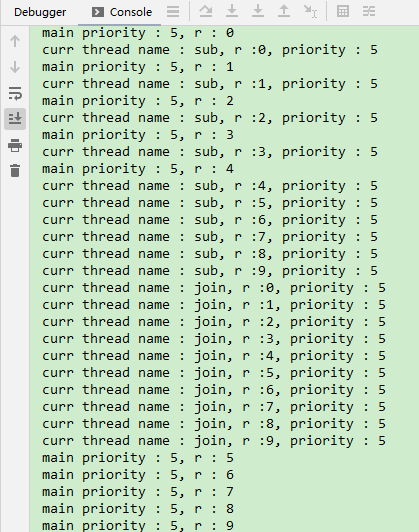
输出结果:
3、yield
1)作用:执行yield的方法的线程,该线程执行任务会暂停,线程进入就绪态,其他同级别或高优先级的线程(处于就绪态的)会被操作系统调用。
eg:
package thread;
/**
* @author Administrator
*/
public class Yield extends Thread {
public Yield(String name){
super(name);
}
@Override
public void run(){
for (int i=0; i < 5; i++){
if (i==3){
//当前线程转为就绪态,同级或高优先级的线程继续执行
Thread.yield();
}
System.out.println(getName()+":"+i);
}
}
public static void main(String[] args) {
Yield yth = new Yield("y1");
yth.start();
Yield yth2 = new Yield("y2");
yth2.start();
}
}
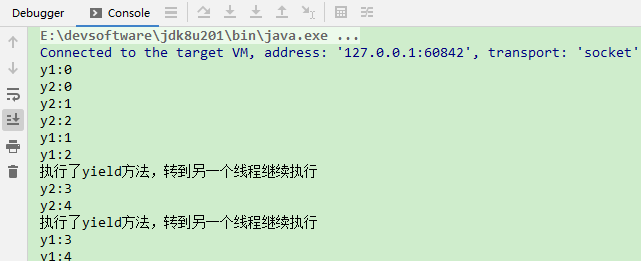
运行结果:
4、sleep
如果需要让当前正在执行的线程暂停一段时间,并进入阻塞状态,则可以通过调用Thread类的静态sleep()方法来实现。
5、后台线程
在后台运行的一种线程,它的任务是为其他的线程提供服务,这种线程被称为“后台线程(Daemon Thread)”,又称为“守护线程”或“精灵线程”。JVM的垃圾回收线程就是典型的后台线程。后台线程有个特征:如果所有的前台线程都死亡,后台线程会自动死亡。调用Thread对象的setDaemon(true)方法可将指定线程设置成后台线程。
package thread;
public class Daemon extends Thread {
@Override
public void run(){
for (int i = 0; i < 100; i++) {
System.out.println(i);
}
}
public static void main(String[] args) {
Daemon d = new Daemon();
d.setDaemon(true);
d.start();
//此处保证主线程不会停止,否则后台线程执行不完整就直接退出
while (true){}
}
}
注:前台线程死亡后,JVM 会通知后台线程死亡,但从它接收指令到做出响应,需要一定时间。而且要将某个线程设置为后台线程,必须在该线程启动之前设置,也就是说,setDaemon(true)必须在start()方法之前调用,否则会引发IllegalThreadStateException异常。
感谢阅读,借鉴了不少大佬资料,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/14305755.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号