


Neo4j cypher QL常用基础语法
cypher :一种声明式图查询语言,表达高效查询和更新图数据库。
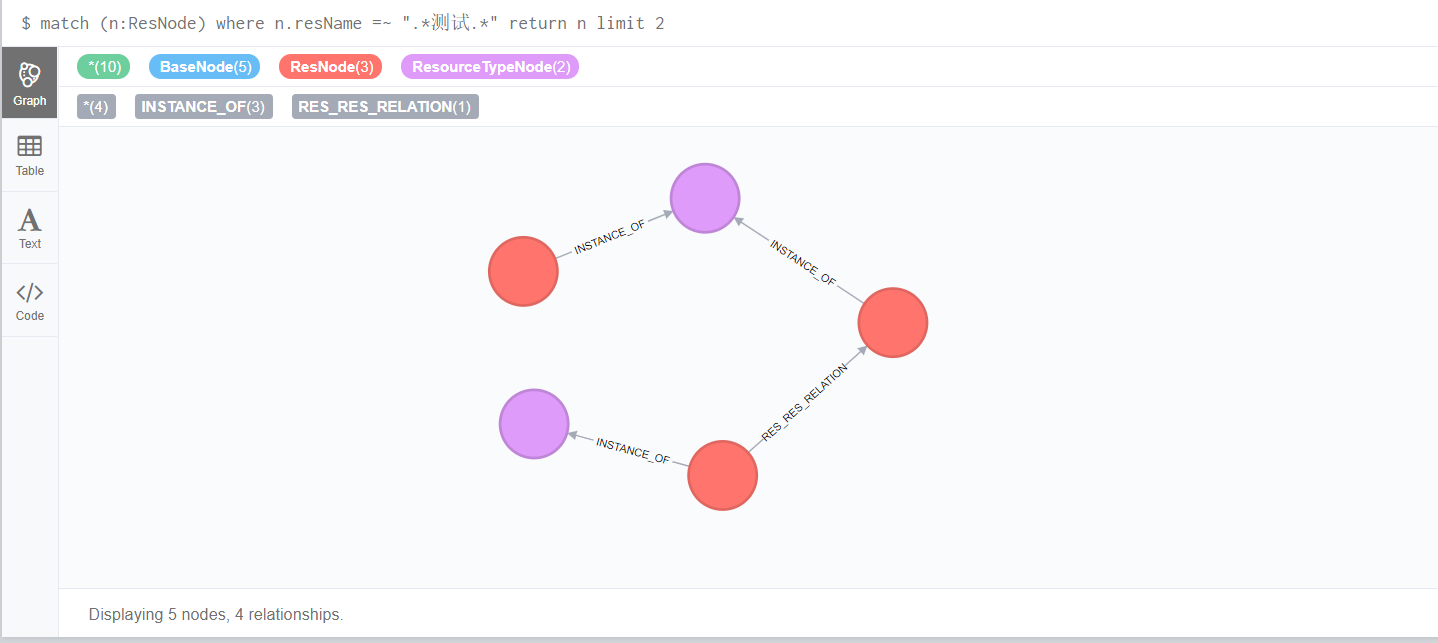
先来感受下neo4j优雅的web界面及图(关系)处理能力
一、基础知识
1、基础概念
变量:用于引用搜索模式(pattern),变量可以忽略,如果不需要引用;
节点:对象,可带若干key-value属性,可带标签;
关系:连接节点(有类型、带方向),可带若干名key-value属性;
标签:label没有属性。
2、属性访问:可以通过.访问;
3、常规运算:
(1)常规运算 DISTINCT, ., []
(2)算数运算 +, -, *, /, %, ^
(3)比较运算 =, <>, <, >, <=, >=, IS NULL, IS NOT NULL
(4)逻辑运算 AND, OR, XOR(异或), NOT
(5)字符串操作 +
(6)List操作 +, IN, [x], [x .. y], not actor in
(7)正则操作 =~ //后面可使用正则表达式匹配规则
(8)字符串匹配 STARTS WITH, ENDS WITH, CONTAINS
(9)示例:
(9.1)XOR使用
MATCH (n) WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = "Tobias") OR NOT (n.name = "Tobias" OR n.name="Peter") RETURN n
(9.2)CONTAINS使用
MATCH (n:RN)-[r:INSTANCE_OF]->(m:TYPE) WHERE m.id IN {resTypeNums} AND n.`props.propKey` CONTAINS {areaCode} RETURN n
(9.3)in使用
match (n:TEMP) where n.id in ['templateLabel_QP42X','templateLabel_network','templateLabel_ziEzh'] return n
(9.3)字符串+使用
MATCH(n:RN) WHERE n.id = "uiopj" with n.name as rName, n.name +"/" as rNamePlus MATCH(s:RN) WHERE (s.name starts with rNamePlus or s.name = rName) RETURN count(n) AS count
二、cypherQL 基础
0、节点:
0.1)、创建节点
单个节点 create (n)
创建带一个标签的节点 create (n:Person { name: 'Tom Hanks', born: 1956 }) return n;
创建带两个标签的节点 create (n:Person:Student)
返回创建的节点 create (a{name:"tom"}) return a;
0.2)、查询节点
match(n) return n;//查询所有节点
match(n) where n.born<1955 return n;//查询符合条件(通过where子句添加条件)的节点
match(n:Movie) return n;//查询具有标签的节点
match(n{name:'Tom Hanks'}) return n;//查询具有属性的节点
1、关系:
1)开始节点-[变量名:关系类型{key:value}]->结束节点,创建关系时,必须指定关系类型;
2) -- 有关系
--> <--有方向的关系
3) 创建关系
//创建新的节点和新的关系
create (a)-[r:RELATION]->(b) return r;
//创建关系的同时设置属性
create (a)-[r:RELATION{name:a.name+"<->"+b.name}]->(b) return r;
create (n:Lable1{title:"a",pic:"b"}) -[r:RELATION{id:"test"}]-> (m:Lable2{title:"a1",pic:"b1"});
create (a)-[r:RELATION]->(b) set r.id = "test", a.title="a" return a,r,b;
//已有节点创建新的关系
match (a:Person),(b:Person) where a.name="zhang" and b.name="lisi" create (a)-[r:RELATION]->(b) return a,r,b;
注意:为现有的两个节点添加了关系。这种情况我们需要用match先找到两个节点,然后在给两个节点添加关系。如果没有match就等同于新建节点。现有的节点被忽略
完整创建:三个关系两个节点
create p=(an{name:"an"})-[:WORKS_AT]->(neo)<[:WORKS_AT]-(match{name:"tom"}) return p;
注意:
1,创建节点和关系语句必须一次执行完,否则如上面例子所述,创建关系时()中的节点被认为是新的节点。
2,分号是一个语句的结尾
4) set
//更新一个节点和关系的标签或属性 更改属性
match (n{name:"tom"}) set n.name="tom1" return n;
//设置多个属性:
MATCH (n { name: 'Andres' }) SET n.position = 'Developer', n.surname = 'Taylor'
//删除属性
match (n{name:"tom"}) set n.name=null return n;
//更改标签
match (n{name:"tom"}) set n:Label return n; match (n{name:"tom"}) set n:Label1:Label2 return n;
//节点和关系之间复制属性 在节点和关系之间复制属性:
MATCH (at { name: 'Andres' }),(pn { name: 'Peter' }) SET at = pn RETURN at, pn;
//FOREACH: 为所有节点设置mark属性
MATCH p =(begin)-[*]->(END ) WHERE begin.name='A' AND END .name='D' FOREACH (n IN nodes(p)| SET n.marked = TRUE )
5) 删除
5.1)删除节点和关系 delete
删除单个节点 match (n:Label) delete n;
删除节点和连接它的关系 match (n{name:"tom"})-[r]-() delete n,r;
只删除关系 match (n{name:"tom"})-[r]-() delete r;
删除所有节点和关系(慎用)match(n) optional match (n)-[r]-() delete n,r;
删除节点及其关系 MATCH (n:Department{name: "test",alias: ""}) DETACH DELETE n
5.2)删除标签和属性 remove
删除属性 match (n{name:"tom"}) remove n.age return n;
删除标签 match (n:{name:"tom"}) remove n:Label return n;
删除多重标签 match (n:{name:"tom"}) remove n:Label:Label1 return n;
注:set也可以删除属性 match (n:User{name:'jack'}) set n.name = null return n;
6)match
//查询所有节点 match (n) return n;
//查询指定标签的节点 match(n)--(m:Movie) return n; MATCH (n:templatelabel2) RETURN n LIMIT 25;
//关联节点 match (person{name:'tom'})--(movie) return movie;
//关联标签 match (person{name:'tom'})--(movie:Movie) return movie;
//关系查询 match (person{name:'tom'})-->(movie) return movie;
match (person{name:'tom'})-[r]->(movie) return r;
match (:Person(name:'tom'))-[r]->(Movie) return r,type(r);//返回关系类型
查询特定的关系,通过[variable:RelationshipType{key:value}]指定关系的类型和属性
match (:Person{name:tom})-[r:ACTED_IN(roles:'forrest')]->(movie) return r,type(r);
6.1) where子句
过滤标签:MATCH (n) WHERE n:Swedish RETURN n
过滤属性:MATCH (n) WHERE n.age < 30 RETURN n
正则/模糊查询:MATCH (n) WHERE n.name =~ 'Tob.' RETURN n
使用NOT:MATCH(persons),(peter { name: 'Peter' }) WHERE NOT (persons)-->(peter) RETURN persons
使用属性:MATCH (n) WHERE (n)-[:KNOWS]-({ name:'Tobias' }) RETURN n
关系类型:MATCH (n)-[r]->() WHERE n.name='Andres' AND type(r)=~ 'K.' RETURN r
使用IN:MATCH (a) WHERE a.name IN ["Peter", "Tobias"] RETURN a
过滤NULL:MATCH (person) WHERE person.name = 'Peter' AND person.belt IS NULL RETURN person
使用NOT...IN: MATCH (n:RN)-[r:INSTANCE_OF]->(m:TYPE) where not m.typeNum in ["USER","ORG"] return count(n)
6.2)START
START n=node:nodes(name = "A") RETURN n
START r=relationship:rels(name = "LISI") RETURN r
START n=node:nodes("name:A") RETURN n
6.3)聚合函数
count:MATCH (n { name: 'A' })-->(x) RETURN n, count(*)
sum:MATCH (n:Person) RETURN sum(n.property)
avg:MATCH (n:Person) RETURN avg(n.property)
max:MATCH (n:Person) RETURN max(n.property)
min:MATCH (n:Person) RETURN min(n.property)
6.4)常规函数
return
返回一个节点:match (n {name:"B"}) return n;
返回一个关系:match (n {name:"A"})-[r:KNOWS]->(c) return r;
返回一个属性:match (n {name:"A"}) return n.name;
返回所有节点:match p=(a {name:"A"})-[r]->(b) return *;
列别名: match (a {name:"A"}) return a.age as thisisage;
表达式: match (a {name:"A"}) return a.age >30 ,"literal",(a)-->();
唯一结果:match (a {name:"A"})-->(b) return distinct b;
order by
通过属性排序所有节点:match (n) return n order by n.name;
多个属性排序:match (n) return n order n.name,n.age;
指定排序方式:match (n) return n order by n.name desc;
NULL值的排序:match (n) return n.length,n order by n.length;
limit
match (n) return n order by n.name limit 3;
skip
match (n) return n order by n.name skip 3;
match (n) return n order by n.name skip 1 limit 3;
union
unwind [1,2,1,2,3] as x return x union unwind [1,2,1,2,3] as x return x
输出结果:

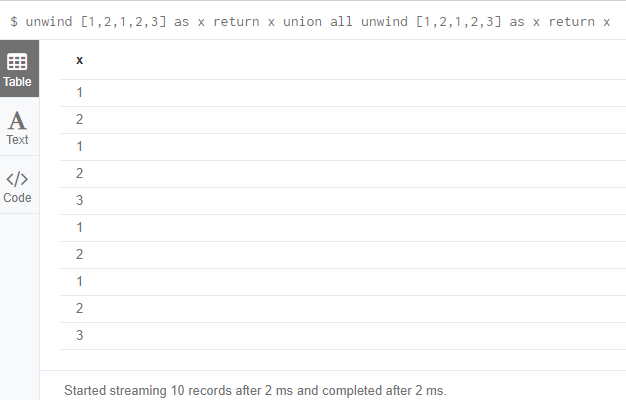
union all
unwind [1,2,1,2,3] as x return x union all unwind [1,2,1,2,3] as x return x
输出结果:
with
主要用途:
1、通过使用oder by 和limit,with可以限制传入下一个match子查询语句的实体数目。
2、对聚合值过滤。
过滤聚合函数的结果:(常用于对统计结果的操作) MATCH (david { name: "David" })--(otherPerson)-->() WITH otherPerson, count(*) AS foaf WHERE foaf > 1 RETURN otherPerson;
collect前排序结果:MATCH (n) WITH n ORDER BY n.name DESC LIMIT 3 RETURN collect(n.name;
limit搜索路径的分支: MATCH (n { name: "Anders" })--(m) WITH m ORDER BY m.name DESC LIMIT 1 MATCH (m)--(o) RETURN o.name;
unwind
将一个集合展开为序列:unwind[1,2,3] as x return x; 创建一个去重的集合:with [1,1,2,3] as coll unwind coll x with distinct x return coll(x) as set;
optional
optional match 外连接(表之间关联查询,查询出两张表的数据,非笛卡儿积)(optional 貌似可以省略---待测) 与match类似,只是如果没有匹配上,则使用null作为没有匹配上的模式。类似sql中的外连接; 匹配关系:match (a:Movie {title:"Wall Street"}) optional match (a)-->(x) return x; 如果没有返回null; 匹配属性:match (a:Movie {title:"Wall Street"}) optional match (a)-->(x) return x,x.name
//返回两张表的结果 match (n:RN)-[r:INSTANCE_OF]-(m:TYPE) where m.typeNum = "2" match(n1:RN)-[r0:INSTANCE_OF]-(m1:TYPE) where m1.typeNum = "vpn" return n,n1
//返回两张表的结果 match (n:RN)-[r:INSTANCE_OF]-(m:TYPE) where m.typeNum = "2" optional match(n1:RN)-[r0:INSTANCE_OF]-(m1:TYPE) where m1.typeNum = "vpn" return n,n1
case...when
MATCH (n) RETURN n.name, CASE n.age WHEN n.age IS NULL THEN -1 ELSE n.age - 10 END AS age_10_years_ago
range() 函数(查询区间范围)
match(n:RN) where n.createTime in range(1579155490014,1579155491014) return n limit 5
断言函数
指对给定的输入返回true或者false的布尔函数。它们主要用于查询的WHERE部分过滤子图
1.1 all() 判断是否一个断言适用于列表中的所有元素。
语法: all(variable IN list WHERE predicate)
参数:
list:返回列表的表达式
variable:用于断言中的变量
predicate:用于测试列表中所有元素的断言
MATCH p =(a)-[*1..3]->(b) WHERE ALL (x IN nodes(p) WHERE x.age > 30) RETURN p
1.2 any() 判断是否一个断言至少适用于列表中的一个元素。
语法: any(variable IN list WHERE predicate)
参数:
list:返回列表的表达式
variable:用于断言中的变量
predicate:用于测试列表中所有元素的断言
MATCH (a) RETURN ANY (x IN a.array WHERE x = 'one') RETURN a 返回路径中的所有节点的array数组属性中至少有一个值为'one'。
1.3 none() 如果断言不适用于列表中的任何元素,则返回true。
语法: none(variable IN list WHERE predicate)
参数:
list:返回列表的表达式
variable:用于断言中的变量=
predicate:用于测试列表中所有元素的断言
MATCH p =(n)-[*1..3]->(b) WHERE n.name = 'Alice' AND NONE (x IN nodes(p) WHERE x.age = 25) RETURN p 返回的路径中没有节点的age属性值为25。
1.4 single() 如果断言刚好只适用于列表中的某一个元素,则返回true。
语法: single(variable IN list WHERE predicate)
参数:
list:返回列表的表达式
variable:用于断言中的变量
predicate:用于测试列表中所有元素的断言
MATCH p =(n)-->(b) WHERE n.name = 'Alice' AND SINGLE (var IN nodes(p) WHERE var.eyes = 'blue') RETURN p 每条返回的路径中刚好只有一个节点的eyes属性值为'blue'。
1.5 exists() 如果数据库中存在该模式或者节点中存在该属性时,则返回true。
语法: exists( pattern-or-property )
参数: pattern-or-property:模式或者属性(以’variable.prop’的形式)
MATCH (n) WHERE exists(n.name) RETURN n.name AS name, exists((n)-[:MARRIED]->()) AS is_married 返回了所有节点的name属性和一个指示是否已婚的true/false值。
标量(Scalar)函数
标量(Scalar)函数:指返回一个单值。
2.1 size()
使用size()返回表中元素的个数。
语法: size( list )
参数: list:返回列表的表达式
RETURN size(['Alice', 'Bob']) AS col 返回了list中元素的个数。
2.2 模式表达式的size
这里的size()的参数不是一个列表,而是一个模式表达式匹配到的查询结果集。计算的是结果集元素的个数,而不是表达式本身的长度。
语法: size( pattern expression )
参数: pattern expression:返回列表的模式表达式
MATCH (a) WHERE a.name = 'Alice' RETURN size((a)-->()-->()) AS fof
返回了模式表达式匹配到的子图的个数
2.3 length()
使用length()函数返回路径的长度。
语法: length( path )
参数: path:返回路径的表达式
MATCH p =(a)-->(b)-->(c) WHERE a.name = 'Alice' RETURN length(p)
2.4 字符串的长度
语法: length( string )
参数: string:返回字符串的表达式
RETURN length('qwer')
MATCH (a) WHERE length(a.name)> 6 RETURN length(a.name)
查询返回了name为’Charlie’的长度。
2.5 type()
返回字符串代表的关系类型。
语法: type( relationship )
参数: relationship:一个关系
MATCH (n)-[r]->() WHERE n.name = 'Alice' RETURN type(r)
查询返回了关系r的关系类型。
2.6 id()
返回关系或者节点的id。
语法: id( property-container )
参数: property-container:一个节点或者关系
MATCH (a) RETURN id(a) 返回了5个节点的id。
2.7 coalesce()
返回表达式列表中的第一个非空的值。如果所有的实参都为空 ,则返回null。
参数: expression:表达式,可能返回null。
MATCH (a) WHERE a.name = 'Alice' RETURN coalesce(a.hairColor, a.eyes)
2.8 head()
head()返回列表中的第一个元素。
语法: head( expression )
参数: expression:返回列表的表达式
MATCH (a) WHERE a.name = 'Eskil' RETURN a.array, head(a.array)
MATCH p=(n)-[r]->() WHERE n.name = 'Alice' return head(nodes(p))
返回了路径中的第一个节点。
2.9 last()
last()返回列表中的最后一个元素。
语法: last( expression )
参数: expression:返回列表的表达式
MATCH (a) WHERE a.name = 'Eskil' RETURN a.array, last(a.array)
返回了路径中的最后一个节点。
2.10 timestamp()
timestamp()返回当前时间与1970年1月1日午夜之间的差值,单位以毫秒计算。它在整个查询中始终返回同一个值,即使是在一个运行时间很长的查询中。
语法: timestamp()
RETURN timestamp()
以毫秒返回当前时间。
2.11 startNode() 返回一个关系的开始节点。
语法: startNode( relationship )
参数: relationship:返回关系的表达式
MATCH ()-[r]-() WHERE id(r)=0 RETURN startNode(r)
2.12 endNode()
endNode()返回一个关系的结束节点。
语法: endNode( relationship )
参数: relationship:返回关系的表达式
MATCH ()-[r]-() WHERE id(r)=0 RETURN startNode(r),endNode(r)
2.13 properties()
properties()将实参转为属性值的map。如果实参是一个节点或者关系,返回的就是节点或关系的属性的map。如果实参已经是一个map了,那么原样返回结果。
语法: properties( expression )
参数: expression:返回节点,关系或者map的表达式
match (n) where id(n) =0 RETURN properties(n)
2.14 toInt()
toInt()将实参转换为一个整数。字符串会被解析为一个整数。如果解析失败,将返回null。浮点数将被强制转换为整数。
toInt("233")
2.15 toFloat
toFloat()将实参转换为浮点数。字符串会被解析为一个浮点数。如果解析失败,将返回null。整数将被强制转换为浮点数。
其他函数---模式(索引、约束、统计)
索引
标签上创建索引:create index on :Person(name)
删除索引:drop index on :Person(name)
约束
创建唯一约束:CREATE CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE
删除约束:DROP CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE
2、更新图形
创建一个完整的path path由节点和关系构成,当路径中的关系或节点不存在时,neo4j会自动创建; CREATE p =(vic:Worker:Person{ name:'vic',title:"Developer" })-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael:Worker:Person { name: 'Michael',title:"Manager" }) RETURN p 变量neo代表的节点没有任何属性,但是,其有一个ID值,通过ID值为该节点设置属性和标签
2)为节点增加属性 match(n) where id(n)=7 set n.name='neo' return n;
3)为节点增加标签 match (n) where id(n)=7 set n:Company return n;
4)为关系增加属性 match (n) <-[r]-(m) where id(n)=7 and id(m)=8 set r.team='azure' return n;
3、实体相关函数
match (:Person{name:'tom'})-[r]->(movie) return id(r);
match (:Person{name:'tom'})-[r]->(movie) return type(r);
match (:Person{name:'tom'})-[r]->(movie) return lables(movie);
MATCH (a) WHERE a.name = 'Alice' RETURN keys(a)
CREATE (p:Person { name: 'Stefan', city: 'Berlin' }) RETURN properties(p)
4、merge的作用
节点存在时,匹配该节点; 节点不存在时,创建新的节点,功能是match子句和creat的组合。
eg:
MATCH (n:A) where n.p in ['1,2,3'] and n.id= "1" with collect(n.id) as ids foreach( rid in ids | merge (r:B{id:rid}) set r.`p2.pp`='0',r.`p2.ppp`='test')
match (m:Lab1) where m.p2 in ["a","c","b"] with collect(m) as ress MATCH (n:Lab1) where not n in ress RETURN n LIMIT 3;
//关系排除查询
MATCH (n:Lab1) where not((n:Lab1)-[:rType]->(:Lab2)) RETURN n.p1,n.p2
//查询最近的n条记录
MATCH (n:Lab1)-[r:relation*1..30]->(m:Lab2) where n.his ='start' RETURN n,r,m
//关系深度
MATCH p=(n)-[*1..5]->(m) RETURN p //匹配从n到m,任意关系,深度1到5的节点
MATCH p=(n)-[*]->(m) RETURN p //匹配从n到m,任意关系、任意深度的节点
// splite使用
split(n.resName,'-')[2]
//substring
split(substring(ipListStr, 1, size(ipListStr)-2), ', ') as ips
附录:
neo4j官方cypherQL用法说明:https://neo4j.com/docs/cypher-refcard/3.2/
感谢阅读,参考了不少大佬资源,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/13620260.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号