
Redis相关操作
Redis相关文档
一. Redis简单使用
redis作为一款目前这个星球上性能最高的非关系型数据库之一. 拥有每秒近十万次的读写能力. 其实力只能用恐怖来形容.
1.安装redis
redis是我见过这个星球上最好安装的软件了. 比起前面的那一坨. 它简直了...
直接把压缩包解压. 然后配置一下环境变量就可以了.
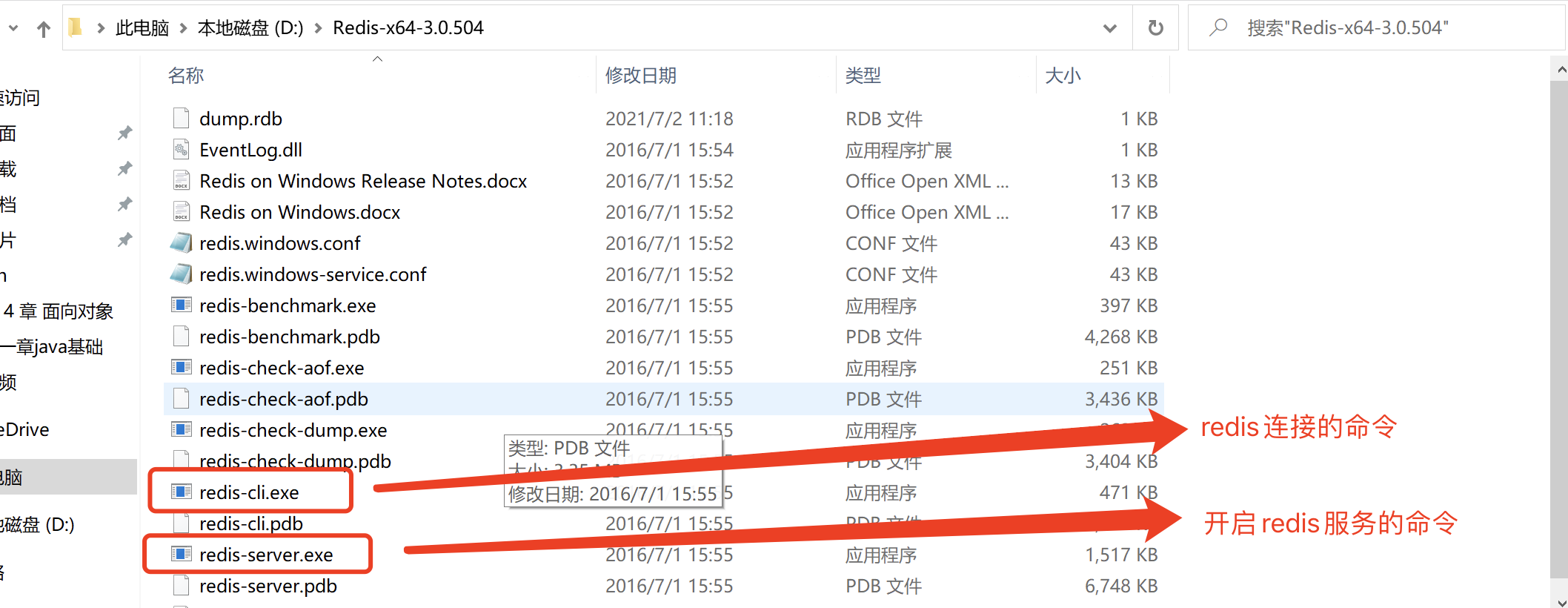
接下来, 在环境变量中将该文件夹配置到path中.
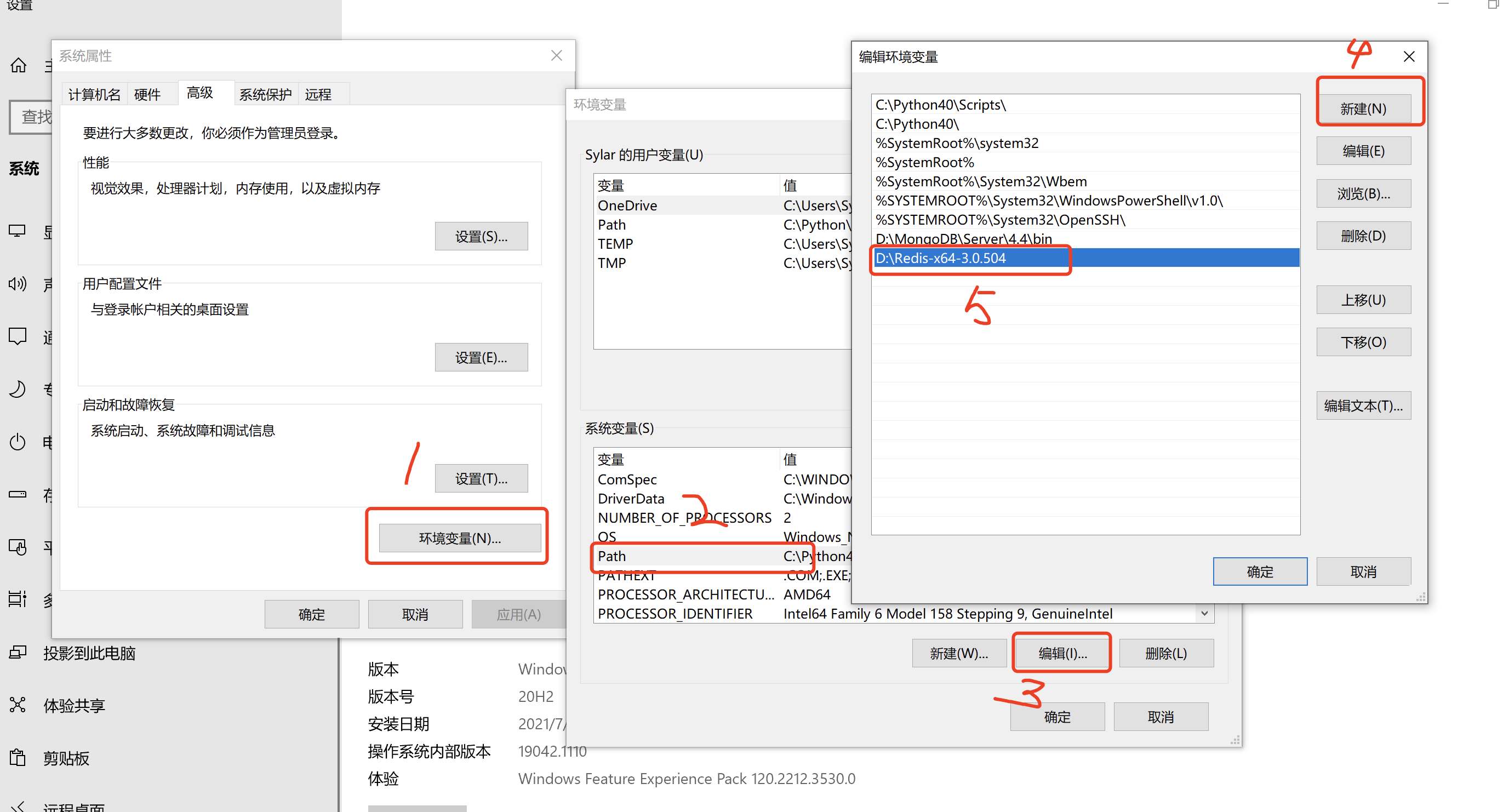
win7的同学自求多福吧...
我们给redis多配置几个东西(修改redis的配置文件, mac是: redis.conf, windows是: redis.windows-service.conf)
-
关闭bind
# bind 127.0.0.1 ::1 # 注释掉它 -
关闭保护模式 windows不用设置
protected-mode no # 设置为no -
设置密码
requirepass 123456 # 设置密码
将redis怼到windows服务必须进入到redis目录后才可以
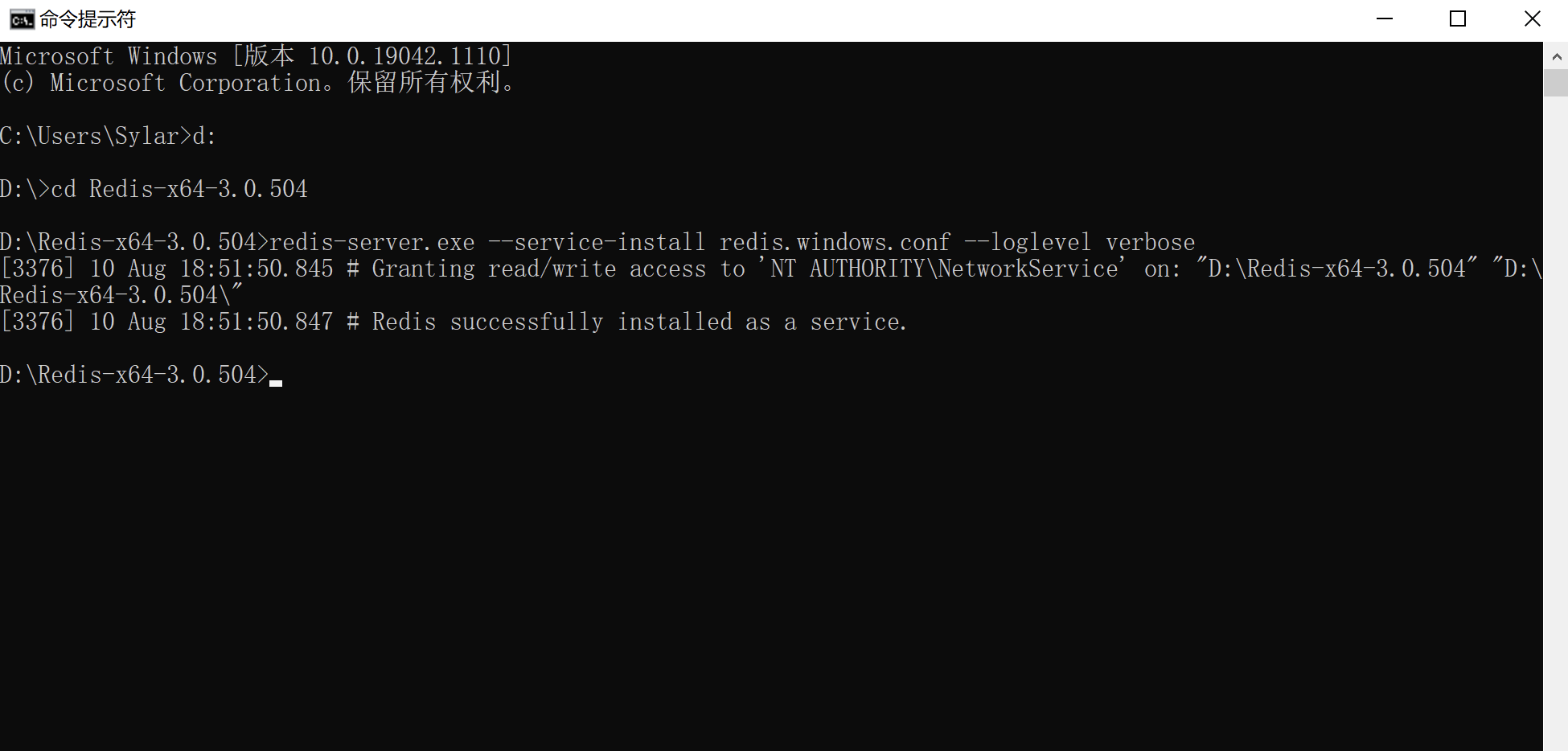
# 将redis安装到windows服务
redis-server.exe --service-install redis.windows.conf --loglevel verbose
# 卸载服务:
redis-server --service-uninstall
# 开启服务:
redis-server --service-start
# 停止服务:
redis-server --service-stop
mac的同学
redis-server /usr/local/etc/redis.conf
使用redis-cli链接redis
redis-cli -h ip地址 -p 端口 --raw # raw可以让redis显示出中文(windows无效)
auth 密码 # 如果有密码可以这样来登录, 如果没有.不用这一步
附赠RDM, redis desktop manager. 可以帮我们完成redis数据库的可视化操作(需要就装, 不需要就算, windows建议安装)

2.redis常见数据类型
整个redis可以看做一个超大号的大字典. 想要区分不同的系统. 可以在key上做文章.
redis中常见的数据类型有5个.
命令规则: 命令 key 参数
-
string
字符串(它自己认为是字符串, 我认为是任何东西. ), redis最基础的数据类型.
常用命令
set key value # 添加一条数据 get key # 查看一条数据 incr key # 让该key对应的数据自增1(原子性, 安全) incrby key count # 让该key对应的value自增 count type key # 查看数据类型(set进去的东西一律全是字符串)例如
set name zhangsan # 添加数据 name = zhangsan get name # 查看数据 zhangsan set age 10 get age # 10 incr age # 11 get age # 11 incrby age 5 # 16 -
hash
哈希, 相当于字典.
常见操作
hset key k1 v1 # 将k1, v1存储在key上 hget key k1 # 将key上的k1提取出来 hmset key k1 v1 k2 v2 k3 v3.... # 一次性将多个k,v存储在key hmget key k1 k2....# 一次性将key中的k1, k2...提取出来 hgetall key # 一次性将key中所有内容全部提取 hkeys key # 将key中所有的k全部提取 hvals key # 将key中所有的v全部提取示例:
HMSET stu id 1 name sylar age 18 HMGET stu name age # syalr 18 HGETALL stu # id 1 name sylar age 18 HKEYS stu # id name age HVALS stu # 1 syalr 18 -
list
列表, 底层是一个双向链表. 可以从左边和右边进行插入. 记住每次插入都要记得这货是个双向链表
常见操作
LPUSH key 数据1 数据2 数据3.... # 从左边插入数据 RPUSH key 数据1 数据2 数据3.... # 从右边插入数据 LRANGE key start stop # 从start到stop提取数据. LLEN key # 返回key对应列表的长度 LPOP key # 从左边删除一个.并返回被删除元素 RPOP key # 从右边删除一个.并返回被删除元素示例:
LPUSH banji yiban erban sanban siban LRANGE banji 0 -1 # yiban erban sanban siban RPUSH ban ban1 ban2 ban3 LRANGE ban 0 -1 # ban1 ban2 ban3 LPOP ban # ban1 LLEN key # 2
redis队列的查看方式:
keys *
type xxx -> list
lrange xxx 0 -1
-
set
set是无序的超大集合. 无序, 不重复.
常见操作
SADD key 值 # 向集合内存入数据 SMEMBERS key # 查看集合内所有元素 SCARD key # 查看key中元素的个数 SISMEMBER key val # 查看key中是否包含val SUNION key1 key2 # 并集 SDIFF key1 key2 # 差集合, 在key1中, 但不在key2中的数据 SINTER key1 key2 # 计算交集, 在key1和key2中都出现了的 SPOP key # 随机从key中删除一个数据 SRANDMEMBER key count # 随机从key中查询count个数据实例:
SADD stars 柯震东 吴亦凡 张默 房祖名 # 4 SADD stars 吴亦凡 # 0. 重复的数据是存储不进去的. SMEMBERS stars # 柯震东 吴亦凡 张默 房祖名 SISMEMBER stars 吴亦凡 # 吴亦凡在 stars里么? 1 在 0 不在 SADD my 周杰伦 吴亦凡 房祖名 SINTER stars my # 计算交集 吴亦凡 房祖名 SPOP my # 随机删除一个 SRANDMEMEBER my 2 # 从集合总随机查看2个 -
zset
有序集合, 有序集合中的内容也是不可以重复的. 并且存储的数据也是redis最基础的string数据. 但是在存储数据的同时还增加了一个score. 表示分值. redis就是通过这个score作为排序的规则的.
常用操作
ZADD key s1 m1 s2 m2 ... # 向key中存入 m1 m2 分数分别为s1 s2 ZRANGE key start stop [withscores] # 查看从start 到stop中的所有数据 [是否要分数] ZREVRANGE key start stop # 倒叙查看start到stop的数据 ZCARD key # 查看zset的数据个数 ZCOUNT key min max # 查看分数在min和max之间的数据量 ZINCRBY key score member # 将key中member的分值score ZSCORE key m # 查看key中m的分值示例:
ZADD fam 1 sylar 2 alex 3 tory # 添加三个数据 ZRANGE fam 0 -1 WITHSCORES # 正序查看 ZREVRANGE fam 0 -1 WITHSCORES # 倒叙查看 ZINCRBY fam 10 alex # 给alex加10分 ZADD fam 100 alex # 给alex修改分数为100分 ZSCORE fam alex # 查看alex的分数 ZCARD fam # 查看fam的数据个数
redis还有非常非常多的操作. 我们就不一一列举了. 各位可以在网络上找到非常多的资料.
各位大佬们注意. 数据保存完一定要save一下, 避免数据没有写入硬盘而产生的数据丢失
二. python操作redis
1. String操作
redis的String在内存中按照一个name对应一个value来储存
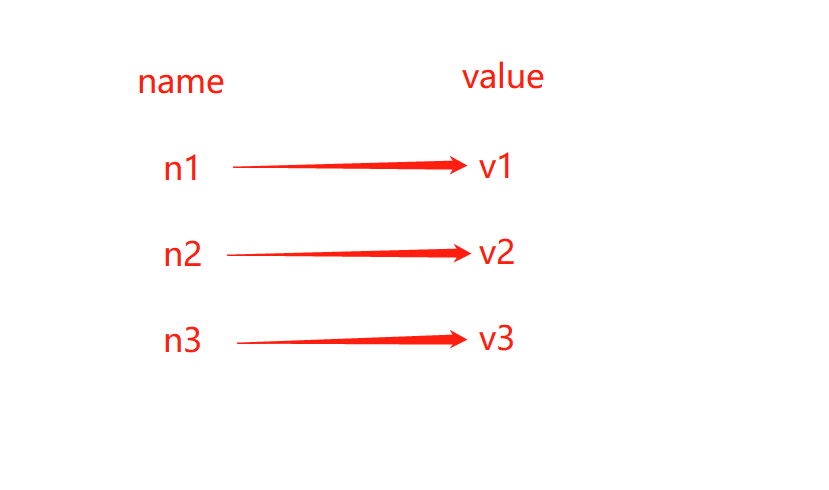
- set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
- setnx(name, value)
设置值, 只有name不存在时, 执行设置操作(添加)
- setex(name, value, time)
参数:
time, 过期时间(数字秒或timedelta对象)
- psetex(name, time_ms, value)
参数:
time_ms,过期时间(数字毫秒 或 timedelta对象)
- mset(*args, **kwargs)
批量设置值
如:
mset(k1="v1", k2="v2")
或
mset({"k1": "v1", 'k2': 'v2'}) # 推荐
- get(name)
获取值
- mget(keys, *args)
批量获取
如:
mget('k1', 'k2')
或
mget(['k1', 'k2'])
- getset(name, value)
设置新值并获取原来的值
- getrange(key, start, end)
获取子序列
参数:
name: Redis的name
start: 起始位置
end: 结束位置
- setrange(name, offset, value)
修改字符串内容, 从指定字符串索引开始向后替换
参数:
offset: 字符串的索引, 字节
value: 要设置的值
- incr(self, name, amount=1)
自增 name对应的值, 当name不存在时, 则创建name=amount, 否则自增
参数:
name, Redis的name
amount: 自增数
注: 同incrby
- incrbyfloat(self, name, amount=1.0)
自增: name对应的值, 当name不存在时, 则创建name=amount, 否则自增
参数:
name: redis的name
amount: 自减数(整数)
- append(key, value)
在redis name对应的值后面追加内容
参数:
key: redis的name
value: 要追加的字符串
2. Hash操作
Hash的存在形式就像python中的dict, 可以储存关联性较强的数据
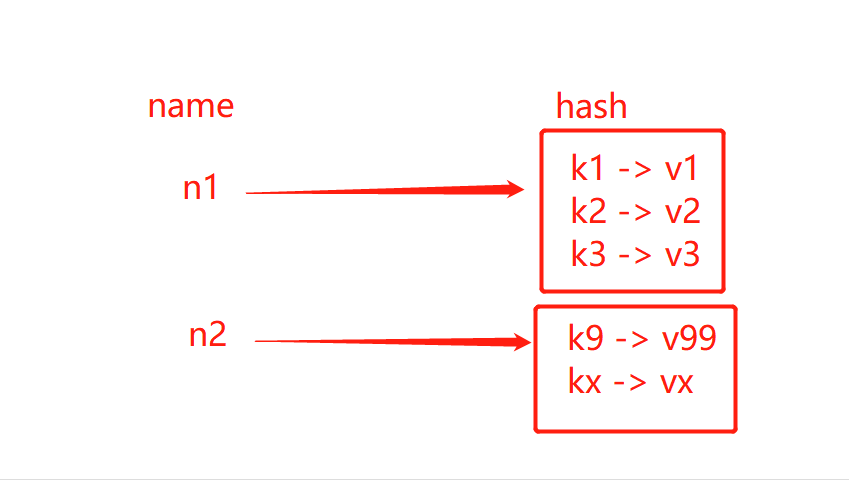
- hset(name, key, value)
name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
- hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
- hget(name, key)
在name对应的hash中获取根据key获取的value
- hmget(name, get, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
- hgetall(name)
获取name对应hash的所以键值
- hkeys(name)
获取name对应的hash中所有的key的值
- hvals(name, key)
获取name对应的hash是否存在所有的value值
- hexists(name, key)
检查name对应的hash是否存在当前传入的key
- hdel(name, *keys)
将name对应的hash中指定key的键值对删除
- hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
- hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
- hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
3. List操作
List操作, redis的List在内存中按照一个name对应一个List来储存
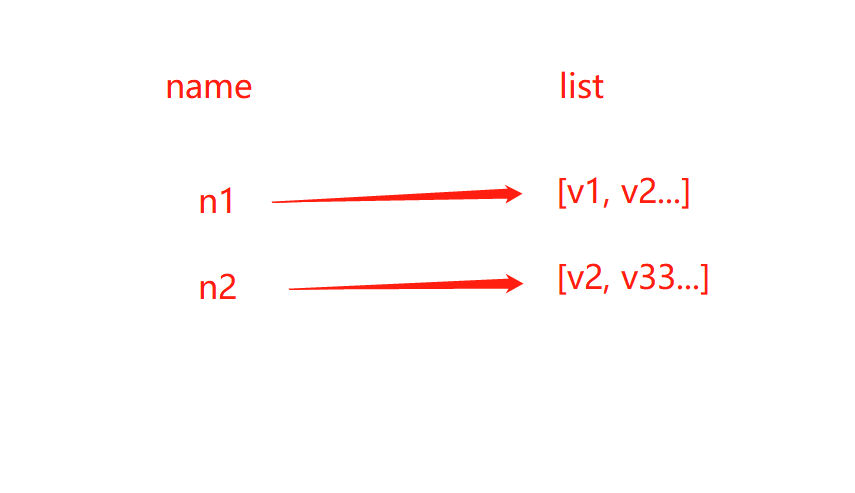
- lpush(name, value)
在name对应的list中添加元素, 每个新的元素都添加到列表的最左边
如:
r.lpush('00', 11, 22, 33)
保存顺序为: 33, 22, 11
拓展:
rpush(name, values) 表示从右向左操作
- lpushx(name, value)
在name对应的list中添加元素, name已经存在时, 值泰诺健挨到列表的最左边
拓展:
rpush(name, value) 表示从右向左操作
- llen(name)
name对应的list元素的个数
- linsert(name, where, refvalue, value)
在name对应的列表的某个值前或者后插入一个新值
参数:
where: BEFORE和AFTER
refvalue: 标杆值, 即在他前后插入数据
value: 要插入的数据
- lset(name, index, value)
name对应的list中的某个索引位置重新赋值
参数:
index: 索引
value: 要设置的值
- lrem(name, value, num)
在name对应的list中删除指定的值
参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
- lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移出, 返回值则是第一个元素
更多:
rpop(name): 表示从右向左操作
- lindex(name, index)
name对应的列表中根据索引取列表元素
- lrange(name, start, end)
name对应的列表分片获取数据
参数:
name: redis的name
start: 索引的起始位置
end: 索引结束的位置
- ltrim(name, start, end)
在name对应的列表中移出没有在start-end索引之间的值
参数:
name: redis的name
start: 索引的起始位置
end: 索引结束的位置
4. Set操作
Set集合技师不允许重复的列表
- sadd(name, values)
name对应的集合中添加元素
- scard(name)
获取name对应的集合中的元素个数
- sdiff(key, *args)
在第一个name对应的集合中且不在其他的name对应的集合的元素集合 -> 差集(第一个为主)
- sinter(keys, *args)
获取多个name对应集合的交集
- sunion(keys, *args)
获取多个name对应的集合的并集
- sismember(name, value)
检查vlaue是否是name对应的集合的成员
- smembers(name)
获取name对应的所有成员
- spop(name)
从集合中随机移出一个成员,并将其返回
- srandmember(name, numbers)
从name对应的集合中随机获取numbers个元素
- srem(name, value)
name对应的集合中删除某些值
- sscan_iter(name, match=None, count=None) -> 生成器
同字符串操作, 用户增量迭代分批获取元素, 比避免内存消耗太大
# 参数:
# match,默认None 表示所有的
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.sscan_iter('xx'): -> 生成器
# print item
5. Sort Set操作
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
- zadd(name, mapping, *args, **kwargs)
在name对应的有序集合中添加元素
print(r.zadd("zz", {'n1': 1, "n2": 2, "n3": 5, "n4": 3}))
- zcard(name)
获取name对应的有序集合元素的数量
- zcount(name, min, max)
后去name值对应的有序集合中分数, 在[min, max]之间的个数-> 按分数 数数
- zincrby(name, value, amount)
自增name对应的有序集合的name对应的分数
比如:
r.zincrby('z', 2, 'n3') -> 将n3的分数加2
- zrange(name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
aa=r.zrange("zset_name",0,1,desc=False,withscores=True,score_cast_func=int)
print(aa)
'''参数:
name redis的name
start 有序集合索引起始位置
end 有序集合索引结束位置
desc 排序规则,默认按照分数从小到大排序
withscores 是否获取元素的分数,默认只获取元素的值
score_cast_func 对分数进行数据转换的函数'''
- zscore(name, value)
获取name对应有序集合中value对应的分数
- zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
- zrem(name, values)
删除name对应的的有序集合中的值values的成员
如: zrem('zz', ['s1', 's2'])
- zremrangebyrank(name, min, max)
根据排行范围删除
- zremrangebyscore(name, min, max)
根据分数删除
- zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
r.zadd('z1', {'n1': 1, 'n2': 2, 'n3': 3, 'x': 100})
r.zadd('z2' ,{'n3': 4, 'n4': 5, 'n6': 6, 'x': 100})
r.zinterstore('z3', ('z1', 'z2'))
print(r.zscan('z3'))
Ouput: (0, [(b'n3', 7.0), (b'x', 200.0)])
- zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX -> 默认为sum
r.zadd('z1', {'n1': 1, 'n2': 2, 'n3': 3, 'x': 100})
r.zadd('z2' ,{'n3': 4, 'n4': 5, 'n6': 6, 'x': 100})
r.zunionstore('z4', ('z1', 'z2'))
print(r.zscan('z4'))
Ouput: (0, [(b'n1', 1.0), (b'n2', 2.0), (b'n4', 5.0), (b'n6', 6.0), (b'n3', 7.0), (b'x', 200.0)])
6. 其他常用操作
- delete(*names)
# 根据删除redis中的任意数据类型
- exists(name)
检测redis的name是否存在
- keys(pattern="*")
根据模型获取redis的name
更多:
keys: * 配置数据库中所有的key
KEYS: h?llo 匹配 hello , hallo 和 hxllo
# KEYS: h*llo 匹配 hllo 和 heeeeello
# KEYS: h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
- expire(name, time)
为redis的某个name设置超时时间
- rename(src, dst)
对redis的name重命名
- randomkey()
为某个redis的某个name设置超时时间
- type(name)
获取name对应值的类型
- scan_iter(match=None, count=None)
同字符串操作,用于增量迭代获取key
for item in r.hscan_iter('xx'):
print item
7. 使用场景
- String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存,比如减少库存。
- hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
- list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适---取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
- set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能
- sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
8. 管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True) # 支持事务
# 只有两个全部执行成功, 才能通过事务
pipe.set('name', 'alex')
pipe.set('role', 'sb')
pipe.execute()
9. 发布订阅
订阅者:
import redis
r=redis.Redis(host='127.0.0.1')
pub=r.pubsub()
pub.subscribe("fm104.5")
pub.parse_response()
while 1:
msg = pub.parse_response()
print(msg)
发布者:
import redis
r=redis.Redis(host='127.0.0.1')
r.publish("fm104.5", "Hi,yuan!")
发布订阅的特性用来做一个简单的实时聊天系统再适合不过了,当然这样的东西开发中很少涉及到。再比如在分布式架构中,常常会遇到读写分离的场景,在写入的过程中,就可以使用redis发布订阅,使得写入值及时发布到各个读的程序中,就保证数据的完整一致性。再比如,在一个博客网站中,有100个粉丝订阅了你,当你发布新文章,就可以推送消息给粉丝们了
三. 小案例
我们以一个免费代理IP池能用到的操作来尝试一下redis
# 存入数据
red.set("sylar", "邱彦涛")
# 获取数据
print(red.get("sylar"))
lst = ["张三丰", "张无忌", "张翠山", "张娜拉"]
red.lpush("names", *lst) # 将所有的名字都存入names
# # 查询所有数据
result = red.lrange("names", 0, -1)
print(result)
# 从上面的操作上可以看出. python中的redis和redis-cli中的操作是几乎一样的
# 接下来, 咱们站在一个代理IP池的角度来分析各个功能
# 抓取到了IP. 保存入库
red.zadd("proxy", {"192.168.1.1": 10, "192.168.1.2": 10})
red.zadd("proxy", {"192.168.1.3": 10, "192.168.1.6": 10})
red.zadd("proxy", {"192.168.1.4": 10, "192.168.1.7": 10})
red.zadd("proxy", {"192.168.1.5": 10, "192.168.1.8": 10})
# 给某一个ip增加到100分
red.zadd("proxy", {"192.168.1.4": 100})
# 给"192.168.1.4" 扣10分
red.zincrby("proxy", -10, "192.168.1.4")
# 分扣没了. 删除掉它
red.zrem("proxy", "192.168.1.4")
# 可用的代理数量
c = red.zcard("proxy")
print(c)
# 根据分值进行查询(0~100)之间
r = red.zrangebyscore("proxy", 0, 100)
print(r)
# 查询前100个数据(分页查询)
r = red.zrevrange('proxy', 0, 100)
# 判断proxy是否存在, 如果是None就是不存在
r = red.zscore("proxy", "192.168.1.4")
print(r)
本文来自博客园,作者:{Max},仅供学习和参考
posted on 2023-04-15 15:37 huxiaofeng 阅读(65) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号