Kafka controller重设计
本文主要参考社区0.11版本Controller的重设计方案,试图给大家梳理一下Kafka controller这个组件在设计上的一些重要思考。众所周知,Kafka中有个关键组件叫controller,负责管理和协调Kafka集群。网上关于controller的源码分析也有很多,本文就不再大段地列出代码重复做这件事情了。实际上,对于controller的代码我一直觉得写的非常混乱,各种调用关系十分复杂,想要完整地理解它的工作原理确实不易。好在我们就是普通的使用者,大致了解controller的工作原理即可。下面我就带各位简要了解一下当前Kafka controller的原理架构以及社区为什么要在大改controller的设计。
Controller是做什么的
“负责管理和协调Kafka集群”的说法实在没有什么营养,上点干货吧——具体来说Controller目前主要提供多达10种的Kafka服务功能的实现,它们分别是:
- UpdateMetadataRequest:更新元数据请求。topic分区状态经常会发生变更(比如leader重新选举了或副本集合变化了等)。由于当前clients只能与分区的leader broker进行交互,那么一旦发生变更,controller会将最新的元数据广播给所有存活的broker。具体方式就是给所有broker发送UpdateMetadataRequest请求
- CreateTopics: 创建topic请求。当前不管是通过API方式、脚本方式抑或是CreateTopics请求方式来创建topic,做法几乎都是在Zookeeper的/brokers/topics下创建znode来触发创建逻辑,而controller会监听该path下的变更来执行真正的“创建topic”逻辑
- DeleteTopics:删除topic请求。和CreateTopics类似,也是通过创建Zookeeper下的/admin/delete_topics/<topic>节点来触发删除topic,controller执行真正的逻辑
- 分区重分配:即kafka-reassign-partitions脚本做的事情。同样是与Zookeeper结合使用,脚本写入/admin/reassign_partitions节点来触发,controller负责按照方案分配分区
- Preferred leader分配:preferred leader选举当前有两种触发方式:1. 自动触发(auto.leader.rebalance.enable = true);2. kafka-preferred-replica-election脚本触发。两者“玩法”相同,向Zookeeper的/admin/preferred_replica_election写数据,controller提取数据执行preferred leader分配
- 分区扩展:即增加topic分区数。标准做法也是通过kafka-reassign-partitions脚本完成,不过用户可直接往Zookeeper中写数据来实现,比如直接把新增分区的副本集合写入到/brokers/topics/<topic>下,然后controller会为你自动地选出leader并增加分区
- 集群扩展:新增broker时Zookeeper中/brokers/ids下会新增znode,controller自动完成服务发现的工作
- broker崩溃:同样地,controller通过Zookeeper可实时侦测broker状态。一旦有broker挂掉了,controller可立即感知并为受影响分区选举新的leader
- ControlledShutdown:broker除了崩溃,还能“优雅”地退出。broker一旦自行终止,controller会接收到一个ControlledShudownRequest请求,然后controller会妥善处理该请求并执行各种收尾工作
- Controller leader选举:controller必然要提供自己的leader选举以防这个全局唯一的组件崩溃宕机导致服务中断。这个功能也是通过Zookeeper的帮助实现的
Controller当前设计
当前controller启动时会为集群中所有broker创建一个各自的连接。这么说吧,假设你的集群中有100台broker,那么controller启动时会创建100个Socket连接(也包括与它自己的连接!)。当前新版本的Kafka统一使用了NetworkClient类来建模底层的网络连接(有兴趣研究源码的可以去看下这个类,它主要依赖于Java NIO的Selector)。Controller会为每个连接都创建一个对应的请求发送线程,专门负责给对应的broker发送请求。也就是说,如果还是那100台broker,那么controller启动时还会创建100个RequestSendThread线程。当前的设计中Controller只能给broker发送三类请求,它们是:
- UpdateMetadataRequest:更新元数据
- LeaderAndIsrRequest:创建分区、副本以及完成必要的leader和/或follower角色的工作
- StopReplicaRequest:停止副本请求,还可能删除分区副本
Controller通常都是发送请求给broker的,只有上面谈到的controller 10大功能中的ControlledShutdownRequest请求是例外:这个请求是待关闭的broker通过RPC发送给controller的,即它的方向是反的。另外这个请求还有一个特别之处就是其他所有功能或是请求都是通过Zookeeper间接与controller交互的,只有它是直接与controller进行交互的。
Controller组成
构成controller的组件太多了,多到我已经不想用文字表达了,直接上图吧:
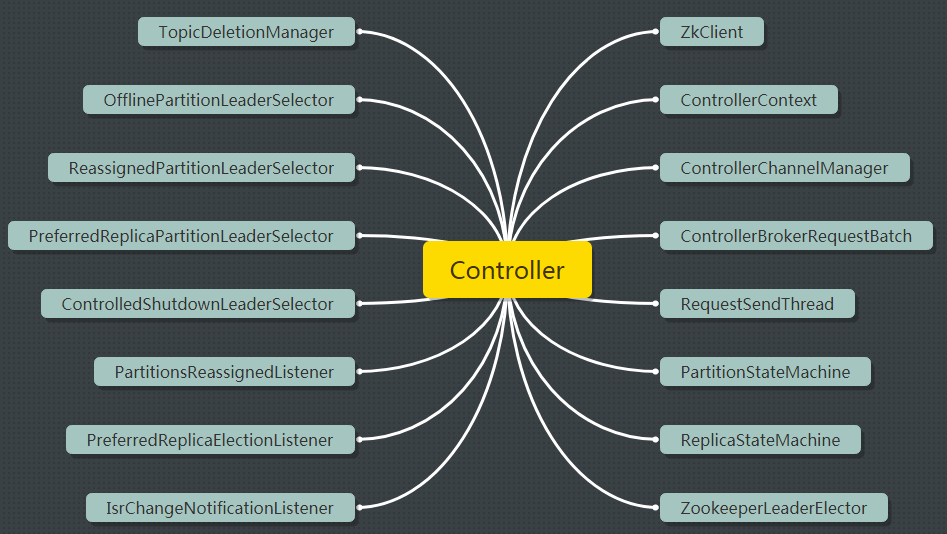
其中比较重要的组件包括:
- ControllerContext:可以说是controller的缓存。当前controller为人诟病的原因之一就是用了大量的同步机制来保护这个东西。ControllerContext的构成如下图所示:
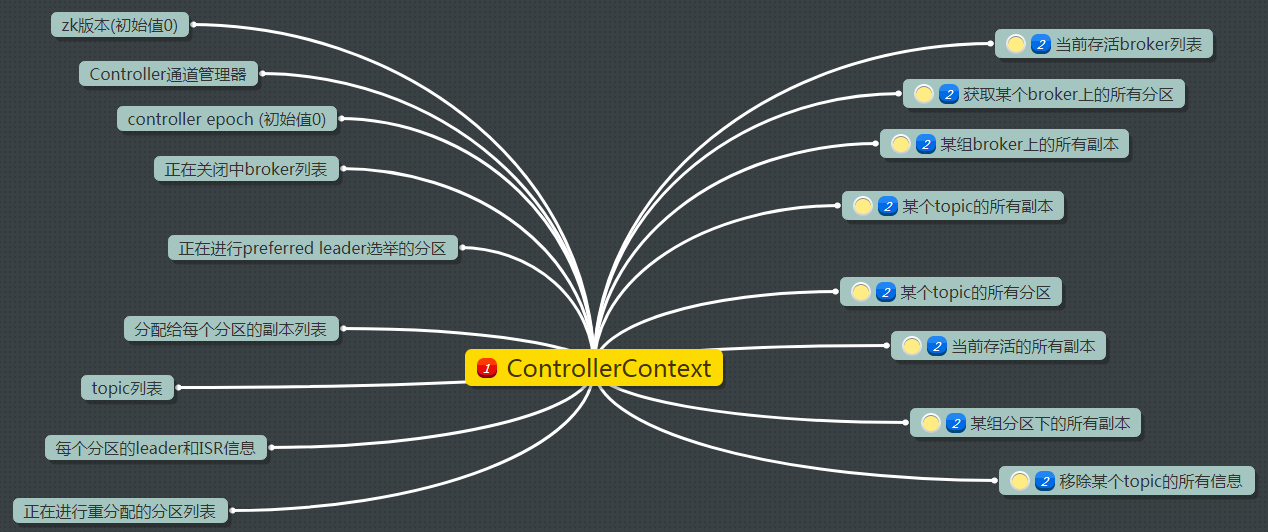
缓存内容十分丰富,这也是controller可以协调管理整个cluster的基础。
- TopicDeletionManager:负责删除topic的组件
- ****Selector:controller提供的各种功能的leader选举器
- ****Listener:controller注册的各种Zookeeper监听器。想要让controller无所不能,必然要注册各种"触角" 才能实时感知各种变化
Controller当前问题
不谦虚地说,我混迹社区也有些日子了。在里面碰到过很多关于controller的bug。社区对于这些bug有个很共性的特点,那就是没有什么人愿意(敢去)改这部分代码,因为它实在是太复杂了。具体的问题包括:
1. 需要在多线程间共享状态
编写正确的多线程程序一直是Java开发者的痛点。在Controller的实现类KafkaController中创建了很多线程,比如之前提到的RequestSendThread线程,另外ZkClient也会创建单独的线程来处理zookeeper回调,这还不算TopicDeletionManager创建的线程和其他IO线程等。几乎所有这些线程都需要访问ControllerContext(RequestSendThread只操作它们专属的请求队列,不会访问ControllerContext),因此必要的多线程同步机制是一定需要的。当前是使用controllerLock锁来实现的,因此可以说没有并行度可言。
2. 代码组织混乱
看过源代码的人相信对这一点深有体会。KafkaController、PartitionStateMachine和ReplicaStateMachine每个都是500+行的大类且彼此混调的现象明显,比如KafkaController的stopOldReplicasOfReassignedPartition方法调用ReplicaStateMachine的handleStateChanges方法,而后者又会调用KafkaController的remoteReplicaFromIsr方法。类似的情况还发生在KafkaController和ControllerChannelManager之间。
3. 管理类请求与数据类请求未分离
当前broker对入站请求类型不做任何优先级处理,不论是PRODUCE请求、FETCH请求还是Controller类的请求。这就可能造成一个问题:即clients发送的数据类请求积压导致controller推迟了管理类请求的处理。设想这样的场景,假设controller向broker广播了leader发生变更。于是新leader开始接收clients端请求,而同时老leader所在的broker由于出现了数据类请求的积压使得它一直忙于处理这些请求而无法处理controller发来的LeaderAndIsrRequest请求,因此这是就会出现“双主”的情况——也就是所谓的脑裂。此时倘若client发送的一个PRODUCE请求未指定acks=-1,那么因为日志水位截断的缘故这个请求包含的消息就可能“丢失”了。现在社区中关于controller丢失数据的bug大多是因为这个原因造成的。
4. Controller同步写Zookeeper且是一个分区一个分区地写
当前controller操作Zookeeper是通过ZkClient来完成的。ZkClient目前是同步写入Zookeeper,而同步通常意味着性能不高。更为严重的是,controller是一个分区一个分区进行写入的,对于分区数很多的集群来说,这无疑是个巨大的性能瓶颈。如果用户仔细查看源代码,可以发现PartitionStateMachine的electLeaderForPartition就是一个分区一个分区地选举的。
5. Controller按照一个分区一个分区的发送请求
Controller当前发送请求都是按照分区级别发送的,即一个分区一个分区地发送。没有任何batch或并行可言,效率很低。
6. Controller给broker的请求无版本号信息
这里的版本号类似于new consumer的generation,总之是要有一种机制告诉controller broker的版本信息。因为有些情况下broker会处理本已过期或失效的请求导致broker状态不一致。举个例子,如果一个broker正常关闭过程中“宕机”了,那么重启之后这个broker就有可能处理之前controller发送过来的StopReplicaRequest,导致某些副本被置成offline从而无法使用。而这肯定不是我们希望看到的结果,对吧?
7. ZkClient阻碍状态管理
Contoller目前是使用了ZkClient这个开源工具,它可以自动重建会话并使用特有的线程顺序处理所有的Zookeeper监听消息。因为是顺序处理,它就有可能无法及时响应最新的状态变更导致Kafka集群状态的不一致。
Controller改进方案
1. 单线程事件模型
和new consumer类似,controller摒弃多线程的模型,采用单线程的事件队列模型。这样简化了设计同时也避免了复杂的同步机制。各位在最新的trunk分支上已然可以看到这种变化:增加了ControllerEventManager类以及对应的ControllerEventThread线程类专门负责处理ControllerEvent。目前总共有9种controller event,它们分别是:
- Idle
- ControllerChange
- BrokerChange
- TopicChange
- TopicDeletion
- PartitionReassignment
- AutoLeaderBalance
- ManualLeaderBalance
- ControlledShutdown
- IsrChange
我们基本上可以从名字就能判断出它们分别代表了什么事件。
2. 使用Zookeeper的async API
将所有同步操作Zookeeper的地方都改成异步调用+回调的方式。实际上Apache Zookeeper客户端执行请求的方式有三种:同步、异步和batch。通常以batch性能最好,但Kafka社区目前还是倾向于用async替换sync。毕竟实现起来相对简单同时性能上也能得到不少提升。
3. 重构状态管理
可能摒弃之前状态机的方式,采用和GroupCoordinator类似的方式,让controller保存所有的状态并且负责状态的流转以及状态流转过程中的逻辑。当然,具体的实现还要再结合0.11最终代码才能确定。
4. 对请求排定优先级
对管理类请求和数据类请求区分优先级。比如使用优先级队列替换现有的BlockingQueue——社区应该已经实现了这个功能,开发了一个叫PrioritizationAwareBlockingQueue的类来做这件事情,后续大家可以看下这个类的源代码
5. 为controller发送的请求匹配broker版本信息
为broker设定版本号(generation id)。如果controller发送过来的请求中包含的generation与broker自己的generation不匹配, 那么broker会拒绝该请求。
6. 抛弃ZkClient,使用原生Zookeeper client
ZkClient是同步顺序处理ZK事件的,而原生Zookeeper client支持async方式。另外使用原生API还能够在接收到状态变更通知时便马上开始处理,而ZkClient的特定线程则必须要在队列中顺序处理到这条变更消息时才能处理。
结语
以上就是关于Kafka controller的一些讨论,包括了它当前的组件构成、设计问题以及对应的改进方案。有很多地方可能理解的还不是透彻,期待着在Kafka 0.11正式版本中可以看到全新的controller组件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号