【译】Kafka Producer Sticky Partitioner
最近事情多有点犯懒,依然带来一篇译文:Apache Kafka Producer Improvements with the Sticky Partitioner
消息在系统中流转的时间对于Kafka的性能来说至关重要。具体到Producer而言,Producer端的延时(Latency)通常被定义为:Producer发送消息到Kafka响应消息之间的时间间隔。俗话说得好,时间就是金钱。我们总是希望尽可能多地降低延时,让系统跑的更快。如果Producer发送消息的速度加快,整个系统都能受益。
每个Kafka topic包括若干个分区。当Producer给一个主题发送消息时,它首先需要确认这条消息要发送到哪个分区上。如果我们同时给同一个分区发送多条消息,那么Producer可以将这些消息打包成批(batch)发送。处理batch是有额外开销的。在这其中,batch中的每条消息都会贡献自己的“力量”。如果batch很小,那么batch中消息贡献的开销就越大。通常来说,小batch会导致Producer端产生更多的请求,造成更严重的队列积压效果(queueing),从而整体上推高了延时。
当batch大小达到了阈值(batch.size)或batch积累消息的时间超过了linger.ms时batch被视为“已完成”或“准备就绪”。batch.size和linger.ms都是Producer端的参数。batch.size默认值是16KB,而linger.ms默认值是0毫秒。一旦达到了batch.size值或越过了linger.ms时间,系统就会立即发送batch。
乍看上去,设置linger.ms=0似乎只会导致batch中只包含一条消息。但其实不是这样的。即使linger.ms=0,Producer依然会将多条消息打包进一个batch,只要它们是在很短的时间内被生产出来且都是发往同一个分区的。这是因为系统需要一定的时间来处理每个PRODUCE请求,而一旦系统无法及时处理所有消息,它就会将它们放入到一个batch里面。
决定batch如何形成的一个因素是分区策略(partitioning strategy)。如果多条消息不是被发送到相同的分区,它们就不能被放入到一个batch中。幸运的是,Kafka允许用户通过设置Partitioner实现类的方式来选择合适的分区策略。Partitioner接口负责为每条消息分配一个分区。默认的策略是对消息的Key进行哈希计算以获取目标分区,但是很多时候消息是没有指定Key的(或者说Key为null)。此时,Apache Kafka 2.4之前的默认策略是循环使用主题的所有分区,将消息以轮询的方式发送到每一个分区上。不幸的是,这种策略打包效果很差,在实际使用中会增加延时。
鉴于小batch可能导致延时增加,之前对于无Key消息的分区策略效率很低。社区于2.4版本引入了黏性分区策略(Sticky Partitioning Strategy)。该策略是一种全新的策略,能够显著地降低给消息指定分区过程中的延时。
黏性分区策略
黏性分区器(Sticky Partitioner)解决无Key消息分散到小batch问题的主要思路是选择单个分区发送所有的无Key消息。一旦这个分区的batch已满或处于“已完成”状态,黏性分区器会随机地选择另一个分区并会尽可能地坚持使用该分区——即所谓的粘住这个分区。这样,一旦我们拉长整个运行时间,消息还是能均匀地发布到各个分区上,避免出现分区倾斜,同时Producer还能降低延时,因为这个分配过程中始终能确保形成较大的batch,而非小batch。简单来说,整个过程如下图所示:
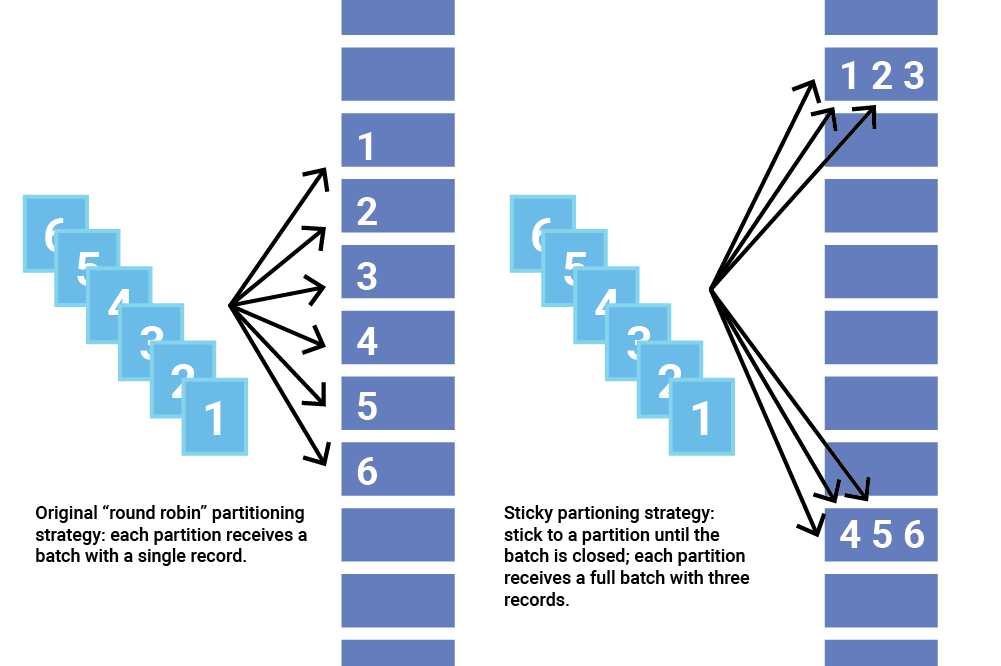
为了实现这个黏性分区器,Kafka 2.4版本为Partitioner接口新增了一个名为onNewBatch的方法。该方法会在新batch被创建前辈调用,也就是Producer要变更黏性分区(Sticky Partition)的时候。Producer默认分区器DefaultPartitioner实现了这个功能。
基础测试:Producer端延时
任何性能提升都必须要量化其效果。Kafka提供了一个名为Trogdor的测试框架(译者:官网几乎不见Trogdor的描述,有时间我写一篇blog介绍下)用于运行多种基础测试,这其中就包含测试Producer端延时。我使用了一个名为Castle的测试套件来执行ProduceBench测试。这些测试运行在一个3 Broker组成的集群上,配以1~3个Producer程序。
大多数的测试都使用如下的参数配置。你可以修改Castle配置,替换掉默认的任务参数配置。有些测试中设置稍有不同,后面会显式提及。
| Duration of test | 12 minutes |
| Number of brokers | 3 |
| Number of producers | 1–3 |
| Replication factor | 3 |
| Topics | 4 |
linger.ms |
0 |
acks |
all |
keyGenerator |
{"type":"null"} |
useConfiguredPartitioner |
true |
No flushing on throttle (skipFlush) |
true |
为了获得最好的测试效果,我们必须要设置useConfiguredPartitioner和skipFlush为true。这将确保Producer使用DefaultPartitioner执行分区策略,同时是否发送batch以batch.size和linger.ms参数来决定。当然了,你肯定要将keyGenerator设置成null,令消息无Key。
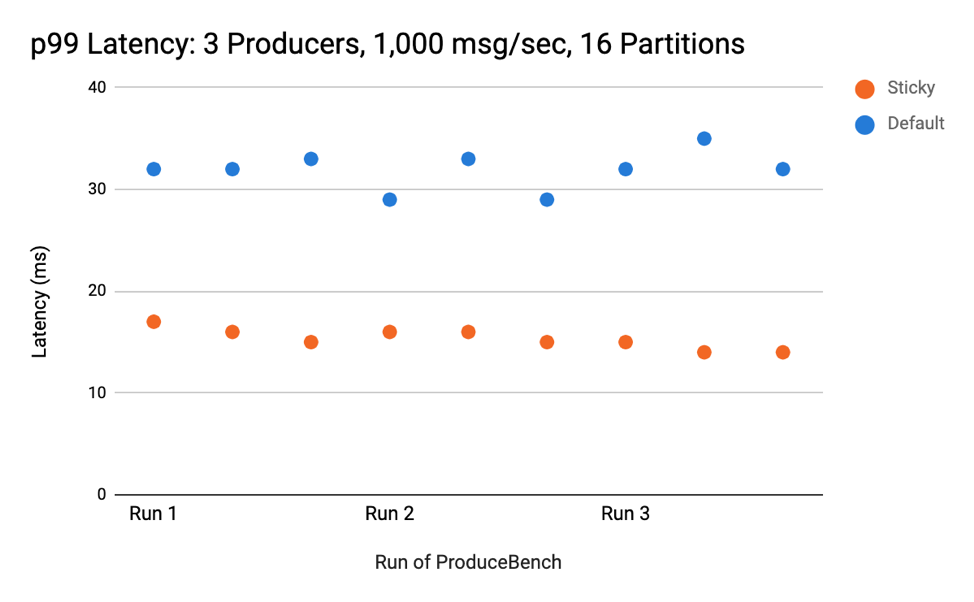
在与未修改前DefaultPartitioner的比较重,大多数测试表现出来的延时均低于之前版本。特别是在比较99百分位延时数值这一项时,3个Producer以每秒1000条消息的速度向16分区主题发送消息,测试结果表明使用新黏性分区器的Producer的延时是之前的一半。测试结果如下:
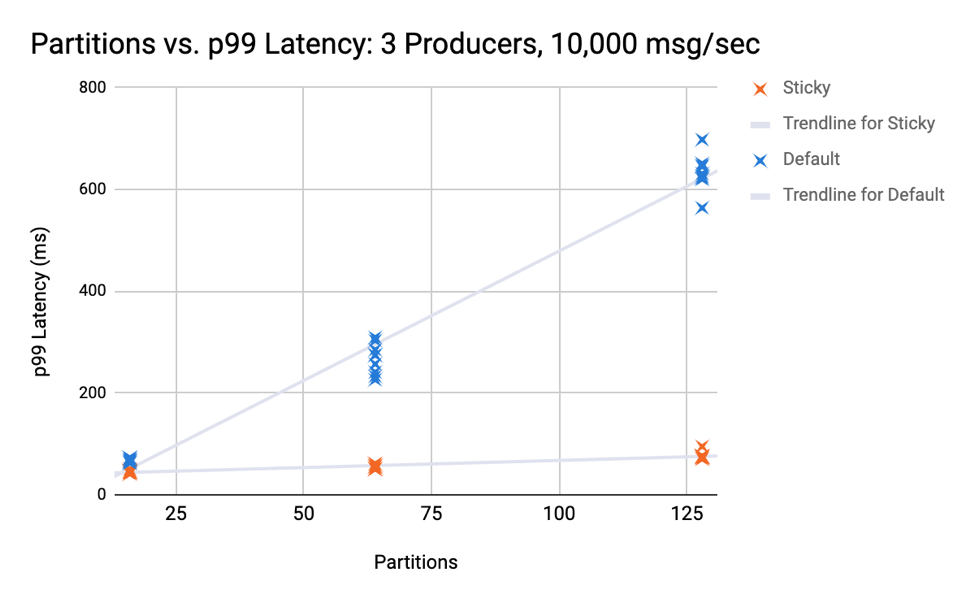
随着分区数的增加,延时下降的效果更加明显。这和我们之前的推测是吻合的:构造少量的大batch要比构造大量的小batch性能好。在我们的测试中分区数达到16时这种差异就已经很明显了。
接下来的测试保持Producer端的负载不变但增加了分区数。下图分别展示了16个、64个和128个分区的测试结果,结果表明之前分区策略的延时随着分区数的增加恶化得很快。即使是16个分区,平均的99百分位延时值依然是黏性分区器的1.5倍。
linger.ms测试以及不同Key消息的性能
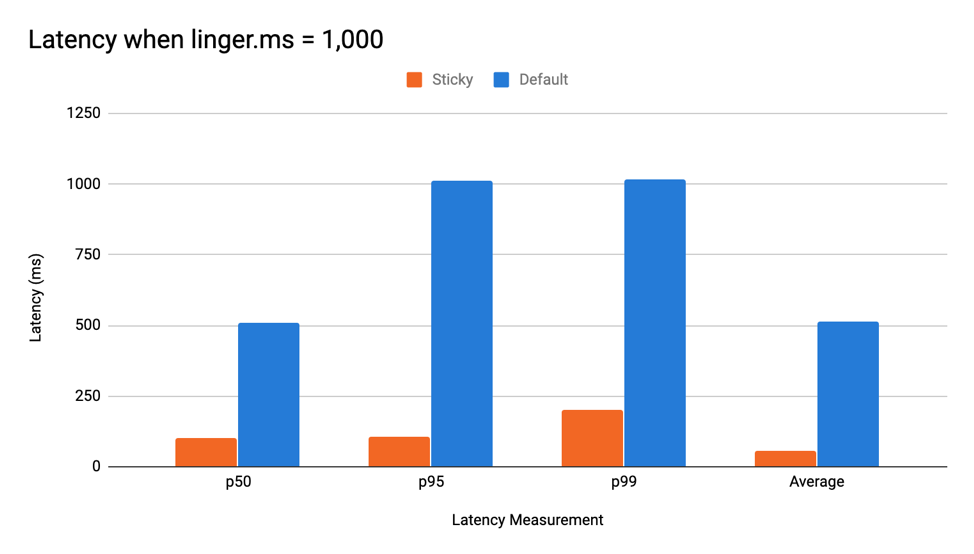
如前所述,等待linger.ms会人为地增加延时。黏性分区器的目标就是要阻止这种延时,具体办法是把所有消息都发送到一个batch中,更快地填充batch。在一个相对吞吐量很低的环境中使用黏性分区器配以一个大于0的linger.ms值能够显著降低延时。我们的测试启动了一个Producer程序,每秒发送1000条消息,同时linger.ms=1000,结果表明之前分区策略的99百分位延时值提高了5倍。下图展示了ProduceBench测试的结果:
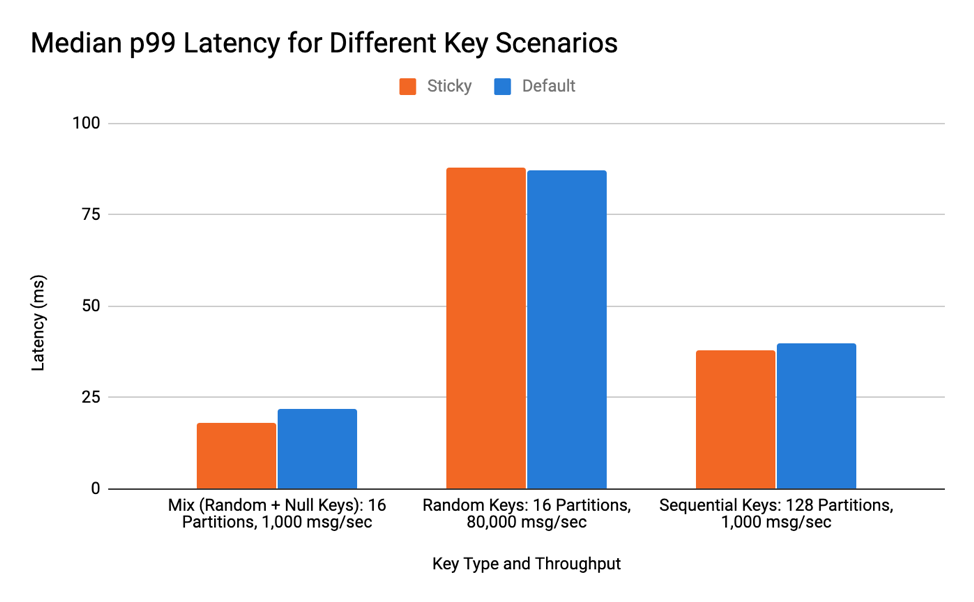
如果Producer发送的是无Key消息,那么黏性分区器能够有效提升客户端的性能。如果Producer同时发送无Key消息和有Key消息,那么性能会是如何呢?我们运行了一个测试,随机为消息生成Key同时混以一些无Key的消息,结果表明在延时这个指标上无明显区别。
在这个测试场景下,我检查了有Key和无Key的混合消息。看上去这样的打包效果更好,但是因为Key值会忽略黏性分区器,因而收益并不明显。下图展示了三次运行结果的99百分位延时值的中位数值。从测试结果来看,延时并无显著变化,因此,该中位数能够有效地表征一次典型的测试运行结果。
第二个测试场景是在高吞吐量下随机生产Key。由于实现黏性分区器需要稍微变更代码,因此我们要确保新增加的逻辑不会影响延时。鉴于这里并没有任何打包或需要黏性行为出现,看上去延时和之前的差不多也是正常的结果。随机Key测试的中位数结果如下图所示。
最后,我测试了一个我认为最不适合使用黏性分区器的场景——顺序Key + 超多分区的场景。因为新增逻辑主要发生在新batch被创建,而这个场景下差不多为每条消息都创建一个batch,因此我们必须要检查这不会推高延时。结果显示延时没有明显差异,如下图所示:
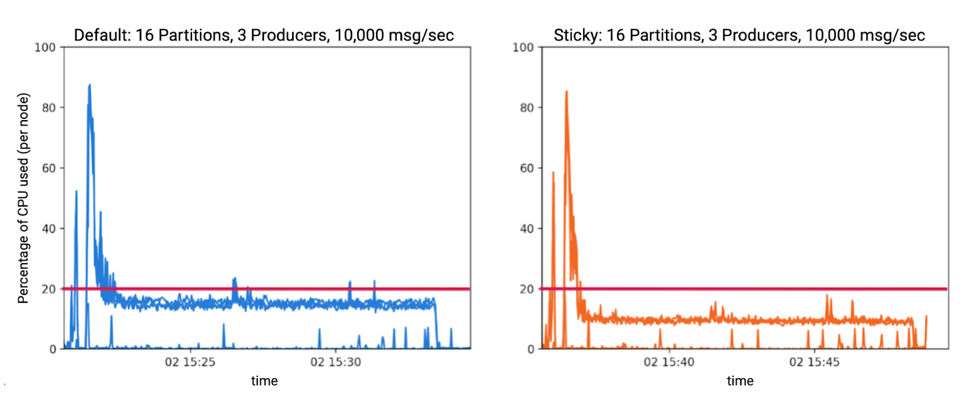
测试过程中的CPU使用率
在测试过程中,我们注意到衡量黏性分区器能够降低CPU使用率。
举例来说,当3个Producer程序以每秒1万条消息的速度向16个分区发送消息时,我们观测到CPU使用率有明显下降。下两图中的每一行都表示节点的CPU使用率。每个节点既运行Producer程序也运行Broker进程。所有节点的线重叠在一起。在分区数增加和吞吐量下降的测试场景中我们也观测到了CPU的下降。
总结
黏性分区器的主要目标是为了增加每个batch中的消息数以减少总的batch数,从而消除不必要的queueing时间。一旦batch中消息变多,batch数变少,每条消息的成本就降低了。使用黏性分区策略能够更快地发送消息。测试数据已经证明该策略确实能够为无Key消息降低延时,并且当分区数增加时提升的效果更加明显。另外,使用黏性分区策略通常还能降低CPU使用。通过将Producer“黏在”一个分区并发送更少的大batch的方式,Producer能够有效地提升发送性能。
同时,最酷的是:这个黏性分区器默认集成在2.4版本,无需额外配置,开箱即用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号