基于知识的自动综合策略
(一)基于知识的决策
决策就是根据已有的信息作出各种可能的推导和判断,从而选择最优方案。当已有的信息确定时,决策过程可根据已有的、确定的信息建立数学模型,利用计算机求最优解。一般来讲,一个普通决策模型至少应该是一个三元体:{O,S,Y},O为状态空间,S为决策空间,Y为后果函数。
常用的决策算法模型中,用于解决复杂问题的主要有模糊决策中的模糊贝叶斯决策算法模型和多准则决策中的最小隶属度带权平均偏差法、最大隶属度带权平均规划法。
下面主要介绍最大隶属度带权平均规划法:
设有n个决策方案,决策方案集X为{x1,x2,...xn},每个方案中选择考虑m个对象,每个方案中的对象集O为{o1,o2,...om}。所以由决策方案集中的对象构成的决策矩阵为:
X=[x1,x2,...xn]
xi=[o1i,o2i,...omi]T
=>X=[xmn]
=>R=[rmn]
由于矩阵X中每个单元的量纲不一样,下面需要统一矩阵X中的量纲,得到矩阵R:
R=[rmn]
其中rij=xij/maxi=ixij或mini=ixij/xij
在决策过程中,由于决策者有对结果不同的期望,所以可以对方案中每个对象赋予一个权重w,下面定义一个权值矩阵:
W=[w1,w2,...wm]
其中wi可以指定或者待定由X矩阵计算出最优w,
最后通过D=W×R,得出最终的决策向量。
D=[d1,d2,...dn]
D中dj的代表决策中方案j的综合评价。
(二)在地图综合中的应用
2.1 主支流的判断
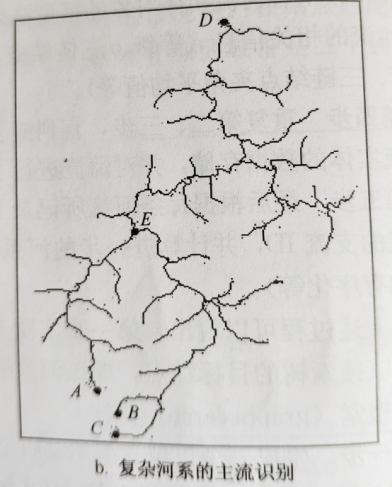 如图,主流是确定为DA、DB或是DC,通过视觉难以决策。在此我们引入多尺度决策模型
如图,主流是确定为DA、DB或是DC,通过视觉难以决策。在此我们引入多尺度决策模型
定义用于决策的属性对象集O={长度,角度,支流数},决策的方案及X={所有河口到河源能形成的河流}
长度(length)定义为河口到河源的完整的河流长度,
角度(angle)定义为完整河流上,所有的三链结点所形成的角度的平均值,三链结点角度定义如下图。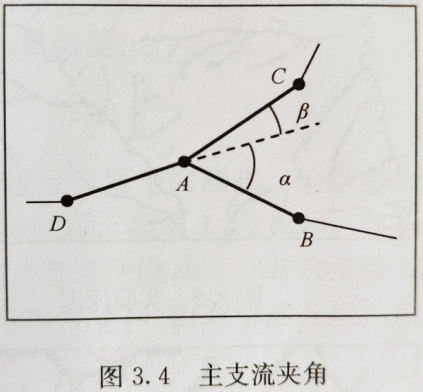
支流数定义为河流的支流数。
单从长度来看,长度越长的方案是越优的方案;单从角度来看,平均角度越小的方案是越优的方案;单从支流数来看,支流数越多是越优的方案,但是支流数对决策起的影响不大,所以赋予相对较小的权重值。
对于计算结果区综合评价最高的方案为河流的主流选取方案。
然后,对于与主流直接相邻的支流,定义为二级主流备选河流,并对其依次使用多准则决策法进行确定主流;
如果还有支流,则循环调用以上方法,直至无支流。
在算法运行的期间,对整个河系建立树的数据结构存储河系数据。
2.2 基于知识的人工河网自动选取
先对人工河网数据采用动态分段的思想,建立动态分段的数据模型:
1、采用基于栅格的网络密度探测方法:将数据分割存储在离散的栅格之中,并计算每一个栅格的线密度dij=lenij/S面积。为了简化运算,对密度进行分级,Dij=dij/dmax。Dij处于0~1之间,将其分为4等Gij。
2、按照河流流经的栅格格网,对河流进行动态分段分为n段。
3、计算河流流域的河网密度:grade=∑1~n(Gi×leni/len)
在建立的河流数据模型中,还包括河流的主次属性、与天然水体的连接情况。
在建立好河流数据模型以后,开始对河网的自动选取建立决策模型:
取决策的对象集O={长度,主次属性,流域河网密度、与天然水体连接情况}
决策集X={河网中全体河流}
按照上文的计算方法求得决策矩阵D=[d1,d2,...dn](共n条河流)
对于地图综合的要求,求得需要保留的n1条,则需要删除n-n1条。
为了保证人工河网的网络特征,采用一种特殊的删除法:
求D中最小的d的下标奇偶性,删除与d同奇偶性的倒数n-n1条河流。从而较好的保证人工河网的网络特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号