

scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析。本篇文章则是通过利用fiddler抓包获取json数据分析Ajax页面的具体请求内容,找到获取数据的接口url,直接调用该接口获取数据,省去了引入python-webkit库的麻烦,而且由于一般ajax请求的数据都是结构化数据,这样更省去了我们利用xpath解析html的痛苦。
手机打开糗事百科APP ,利用fiddler抓包获取json数据 检查 得到的接口url是否能正常访问 如果能访问在换个浏览器试试 如图
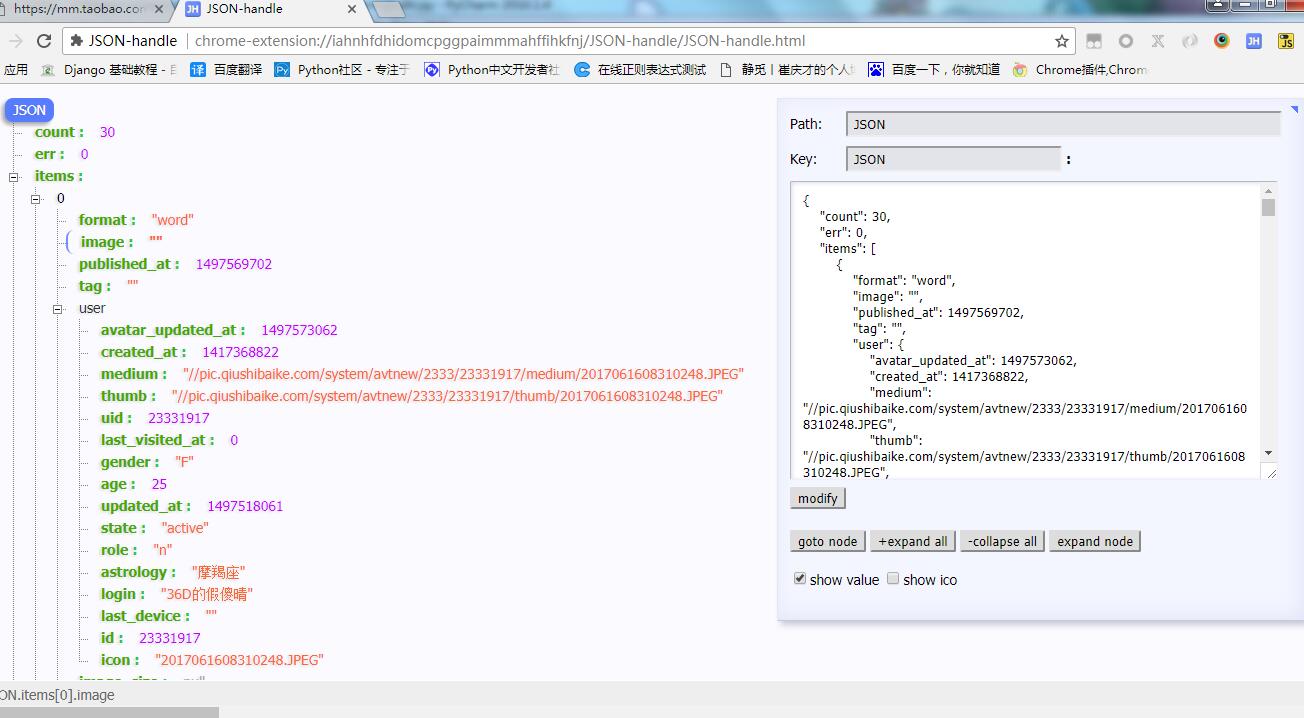
打开之后的json数据如图推荐用json—handle插件(chrome安装)打开
代码实现:以99页为例
items.py


1 import scrapy 2 3 4 class QiushibalkeItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 uid=scrapy.Field() 8 nickname = scrapy.Field() 9 gender=scrapy.Field() 10 11 astrology=scrapy.Field() 12 13 content=scrapy.Field() 14 crawl_time=scrapy.Field()
spiders/qiushi.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import json 4 from qiushibalke.items import QiushibalkeItem 5 from datetime import datetime 6 class QiushiSpider(scrapy.Spider): 7 name = "qiushi" 8 allowed_domains = ["m2.qiushibaike.com"] 9 def start_requests(self): 10 for i in range(1,100): 11 url = "https://m2.qiushibaike.com/article/list/text?page={}".format(i) 12 yield scrapy.Request(url,callback=self.parse_item) 13 14 15 def parse_item(self, response): 16 datas = json.loads(response.text)["items"] 17 print(datas) 18 for data in datas: 19 # print(data['votes']['up']) 20 # print(data['user']['uid']) 21 # print(data['user']["login"]) 22 # print(data['user']["gender"]) 23 # print(data['user']["astrology"]) 24 25 item = QiushibalkeItem() 26 item["uid"]= data['user']["uid"] 27 28 item["nickname"] = data['user']["login"] 29 item["gender"] = data['user']["gender"] 30 31 item["astrology"] = data['user']["astrology"] 32 item["content"]=data["content"] 33 item["crawl_time"] = datetime.now() 34 35 yield item 36
pipelines.py
import pymysql class QiushibalkePipeline(object): def process_item(self, item, spider): con = pymysql.connect(host="127.0.0.1", user="youusername", passwd="youpassword", db="qiushi", charset="utf8") cur = con.cursor() sql = ("insert into baike(uid,nickname,gender,astrology,content,crawl_time)" "VALUES(%s,%s,%s,%s,%s,%s)") lis = (item["uid"],item["nickname"],item["gender"],item["astrology"],item["content"],item["crawl_time"]) cur.execute(sql, lis) con.commit() cur.close() con.close() return item
settings.py
1 BOT_NAME = 'qiushibalke' 2 3 SPIDER_MODULES = ['qiushibalke.spiders'] 4 NEWSPIDER_MODULE = 'qiushibalke.spiders' 5 ROBOTSTXT_OBEY = False 6 DOWNLOAD_DELAY = 5 7 COOKIES_ENABLED = False 8 DEFAULT_REQUEST_HEADERS = { 9 "User-Agent":"qiushibalke_10.13.0_WIFI_auto_7", 10 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 11 # 'Accept-Language': 'en', 12 } 13 ITEM_PIPELINES = { 14 'qiushibalke.pipelines.QiushibalkePipeline': 300, 15 # 'scrapy_redis.pipelines.RedisPipeline':300, 16 }
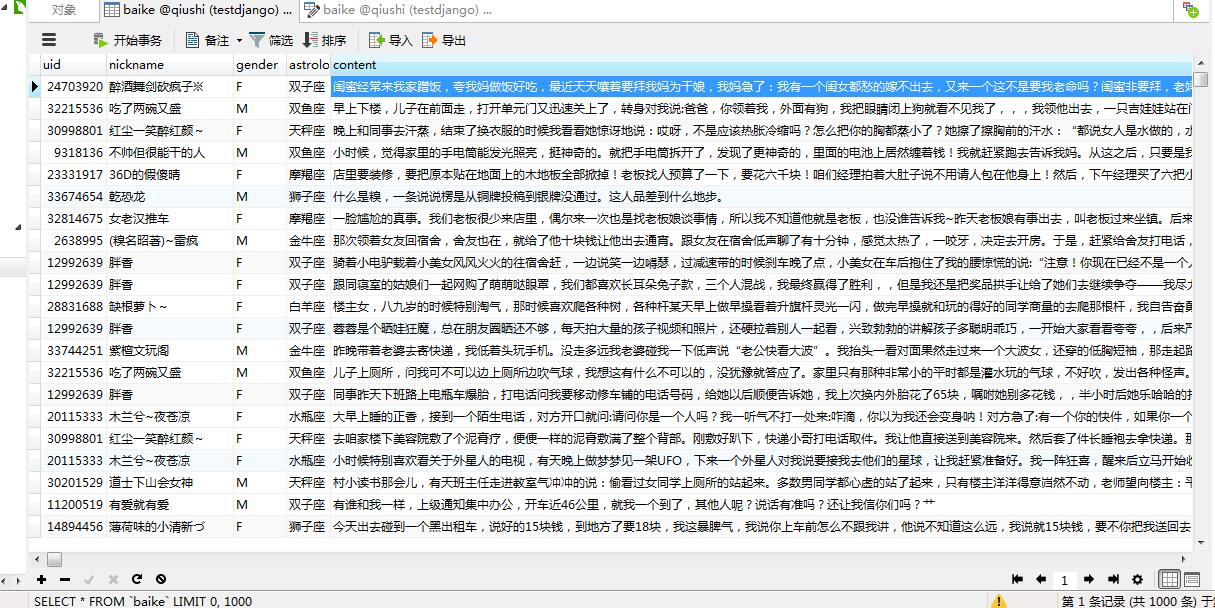
数据如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号