基于menu小插件探索工程实践
计算机软件发展也有很多年了,软件工程越来越复杂,对代码的重用,工程的抽象和模块化需求越来越大,从一开始的面相过程,到面向对象,再到组件,微服务……现借本次课程的机会,梳理一下软件工程中基本的实践方法,看看他是怎么给工程带来便利和好处的。
一、准备工作
1、C/C++环境搭建
本机是MAC,可以使用指令brew install gcc gdb来安装C/C++的编译器和调试器,安装完毕后,可用gcc -v来查看版本,如果有信息,则安装成功:
huth@promote ~ % gcc -v
Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-dir=/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/c++/4.2.1
Apple clang version 12.0.0 (clang-1200.0.32.21)
Target: x86_64-apple-darwin19.6.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
huth@promote ~ %
可以看到一些关键信息:
version(版本): Apple clang version 12.0.0 (clang-1200.0.32.21)
Thread model(线程标准): posix
Target(运行的环境): x86_64-apple-darwin19.6.0
* GCC的一点科普:
GCC(GNU Compiler Collection,GNU编译器套件)是由GNU开发的编程语言译器。GNU编译器套件包括C、C++、 Objective-C、 Fortran、Java、Ada和Go语言前端,也包括了这些语言的库(如libstdc++,libgcj等。)
2、VSCode的配置
(1) 安装插件:
VSCode是一个非常强大的编辑器,可搭载好用的插件。那么要使得在VSCode上能编译运行C/C++程序,自然也要安装插件:

这个插件是用来代码提示,代码高亮和代码提示用的,它本身不能编译,是要靠GCC里编译器来完成。
(2) 设置配置文件:
- tasks.json:
![]()
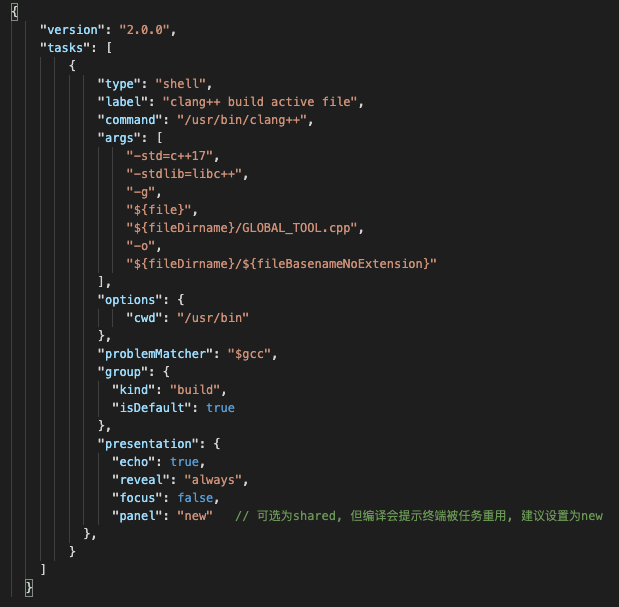
该文件主要是用来设置编译命令的,上图中的就是相当于,在终端调用了:
/usr/bin/clang++ -std=c++17 -stdlib=libc++ -g [file] [fileDirname]/GLOBAL_TOOL.cpp -o [fileDirname/[不带后缀名的文件名]
-
settings.json:
一些设置:
![]()
-
launch.json:
主要是启动生成后的可执行文件:
![]()
-
c_cpp_properties.json:
在Mac上貌似最好要配置上这个文件:
![]()
二、工程化编程实战
现有一个工程实践,即在主程序的基础加上menu功能,对menu传入指令,可以执行相关命令,有点开菜单,选择功能选项的意味。
1、模块化设计
类的存在,便开始对代码进行封装和抽象,粒度变粗,方便重用和管理。但往往类只管理一个很小的单元,由于高内聚,低耦合的要求,不太可能在一个类里加上过多的内容。比某个复杂功能的模块,它可能就需要多个类的支持与协作,当然我们可以把这些类零散地提供出去,但这样文件数量过多,不够整洁,不易管理。所以,便有了更抽象的,更粗粒度的存在:模块,或者叫组件/构件(Component),这样在编译的时候,可以将多个类生成的obj文件链接成一个完整的dll(动态库),最后的将这些动态库协同工作,便有一个完整的应用。
在这个menu的例子里,会简单的展现模块化思想,不会用上dll。
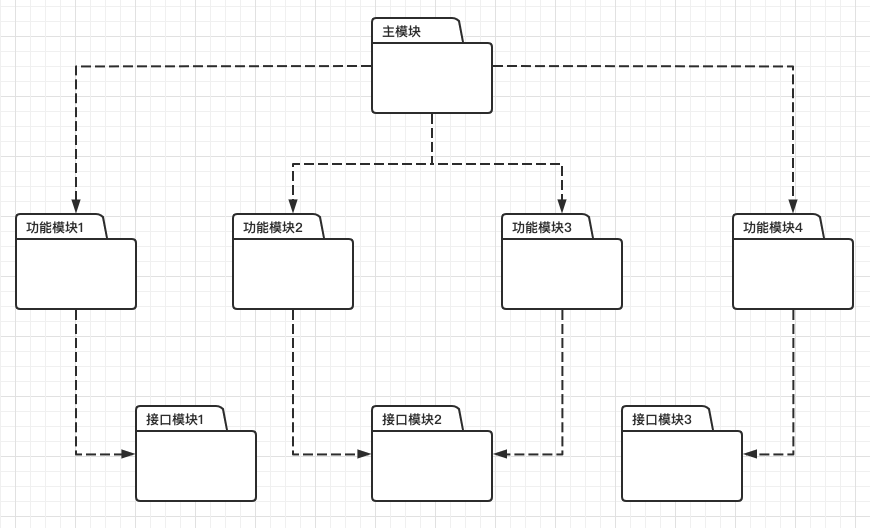
先看一下开发视图:

图中,menu包里实际只有一个obj,但也还是可以当作一个模块,只是比较简单。
test_exec包有一个main入口函数,它的内容是:
int main()
{
PrintMenuOS();
SetPrompt("MenuOS>>");
MenuConfig("version","MenuOS V1.0(Based on Linux 3.18.6)",NULL);
MenuConfig("quit","Quit from MenuOS",Quit);
MenuConfig("time","Show System Time",Time);
MenuConfig("time-asm","Show System Time(asm)",TimeAsm);
MenuConfig("fork","Fork a new process",Fork);
MenuConfig("exec","Execute a program",Exec);
ExecuteMenu();
}
可见,它调用了"MenuConfig", "SetPrompt"和"ExecuteMenu"方法,而这些方法便是menu里的,通过#include "menu.h"引入,可以把这种方法理解为menu的接口,API。
不过在面向对象的编程里,应该尽量遵循依赖倒置原则,同时满足Liskov原则,即使用多态的方法,代码里使用父类,在运行时,动态绑定到具体的子类。不过此处menu是在c上实现,并且也足够底层,没必要再抽象(出了链表部分)。
以上,这种模块化的好处便是:
- 代码整洁,test_exec.c文件里不用写以上三种方法,它只需关注主流程的实现,将这种具体的功能抽离出去;
- 降低耦合和增加内聚,并使得各模块职责单一,便于管理,调试修改;
- 便于代码重构,模块间影响小,如果我把menu修改了,test_exec不用管这些,只管调用。
进一步来说,它对软件架构里的质量属性产生影响:
- 运行时的:
- 性能:实际上,因为多了个obj,test_exec之间用链接关联,势必在性能上有降低,但可忽略不计;
- 可用性/可靠性:因为这种解耦,可能会出现一些不稳定情况,比如menu和test_exec有include了相同的文件,那么可能会出现重复定义的错误;但好在出错后,容易解决和恢复,因为模块化,容易定位错误的位置,修改代码,对其他模块影响小; - 开发时:
- 可维护性:较高,因为耦合度低;
- 可配置性:由以上代码来看,其实较差,因为指令都写在了代码里,所以,具体代码可以抽离出来,放在一个配置文件里,之后用读文件的方式来读取指令,这样下次修改指令时,不用再在代码里修改,修改之后也不用再重新编译;
扩展:举一个以前工作中供用户二次开发的模块的例子
以下上用例图和开发视图:

主程序的运行,便是有多个dll协作的,非常方便管理。同时有一些功能可以让用户自己定义,所以提供了一些包含有虚函数的类的dll。当用户实现后,放在指定的位置,主程序工作后,会检测接口的dll,在运行的过程中如果有实现里面的方法,便调用它,所以,可修改性,扩展性也很强。
2、可重用设计:进一步抽象
menu的进一步优化
注意到menu主要是负责菜单功能,并且在这个菜单中的功能是用链表来存储管理的,如下:
typedef struct DataNode
{
char* cmd;
char* desc;
int (*handler)();
struct DataNode *next;
} tDataNode;
static tDataNode head[] =
{
{"help", "this is help cmd!", Help,&head[1]},
{"version", "menu program v1.0", NULL, &head[2]},
{"quit", "Quit from menu", Quit, NULL}
};
menu工作的逻辑便是,接收cmd,再循环查看功能列表,找到匹配的,并执行对应的方法,这也是Call-in方式:
while(p != NULL)
{
if(strcmp(p->cmd, cmd) == 0)
{
printf("%s - %s\n", p->cmd, p->desc);
if(p->handler != NULL)
{
p->handler();
}
break;
}
p = p->next;
}
但是这样,链表的操作和menu的功能耦合起来了,不是个很好的方式,链表有很多操作,比如:创建,删除,添加,查找结点等等……这些方法要是都写在menu里,会很杂乱,不利于维护。
所以我们要将链表的一切抽离出来,单独创建一个linktable模块:
typedef struct LinkTableNode
{
struct LinkTableNode * pNext;
}tLinkTableNode;
/*
* LinkTable Type
*/
typedef struct LinkTable tLinkTable;
/*
* Create a LinkTable
*/
tLinkTable * CreateLinkTable();
/*
* Delete a LinkTable
*/
int DeleteLinkTable(tLinkTable *pLinkTable);
/*
* Add a LinkTableNode to LinkTable
*/
int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
……
在menu中,可以这么使用:
typedef struct DataNode
{
tLinkTableNode * pNext;
char* cmd;
char* desc;
int (*handler)(int argc, char *argv[]);
} tDataNode;
menu中用DataNode包裹了一层,实际上就是将单纯的链表结点和对应的命令和描述、回调方法分开。
接下来说明menu实现的主要流程:
- 首先,menu的功能目前都是写死在代码里的,只有
help,version,quit,这样其可配置性,可修改性很差,我们当然希望在更上层的程序使用menu时,可自定义menu的功能组成,所以我们要把功能设置提出来成一个API:
/* add cmd to menu */
int MenuConfig(char * cmd, char * desc, int (*handler)())
{
tDataNode* pNode = NULL;
if ( head == NULL)
{
head = CreateLinkTable();
pNode = (tDataNode*)malloc(sizeof(tDataNode));
pNode->cmd = "help";
pNode->desc = "Menu List";
pNode->handler = Help;
AddLinkTableNode(head,(tLinkTableNode *)pNode);
}
pNode = (tDataNode*)malloc(sizeof(tDataNode));
pNode->cmd = cmd;
pNode->desc = desc;
pNode->handler = handler;
AddLinkTableNode(head,(tLinkTableNode *)pNode);
return 0;
}
这样上层调用时,可通过MenuConfig来创建一个结点tDataNode,并将该node的指针转成(tLinkTableNode *),再追加到menu的链表后。为何要转指针类型,是为了方便后面单纯的链表的查询,观察两个Node的结构体可以发现,它们的第一个属性都是tLinkTableNode * pNext,所以转换成(tLinkTableNode *)后,依然可以正常访问其内容:
- 接下来是关键,因为我们把链表的操作抽离出来了,那么查询功能实际上是对linktable的tLinkTableNode进行匹配查询,那么怎么和menu的tDataNode关联起来呢?
这里有个关键的函数,在linktable模块里:
tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args)
{
if(pLinkTable == NULL || Conditon == NULL)
{
return NULL;
}
tLinkTableNode * pNode = pLinkTable->pHead;
while(pNode != NULL)
{
if(Conditon(pNode,args) == SUCCESS)
{
return pNode;
}
pNode = pNode->pNext;
}
return NULL;
}
这里有一个回调函数Condition,用来给出判决结果,由判决结果来选择Node。如何判决,由调用者传入,menu便是这个调用者,这样menu和linktable便连接起来了。menu是如何调用的?是在ExecuteMenu的方法里:
tDataNode *p = (tDataNode*)SearchLinkTableNode(head,SearchConditon,(void*)argv[0]);
(void*)argv[0]是传入的cmd,而SearchCondition便是判决方法:
int SearchConditon(tLinkTableNode * pLinkTableNode,void * arg)
{
char * cmd = (char*)arg;
// 转成(tDataNode *),便于访问cmd
tDataNode * pNode = (tDataNode *)pLinkTableNode;
// 关键:strcmp(pNode->cmd, cmd),根据传入的cmd匹配结点
if(strcmp(pNode->cmd, cmd) == 0)
{
return SUCCESS;
}
return FAILURE;
}
以上体现了Call-back或者说是回调函数的好处,优势。它可以在不影响低耦合的情况下,保持模块间的联系。
且linktable的抽离和MenuConfig方法的提供,使得代码可重用度提高。
可重入函数和线程安全
可重入的概念
可重入代码,可以用于任务并发,当线程切换发生,不用担心数据丢失;不可重入的代码是互斥的,是应该在临界区内禁止中断的。
基本的要求:
- 不为连续的调用持有静态数据;
- 不返回指向静态数据的指针;
- 所有数据都由函数的调用者提供;
- 使用局部变量,或者通过制作全局数据的局部变量拷贝来保护全局数据;
- 使用静态数据或全局变量时做周密的并行时序分析,通过临界区互斥避免临界区冲突;
- 绝不调用任何不可重入函数。
线程安全的概念
线程安全是指在线程以任意次序进行,都不会影响预期结果的实现。不安全一般是发生在两个线程有对全局/局部变量写操作的存在,此时需要对它们进行同步或互斥访问变量。
两者之间的关系
- 可重入的函数不一定是线程安全的,可能是线程安全的也可能不是线程安全的;可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题;
- 不可重入的函数一定不是线程安全的。
对linktable模块的分析
这个也很容易想到,因为linktable有crud操作,势必会对结点产生修改。如果此时存在多个线程并发使用同一张linktable的话,那必须要互斥访问,比如添加一个node:
int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode)
{
if(pLinkTable == NULL || pNode == NULL)
{
return FAILURE;
}
pNode->pNext = NULL;
pthread_mutex_lock(&(pLinkTable->mutex));
if(pLinkTable->pHead == NULL)
{
pLinkTable->pHead = pNode;
}
if(pLinkTable->pTail == NULL)
{
pLinkTable->pTail = pNode;
}
else
{
pLinkTable->pTail->pNext = pNode;
pLinkTable->pTail = pNode;
}
pLinkTable->SumOfNode += 1 ;
pthread_mutex_unlock(&(pLinkTable->mutex));
return SUCCESS;
}
但添加node时,势必会对前一个结点(如果不在头部插入的话)的pNext属性进行修改,这时候需要给其上锁:pthread_mutex_lock(&(pLinkTable->mutex)); mutex是一个互斥的信号量,由LinkTable持有,仅有一个,那么此处的上锁粒度自然是整张链表。当一切操作完毕,解锁:pthread_mutex_unlock(&(pLinkTable->mutex));
由于这里的锁只有一个,当一个方法访问敏感区域时,都会去索要这个锁,如果已经有其他方法要走,并且没有退出临界区,那么该方法必须阻塞,等对方退出。所以有了锁机制之后便是安全的了,不会有多个方法同时进入临界区。
线程安全就是要保证数据的一致性,避免出现写丢失,不可重复读,脏读,幻读等情况,需要对临界区上锁,但同时也要避免死锁,这是个复杂的问题。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号