

深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生。但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层。本文将首先引入Dropout的原理和实现,然后观察现代深度模型Dropout的使用情况,并与BN进行实验比对,从原理和实测上来说明Dropout已是过去式,大家应尽可能使用BN技术。
一、Dropout原理
根据wikipedia定义,dropout是指在神经网络中丢弃掉一些隐藏或可见单元。通常来说,是在神经网络的训练阶段,每一次迭代时,都会随机选择一批单元,让其被暂时忽略掉,所谓的忽略是不让这些单元参与前向推理和后向传播。
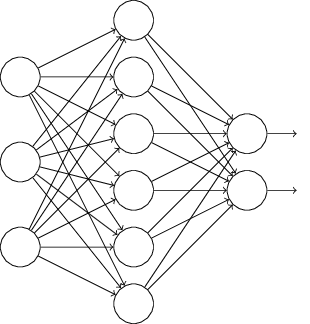
上图是标准的神经网络,经过dropout后,则变成如下图:
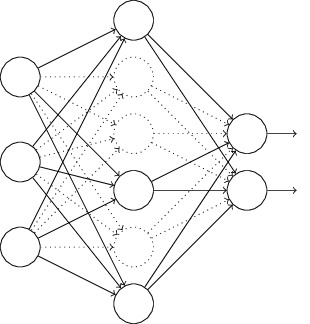
一般来说,我们在可能发生过拟合的情况下才会使用dropout等正则化技术。那什么时候可能会发生呢?比如神经网络过深,或训练时间过长,或没有足够多的数据时。那为什么dropout能有效防止过拟合呢?可以理解为,我们每次训练迭代时,随机选择一批单元不参与训练,这使得每个单元不会依赖于特定的前缀单元,因此具有一定的独立性;同样可以看成我们拿同样的数据在训练不同的网络,每个网络都有可能过拟合,但迭代多次后,这种过拟合会被抵消掉。
要注意的是,dropout是体现在训练环节,训练完成后,我们认为所有的单元都被训练好了,在验证或测试阶段,我们是拿完整的神经网络去验证或测试。
二、Dropout具体实现
以keras为例,其代码为:keras.backend.dropout(x, level, noise_shape=None, seed=None),其中x指的是输入参数,level则是keep-prob,也就是这个单元有多少概率会被设置为0。
import tensorflow.keras.backend as K input = K.random_uniform_variable(shape=(3, 3), low=0, high=1) print("dropout with keep-prob 0.5:", K.eval(K.dropout(input, 0.5))) print("dropout with keep-prob 0.2:", K.eval(K.dropout(input, 0.2))) print("dropout with keep-prob 0.8:", K.eval(K.dropout(input, 0.8)))
看看输出结果:
dropout with keep-prob 0.5: [[1.190095 0. 1.2999489] [0. 0.3164637 0. ] [0. 0. 0. ]] dropout with keep-prob 0.2: [0.74380934 0.67237484 0.81246805] [0.8819132 0.19778982 1.2349881 ] [1.0369372 0.5945368 0. ]] dropout with keep-prob 0.8: [[0. 0. 0. ] [0. 0. 4.9399524] [4.147749 2.3781471 0. ]]
可以看出,level值越大,每个单元成为0的概率也就越大。
在具体的keras应用中,dropout通常放在激活函数后,比如:
model=keras.models.Sequential() model.add(keras.layers.Dense(150, activation="relu")) model.add(keras.layers.Dropout(0.5))
三、Dropout正在被抛弃
随着深度学习的发展,Dropout在现代卷积架构中,已经逐步被BN(想要了解BN,大家可以参见我之前写的 深度学习基础系列(七)| Batch Normalization 一文,这里不再赘述)取代,BN也同样拥有不亚于Dropout的正则化效果。
“We presented an algorithm for constructing, training, and performing inference with batch-normalized networks. The resulting networks can be trained with saturating nonlinearities, are more tolerant to increased training rates, and often do not require Dropout for regularization.” -Ioffe and Svegedy 2015
至于为何Dropout不再受青睐,原因如下:
- Dropout在卷积层的正则效果有限。相比较于全连接层,卷积层的训练参数较少,激活函数也能很好地完成特征的空间转换,因此正则化效果在卷积层不明显;
- Dropout也过时了,能发挥其作用的地方在全连接层,可当代的深度网络中,全连接层也在慢慢被全局平均池化曾所取代,不但能减低模型尺寸,还可以提升性能。
事实上,我们可以看看keras实现的现代经典模型,就可以窥之dropout目前的处境。打开keras的地址:https://github.com/keras-team/keras-applications

纵观无论是VGG、ResNet、Inception、MobileNetV2等模型,都不见了Dropout踪影。唯独在MobileNetV1模型里,还可以找到Dropout,但不是在卷积层;而且在MobileNetV2后,已经不再有全连接层,而是被全局平均池化层所取代。如下图所示:

其他模型也类似,纷纷抛弃了Dropout和全连接层。
四、Dropout VS BatchNormalization
我们需要做一个简单实验来验证上述理论的成立,实验分五种测试模型:
- 没有使用Dropout,也没有使用BN;
- 使用了Dropout,不使用BN,使训练单元为0的概率为0.2;
- 使用了Dropout,不使用BN,使训练单元为0的概率为0.5;
- 使用了Dropout,不使用BN,使训练单元为0的概率为0.8;
- 使用了BN,不使用Dropout
代码如下:
import keras from keras.datasets import cifar10 from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization from keras.layers import Conv2D, MaxPooling2D from matplotlib import pyplot as plt import numpy as np # 为保证公平起见,使用相同的随机种子 np.random.seed(7) batch_size = 32 num_classes = 10 epochs = 40 data_augmentation = True # The data, split between train and test sets: (x_train, y_train), (x_test, y_test) = cifar10.load_data() # Convert class vectors to binary class matrices. y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 def model(bn=False, dropout=False, level=0.5): model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:])) if bn: model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) if bn: model.add(BatchNormalization()) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) if dropout: model.add(Dropout(level)) model.add(Conv2D(64, (3, 3), padding='same')) if bn: model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) if bn: model.add(BatchNormalization()) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) if dropout: model.add(Dropout(level)) model.add(Flatten()) model.add(Dense(512)) if bn: model.add(BatchNormalization()) model.add(Activation('relu')) if dropout: model.add(Dropout(level)) model.add(Dense(num_classes)) model.add(Activation('softmax')) if bn: opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-6) else: opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # 使用数据增强获取更多的训练数据 datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) datagen.fit(x_train) history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), epochs=epochs, validation_data=(x_test, y_test), workers=4) return history no_dropout_bn_history = model(False, False) dropout_low_history = model(False, True, 0.2) dropout_medium_history = model(False, True, 0.5) dropout_high_history = model(False, True, 0.8) bn_history = model(True, False) # 比较多种模型的精确度 plt.plot(no_dropout_bn_history.history['val_acc']) plt.plot(dropout_low_history.history['val_acc']) plt.plot(dropout_medium_history.history['val_acc']) plt.plot(dropout_high_history.history['val_acc']) plt.plot(bn_history.history['val_acc']) plt.title('Model accuracy') plt.ylabel('Validation Accuracy') plt.xlabel('Epoch') plt.legend(['No bn and dropout', 'Dropout with 0.2', 'Dropout with 0.5', 'Dropout with 0.8', 'BN'], loc='lower right') plt.grid(True) plt.show() # 比较多种模型的损失率 plt.plot(no_dropout_bn_history.history['val_loss']) plt.plot(dropout_low_history.history['val_loss']) plt.plot(dropout_medium_history.history['val_loss']) plt.plot(dropout_high_history.history['val_loss']) plt.plot(bn_history.history['val_loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['No bn and dropout', 'Dropout with 0.2', 'Dropout with 0.5', 'Dropout with 0.8', 'BN'], loc='upper right') plt.grid(True) plt.show()
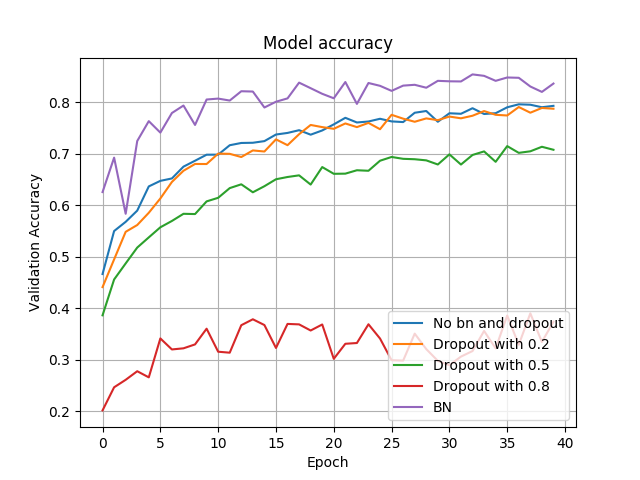
各模型的验证准确率如下图:
各模型的验证损失率如下:
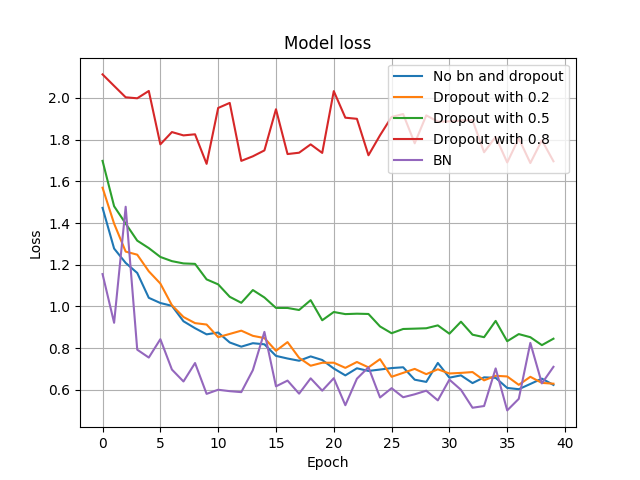
由上图可知,Dropout在不同概率下,其表现差异较大,相对来说,Dropout with 0.2的表现接近于 No bn and dropout(可以理解为Dropout的keep-prob为1的版本)。总体来说,BN在准确率和损失率上表现要优于Dropout,比如准确率上BN能达到85%,而Dropout接近为79%。
五、结论
无论是理论上的分析,还是现代深度模型的演变,或者是实验的结果,BN技术已显示出其优于Dropout的正则化效果,我们也是时候放弃Dropout,投入BN的怀抱了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号